一、Spring AI MCP
MCP 由 Anthropic 推出的一种开放标准协议,旨在统一大模型(LLM)与外部数据源和工具之间的通信方式。通过 MCP 协议,开发者可以更高效地实现 AI 模型与外部资源的集成,从而提升应用的智能化和上下文感知能力。现在关于MCP的介绍文章也非常多,这里就不过多介绍了。
而 Spring AI MCP 则是基于 Spring AI 集成扩展了 MCP Java SDK,让开发者在 Spring 体系下可以快速开发 MCP Server 端或 MCP Client 端。另外官方将 Function Calling 模式给标记 Deprecated 了,说实话动作确实快:

MCP 官方文档:
Spring AI MCP 文档
https://docs.spring.io/spring-ai/reference/api/mcp/mcp-overview.html
本文基于 Spring AI MCP 实现 MCP Server 端包括三个 MCP Tool ,分别是 获取所有可用的表名、根据表名获取Schema、执行SQL。MCP Client 端使用 Cline 工具进行集成,以及和大模型的交互。
MCP调用执行效果如下所示(实验表结构后面内容中已提供):
首先发起问题:现在的用户数是多少
大模型首先调用 MCP Server 获取所有可用的表名:

根据表名判断出需要使用的表后,自动再次调用 MCP Server 获取表的 Schema :
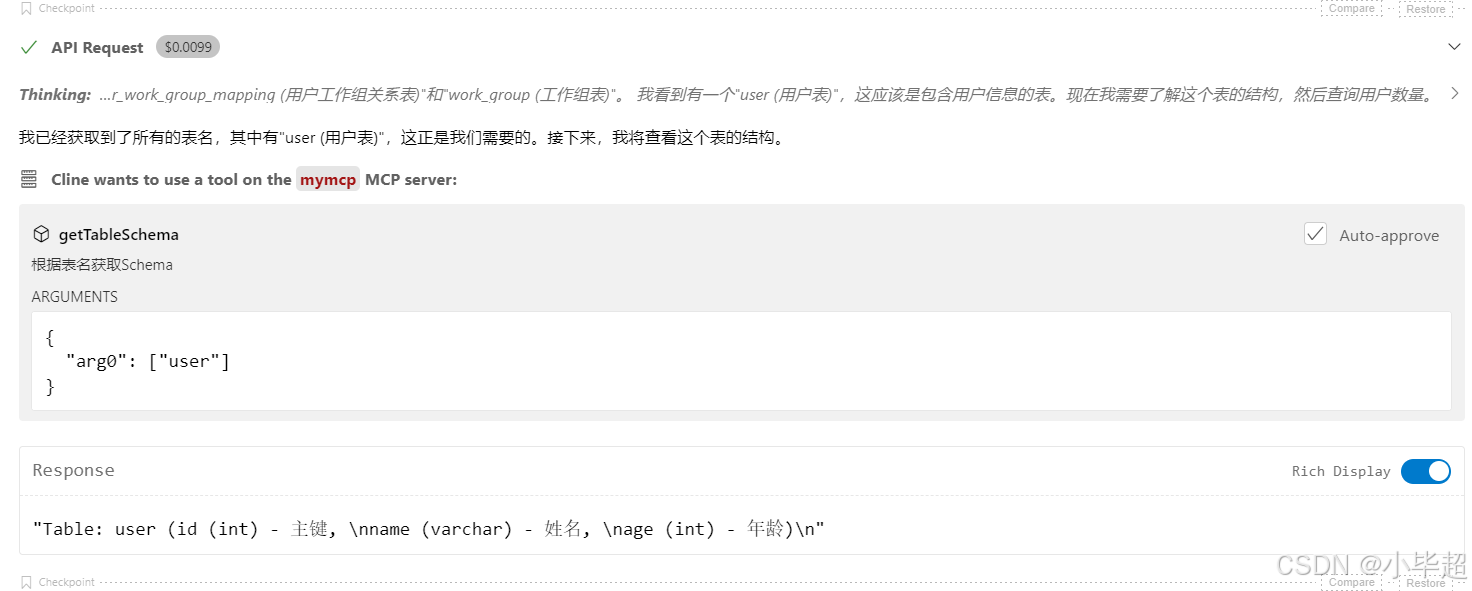
根据 Schema 生成 SQL ,再次调用 MCP Server 执行 SQL。
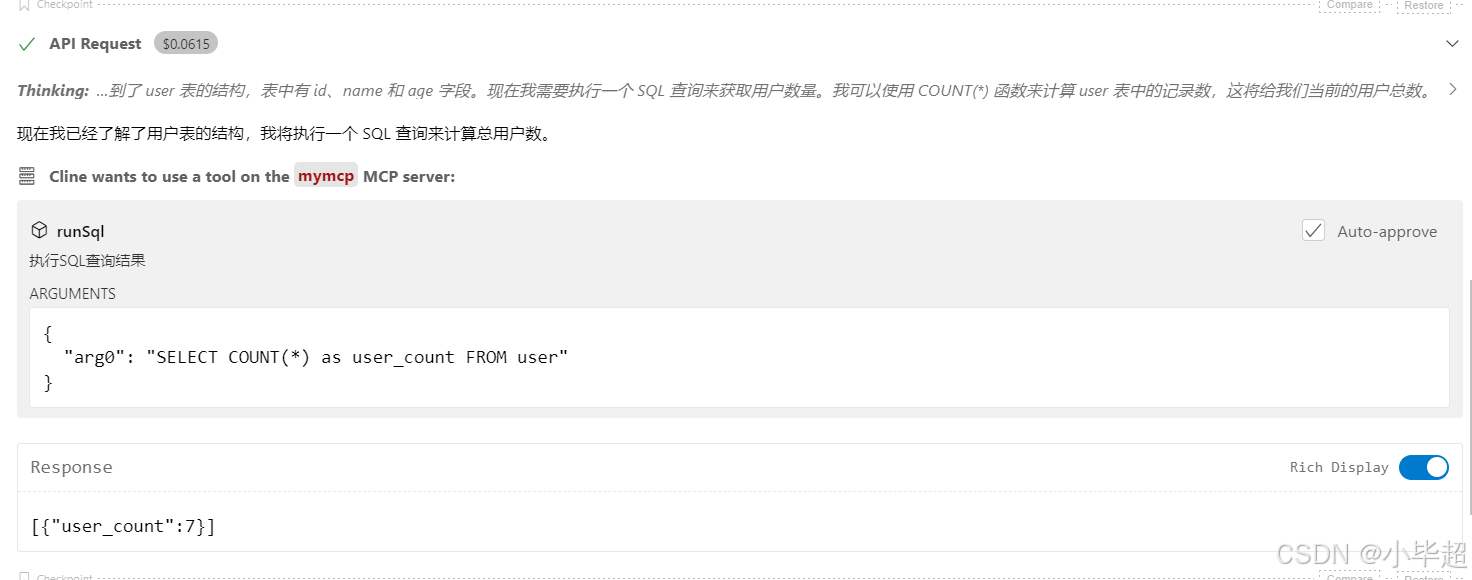
根据拿到的执行结果生成回答:
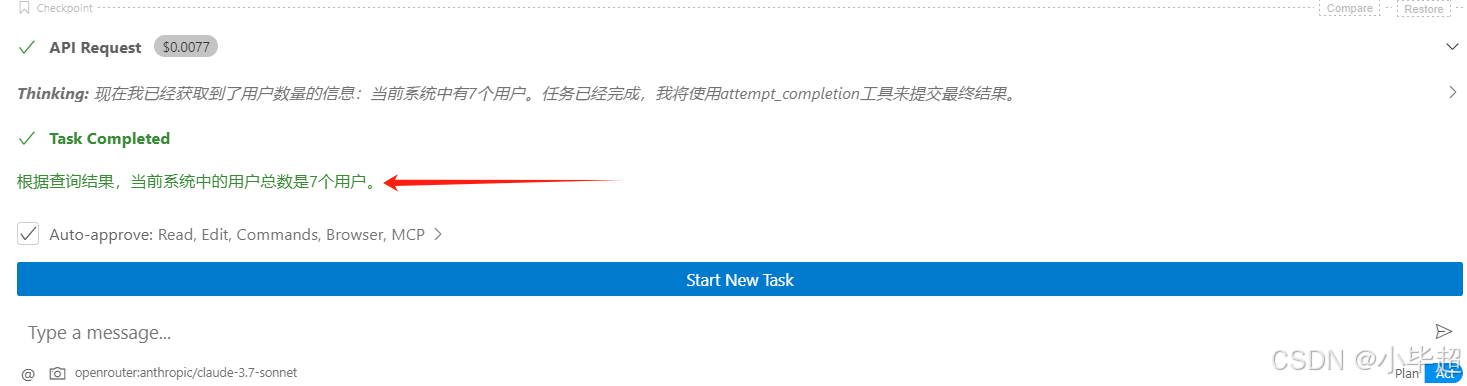
下面开始上述效果的实现过程。
二、准备MySQL表结构及测试数据
用户表
CREATE TABLE `user` (
`id` int NOT NULL AUTO_INCREMENT COMMENT '主键',
`name` varchar(255) DEFAULT NULL COMMENT '姓名',
`age` int DEFAULT NULL COMMENT '年龄',
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=8 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci COMMENT='用户表';
写入测试数据:
INSERT INTO `user`(`id`, `name`, `age`) VALUES (1, 'zhangsan', 20);
INSERT INTO `user`(`id`, `name`, `age`) VALUES (2, 'lisi', 60);
INSERT INTO `user`(`id`, `name`, `age`) VALUES (3, 'wangwu', 30);
