https://github.com/infiniflow/ragflow/blob/main/README_zh.md
DeepSeek搭建的本地知识库很呆?不符合自己的预期?看完这个视频你就明白了!这样部署吊打其他的本地部署!跟着教程来,不怕学不会!_哔哩哔哩_bilibili
大模型幻觉问题
大模型幻觉问题是指大模型生成的内容**看似合理,但实际上与客观事实不符或与用户指令、上下文不一致的现象**。以下是对大模型幻觉问题的具体解释:
表现形式
- 事实性幻觉
- 事实不一致:模型生成的内容与现实世界已有的信息相互矛盾。例如,将历史事件的发生时间记错,或者把某个人物的主要成就张冠李戴等。
- 事实捏造:模型自信地宣称一些不存在的事实,而不是表明“不知道”。比如虚构某本不存在的书籍对某个文物有特别解读等情况。
- 忠实性幻觉
- 指令不一致:模型输出的内容偏离了用户给出的指令要求。例如用户让总结特定时间的新闻,模型却给出其他时间的内容。
- 上下文不一致:生成的内容与之前给定的上下文信息不相符,出现前后矛盾等情况。
- 逻辑不一致:推理过程和最终答案之间缺乏合理的逻辑关系,导致得出的结论不合理。
产生原因
- 数据源问题
- 错误信息和偏见:训练数据集中本身存在错误的信息,或者数据存在一定的偏见,模型会学习并可能在输出时表现出这些错误和偏见。
- 领域知识缺陷:对于一些专业领域的复杂知识,训练数据可能覆盖不足,使得模型在处理相关问题时无法获取足够准确的信息。
- 过时的事实知识:数据如果没有及时更新,模型可能会依据过时的信息生成内容,导致与现实情况不符。
- 数据稀疏性:某些概念或事件在训练数据中出现的频率过低,模型缺乏足够的数据来学习,在生成相关内容时就容易出现错误或捏造。
- 训练过程问题
- 模型容量与数据不匹配:模型规模过大而训练数据不足,容易出现过拟合,使模型在面对新样本时产生幻觉。
- 优化算法的选择:不同优化算法会使模型学习到不同的特征和模式,部分算法可能导致模型在推理时过度自信,从而产生幻觉。
- 正则化不足:正则化技术可帮助模型泛化,若正则化不足,模型易过度拟合训练数据,在新数据上出现幻觉。
- 预训练与微调的不一致性:预训练模型可能在特定领域知识上有欠缺,微调过程若无法很好弥补,模型在特定任务中就可能生成幻觉内容。
- 推理问题
- 逻辑推理能力的局限:大模型在复杂的逻辑推理任务上存在不足,难以正确理解因果关系或逻辑链条,导致生成的内容不符合逻辑。
- 上下文理解的不足:模型可能无法充分理解输入的上下文信息,尤其是长序列或复杂的上下文,从而生成与上下文不一致的内容。
- 长尾分布问题:对于罕见或非常规的查询,由于在训练数据中很少出现,模型处理起来会有困难,容易在推理时产生幻觉。
- 反馈循环问题:模型生成的错误信息可能会作为输入再次被模型学习,进而强化错误信息,形成恶性循环。
影响
- 在实际应用中的危害:在医疗、法律、金融等对准确性要求极高的领域,如果大模型产生幻觉**,可能会导致严重的后果,如给出错误的医疗诊断建议、法律解读错误、金融风险评估失误等。**
- 对用户信任的影响:用户如果经常遇到大模型给出的错误或不合理内容,会降低对大模型的信任度,影响大模型的推广和应用。
解决方案
- 参数调整
- temperature参数调整:降低temperature值,减少模型输出的多样性,使其更倾向于选择概率最高的词汇,从而提高输出准确性,减少幻觉。
- 正则化技术:引入l1或l2正则化等正则化项,限制模型过拟合,增强泛化能力。
- 早停法(early stopping):在训练中监控验证集性能,当性能不再提升或下降时停止训练,防止过拟合。
- 提示工程
- 明确具体的提示:给模型提供具体、清晰的指令和上下文,减少其理解的模糊性。
- 链式思考(chain of thought)提示:在提示中包含多步推理示例,引导模型逐步思考和自我验证。
- 思维树(thought tree)提示:鼓励模型探索不同推理路径,并在每一步进行评估,避免其陷入单一推理路径。
- 外部知识库整合
- 检索增强生成(RAG****):结合检索组件和生成组件,利用检索到的数据辅助答案生成,提高响应的准确性和相关性。
- 知识图谱整合:将知识图谱与大模型结合,为模型提供结构化知识支持,减少捏造事实的情况。
- 实时数据源接入:对于需要最新信息的任务,接入实时数据源,确保模型基于最新数据生成内容。
模型微调与RAG
- 微调: 在已有的预训练模型基础上,再结合特定任务的数据集进一步对其进行训练,使得模型在这一领域中表现更好(考前复习);
- RAG: 在生成回答之前,通过信息检索从外部知识库中查找与问题相关的知识,增强生成过程中的信息来源,从
而提升生成的质量和准确性(考试带小抄)
- 共同点:都是为了赋予模型某个领域的特定知识,解决大模型的幻觉问题
RAG的原理
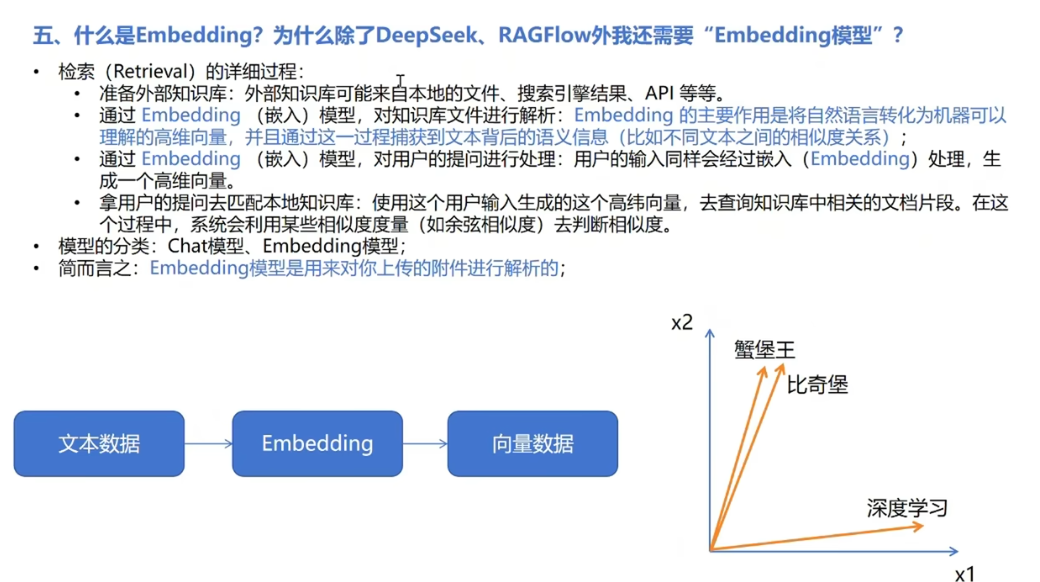
- 检索(Retrieval):当用户提出问题时,系统会从外部的知识库中检索出与用户输入相关的内容。
- 增强(Augmentation):系统将检索到的信息与用户的输入结合,扩展模型的上下文。然后再传给生成模型(也
就是Deepseek);
- 生成(Generation):生成模型基于增强后的输入生成最终的回答。由于这一回答参考了外部知识库中的内容,
因此更加准确可读。