INSERT INTO `user`(`id`, `name`, `age`) VALUES (4, 'zhaoliu', 31);
INSERT INTO `user`(`id`, `name`, `age`) VALUES (5, 'xiaoming', 35);
INSERT INTO `user`(`id`, `name`, `age`) VALUES (6, 'xiaohong', 25);
INSERT INTO `user`(`id`, `name`, `age`) VALUES (7, 'xiaolan', 40);
角色表
CREATE TABLE `role` (
`id` int NOT NULL AUTO_INCREMENT COMMENT '主键',
`role` varchar(255) DEFAULT NULL COMMENT '角色名',
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=6 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci COMMENT='角色表';
写入测试数据:
INSERT INTO `role`(`id`, `role`) VALUES (1, 'admin');
INSERT INTO `role`(`id`, `role`) VALUES (2, 'common');
INSERT INTO `role`(`id`, `role`) VALUES (3, 'role1');
INSERT INTO `role`(`id`, `role`) VALUES (4, 'role2');
INSERT INTO `role`(`id`, `role`) VALUES (5, 'role3');
工作组表:
CREATE TABLE `work_group` (
`id` int NOT NULL AUTO_INCREMENT COMMENT '主键',
`group` varchar(255) DEFAULT NULL COMMENT '工作组',
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=5 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci COMMENT='工作组表';
写入测试数据:
INSERT INTO `work_group`(`id`, `group`) VALUES (1, 'A');
INSERT INTO `work_group`(`id`, `group`) VALUES (2, 'B');
INSERT INTO `work_group`(`id`, `group`) VALUES (3, 'C');
INSERT INTO `work_group`(`id`, `group`) VALUES (4, 'E');
用户角色关系表
CREATE TABLE `user_role_mapping` (
`id` int NOT NULL AUTO_INCREMENT COMMENT '主键ID',
`user_id` int DEFAULT NULL COMMENT '用户ID',
`role_id` int DEFAULT NULL COMMENT '角色ID',
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=11 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci COMMENT='用户角色关系表';
写入测试数据:
INSERT INTO `user_role_mapping`(`id`, `user_id`, `role_id`) VALUES (1, 1, 1);
INSERT INTO `user_role_mapping`(`id`, `user_id`, `role_id`) VALUES (2, 1, 2);
INSERT INTO `user_role_mapping`(`id`, `user_id`, `role_id`) VALUES (3, 1, 3);
INSERT INTO `user_role_mapping`(`id`, `user_id`, `role_id`) VALUES (4, 2, 4);
INSERT INTO `user_role_mapping`(`id`, `user_id`, `role_id`) VALUES (5, 2, 5);
INSERT INTO `user_role_mapping`(`id`, `user_id`, `role_id`) VALUES (6, 3, 2);
INSERT INTO `user_role_mapping`(`id`, `user_id`, `role_id`) VALUES (7, 4, 2);
INSERT INTO `user_role_mapping`(`id`, `user_id`, `role_id`) VALUES (8, 5, 2);
INSERT INTO `user_role_mapping`(`id`, `user_id`, `role_id`) VALUES (9, 6, 2);
INSERT INTO `user_role_mapping`(`id`, `user_id`, `role_id`) VALUES (10, 7, 5);
用户工作组关系表
CREATE TABLE `user_work_group_mapping` (
`id` int NOT NULL AUTO_INCREMENT COMMENT '主键',
`user_id` int DEFAULT NULL COMMENT '用户ID',
`group_id` int DEFAULT NULL COMMENT '工作组ID',
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=15 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci COMMENT='用户工作组关系表';
写入测试数据:
INSERT INTO `user_work_group_mapping`(`id`, `user_id`, `group_id`) VALUES (1, 1, 1);
INSERT INTO `user_work_group_mapping`(`id`, `user_id`, `group_id`) VALUES (2, 1, 2);
INSERT INTO `user_work_group_mapping`(`id`, `user_id`, `group_id`) VALUES (3, 1, 3);
INSERT INTO `user_work_group_mapping`(`id`, `user_id`, `group_id`) VALUES (4, 2, 1);
INSERT INTO `user_work_group_mapping`(`id`, `user_id`, `group_id`) VALUES (5, 2, 2);
INSERT INTO `user_work_group_mapping`(`id`, `user_id`, `group_id`) VALUES (6, 2, 3);
INSERT INTO `user_work_group_mapping`(`id`, `user_id`, `group_id`) VALUES (7, 3, 2);
INSERT INTO `user_work_group_mapping`(`id`, `user_id`, `group_id`) VALUES (8, 3, 3);
INSERT INTO `user_work_group_mapping`(`id`, `user_id`, `group_id`) VALUES (9, 4, 1);
INSERT INTO `user_work_group_mapping`(`id`, `user_id`, `group_id`) VALUES (10, 4, 2);
INSERT INTO `user_work_group_mapping`(`id`, `user_id`, `group_id`) VALUES (11, 5, 2);
INSERT INTO `user_work_group_mapping`(`id`, `user_id`, `group_id`) VALUES (12, 5, 4);
INSERT INTO `user_work_group_mapping`(`id`, `user_id`, `group_id`) VALUES (13, 6, 3);
INSERT INTO `user_work_group_mapping`(`id`, `user_id`, `group_id`) VALUES (14, 7, 2);
三、Spring AI MCP Server 搭建
首先创建 SpringBoot 项目。注意:SpringBoot 版本需要 3.x 以上,jdk 版本 17 及以上。
在 pom 中加入 spring-ai-mcp-server-spring-boot-starter 的依赖,整体 pom 如下:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.example</groupId>
<artifactId>mcp-demo</artifactId>
<version>0.0.1-SNAPSHOT</version>
<name>mcp-demo</name>
<description>mcp-demo</description>
<properties>
<java.version>17</java.version>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<project.reporting.outputEncoding>UTF-8</project.reporting.outputEncoding>
<spring-boot.version>3.4.2</spring-boot.version>
<spring-ai.version>1.0.0-SNAPSHOT</spring-ai.version>
</properties>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-mcp-server-spring-boot-starter</artifactId>
<version>${spring-ai.version}</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.22</version>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid</artifactId>
<version>1.1.6</version>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-jdbc</artifactId>
</dependency>
</dependencies>
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-dependencies</artifactId>
<version>${spring-boot.version}</version>
<type>pom</type>
<scope>import</scope>
</dependency>
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-bom</artifactId>
<version>${spring-ai.version}</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.8.1</version>
<configuration>
<source>17</source>
<target>17</target>
<encoding>UTF-8</encoding>
</configuration>
</plugin>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
<version>${spring-boot.version}</version>
<executions>
<execution>
<goals>
<goal>repackage</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
<repositories>
<repository>
<name>Central Portal Snapshots</name>
<id>central-portal-snapshots</id>
<url>https://central.sonatype.com/repository/maven-snapshots/</url>
<releases>
<enabled>false</enabled>
</releases>
<snapshots>
<enabled>true</enabled>
</snapshots>
</repository>
<repository>
<id>spring-milestones</id>
<name>Spring Milestones</name>
<url>https://repo.spring.io/milestone</url>
<snapshots>
<enabled>false</enabled>
</snapshots>
</repository>
<repository>
<id>spring-snapshots</id>
<name>Spring Snapshots</name>
<url>https://repo.spring.io/snapshot</url>
<releases>
<enabled>false</enabled>
</releases>
</repository>
</repositories>
</project>
application.yml 中加入数据库连接配置:
spring:
datasource:
url: jdbc:mysql://127.0.0.1:3306/langchain?useUnicode=true&characterEncoding=utf8&serverTimezone=GMT%2B8
type: com.alibaba.druid.pool.DruidDataSource
username: root
password: root
driver-class-name: com.mysql.cj.jdbc.Driver
创建三个 MCP Tool ,实现 获取可用表名、根据表名获取表结构、执行SQL 三个功能:
@Component
public class DBTool {
@Resource
private JdbcTemplate jdbcTemplate;
private final String sql = "SELECT TABLE_NAME, TABLE_COMMENT FROM INFORMATION_SCHEMA.TABLES WHERE TABLE_SCHEMA = 'langchain'";
private final String schemaSql = "SELECT COLUMN_NAME, DATA_TYPE, COLUMN_COMMENT FROM INFORMATION_SCHEMA.COLUMNS " +
"WHERE TABLE_SCHEMA = 'langchain' AND TABLE_NAME = ?";
@Tool(description = "获取所有可用的表名")
public List<String> getTables() {
List<Map<String, Object>> maps = jdbcTemplate.queryForList(sql);
return maps.stream().map(map -> {
String tableName = String.valueOf(map.get("TABLE_NAME"));
String tableComment = String.valueOf(map.get("TABLE_COMMENT"));
return tableName + " (" + tableComment + ")";
}).collect(Collectors.toList());
}
@Tool(description = "根据表名获取Schema")
public String getTableSchema(@ToolParam(description = "表名") List<String> tables) {
return tables.stream().filter(t -> !t.isBlank()).map(tableName -> {
List<Map<String, Object>> columns = jdbcTemplate.queryForList(schemaSql, tableName);
String tablePrompt = columns.stream().map(map -> {
String name = String.valueOf(map.get("COLUMN_NAME"));
String type = String.valueOf(map.get("DATA_TYPE"));
String comment = String.valueOf(map.get("COLUMN_COMMENT"));
return String.format("%s (%s) - %s", name, type, comment);
}).collect(Collectors.joining(", \n"));
return String.format("Table: %s (%s)\n", tableName, tablePrompt);
}).collect(Collectors.joining("\n"));
}
@Tool(description = "执行SQL查询结果")
public List<Map<String, Object>> runSql(@ToolParam(description = "sql") String sql) {
if (sql.contains("DELETE") || sql.contains("UPDATE") || sql.contains("INSERT")){
throw new RuntimeException("执行SQL仅限于查询语句!");
}
return jdbcTemplate.queryForList(sql);
}
}
注册 MCP Tools :
@Configuration
public class MCPConfig {
@Bean
public List<ToolCallback> tools(DBTool dbTool) {
return new java.util.ArrayList<>(List.of(ToolCallbacks.from(dbTool)));
}
}
到此 Java 端的开发就结束了,下面打包成 jar 包,为后续 Cline 使用:
mvn clean package
四、Cline 配置 MCP Server
使用 VsCode 打开 Cline ,点击右上角 MCP Server,然后选择 Installed ,点击 Configure MCP Server:
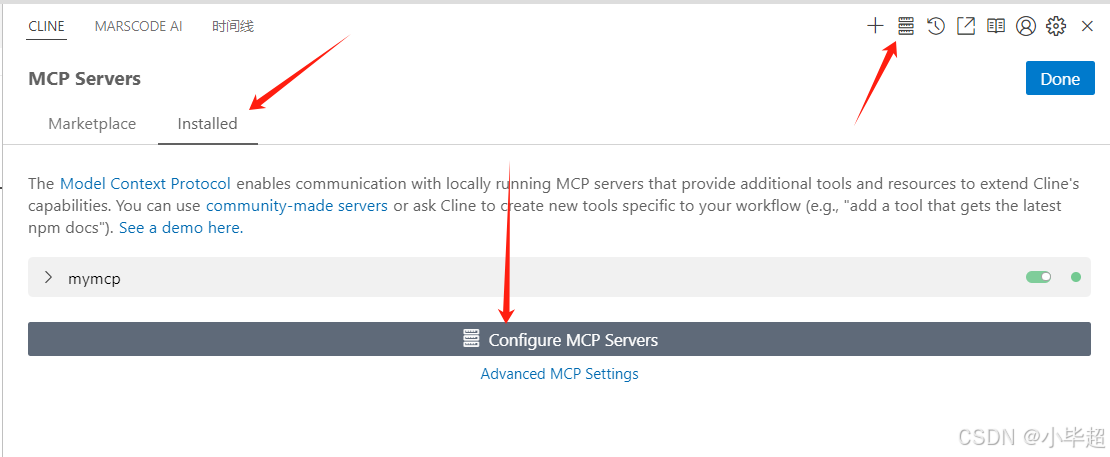
写入如下 json 配置,注意 jar 包的路径修改为你的真实地址:
{
"mcpServers": {
"mymcp": {
"command": "java",
"args": [
"-jar",
"D:/mcp-demo/target/mcp-demo-0.0.1-SNAPSHOT.jar"
],
"disabled": false
}
}
}
然后右侧可以看到 MCP Server 的连接状态,绿色表示连接正常,点开可以看到前面实现的 tools ,此外每个工具的 Auto-approve 建议打上勾,如果不打勾 Cline 调用 MCP Server 时会让我们手动确认一下是否执行:

另外还要在设置开启使用 MCP Server:
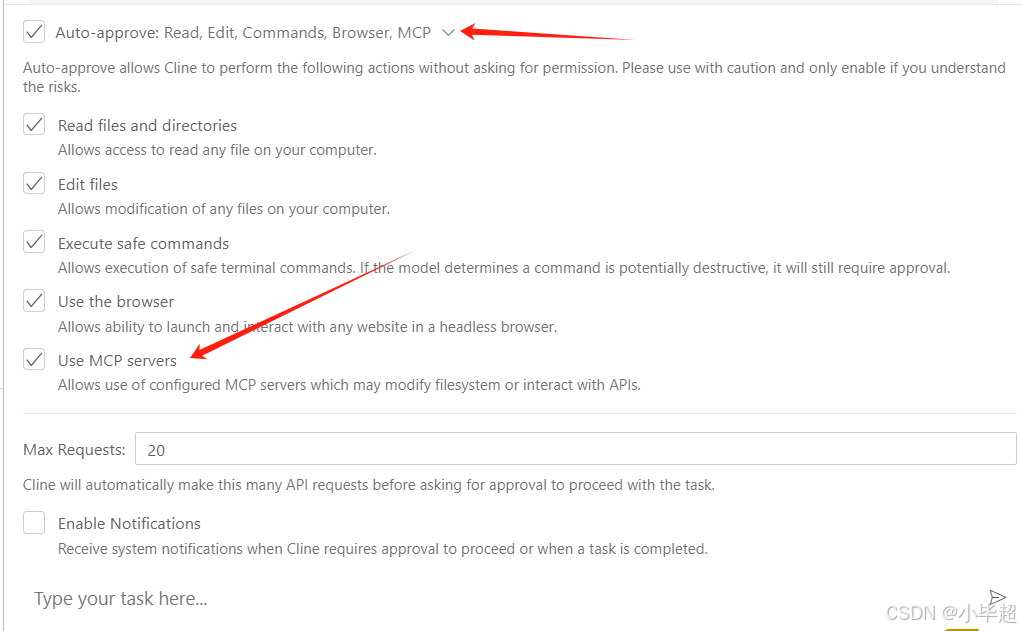
到此 Cline 端就配置完成了,可以在对话窗口测试效果。
五、测试
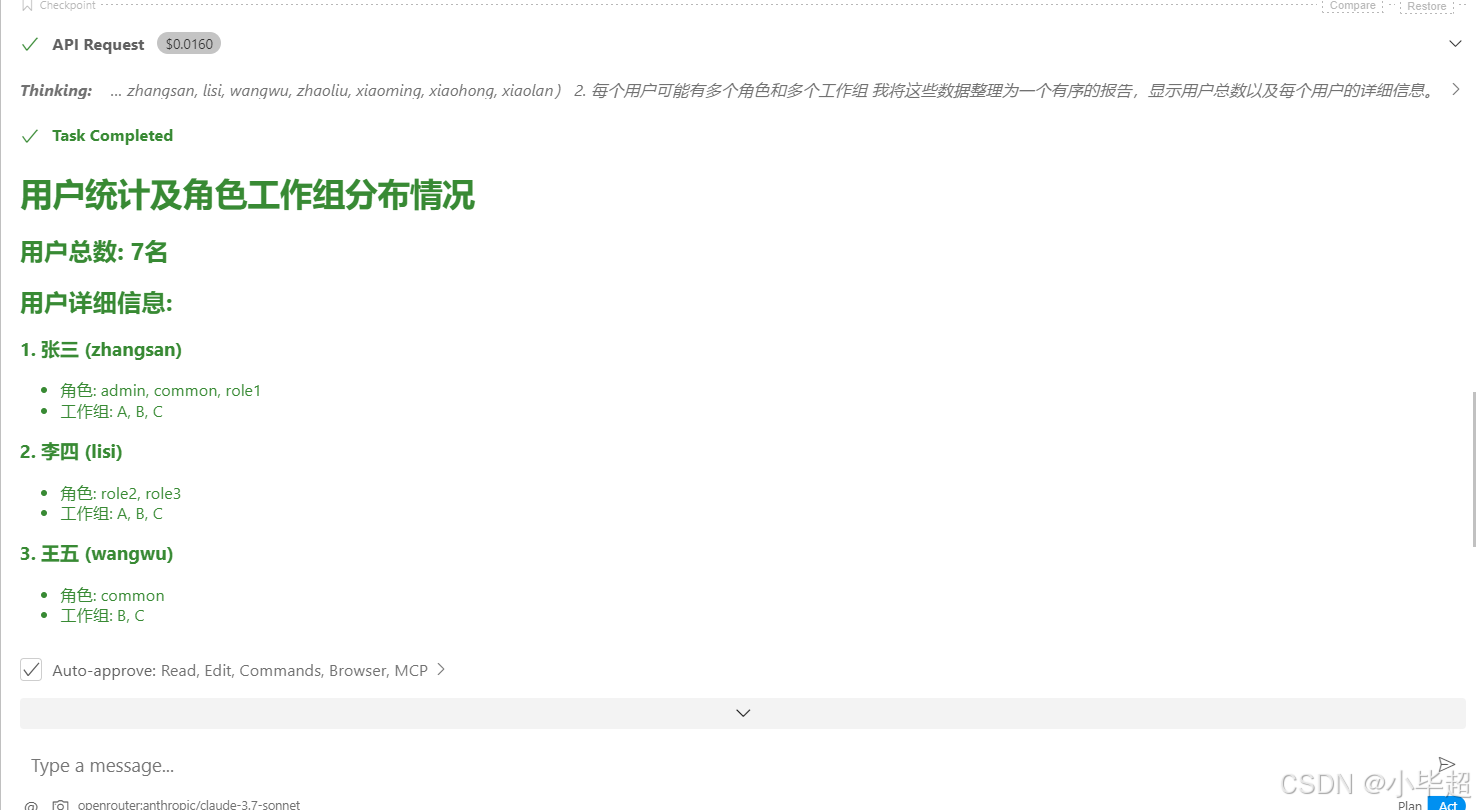
发起问题:现在的用户数,以及每个用户所属的角色和工作组
大模型首先调用 MCP Server 获取所有可用的表名:

然后根据表名判断需要使用哪些表,再次调用 MCP Server 获取表的 Schema :

根据 Schema 生成 SQL ,再次调用 MCP Server 执行 SQL。
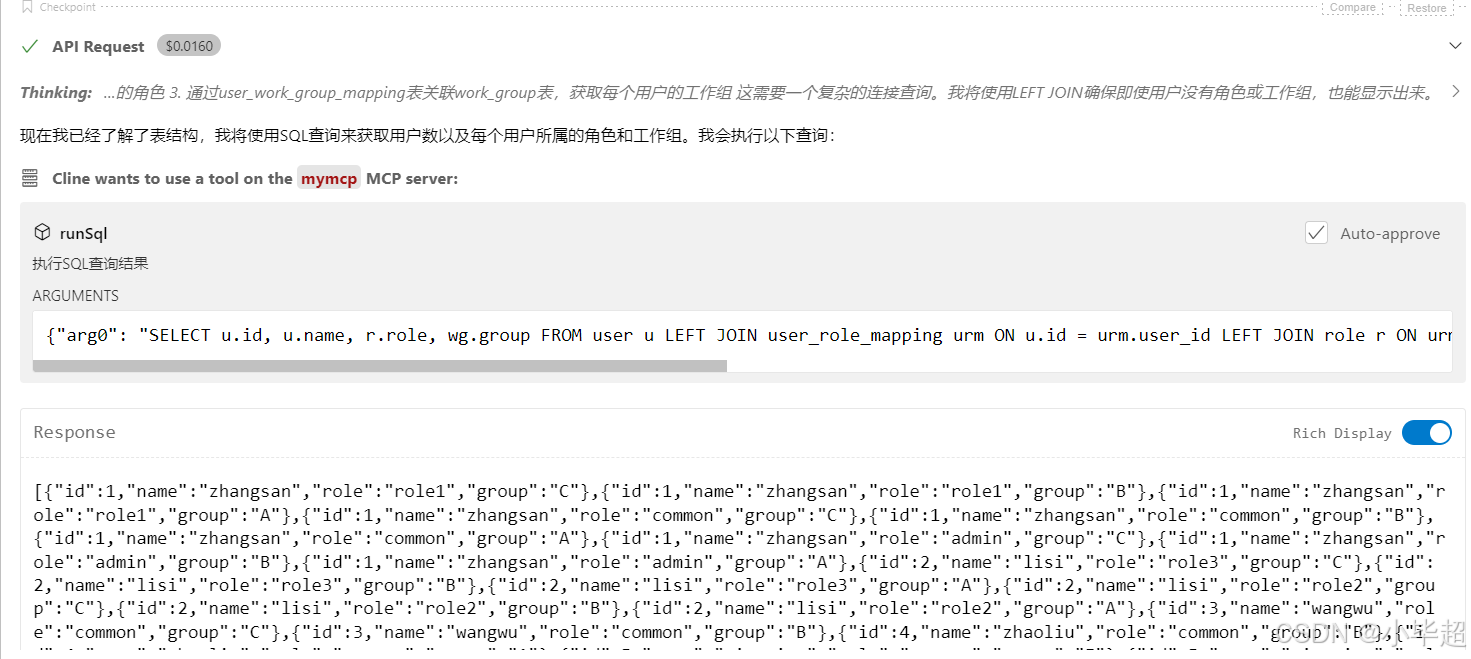
根据拿到的查询结果生成回答: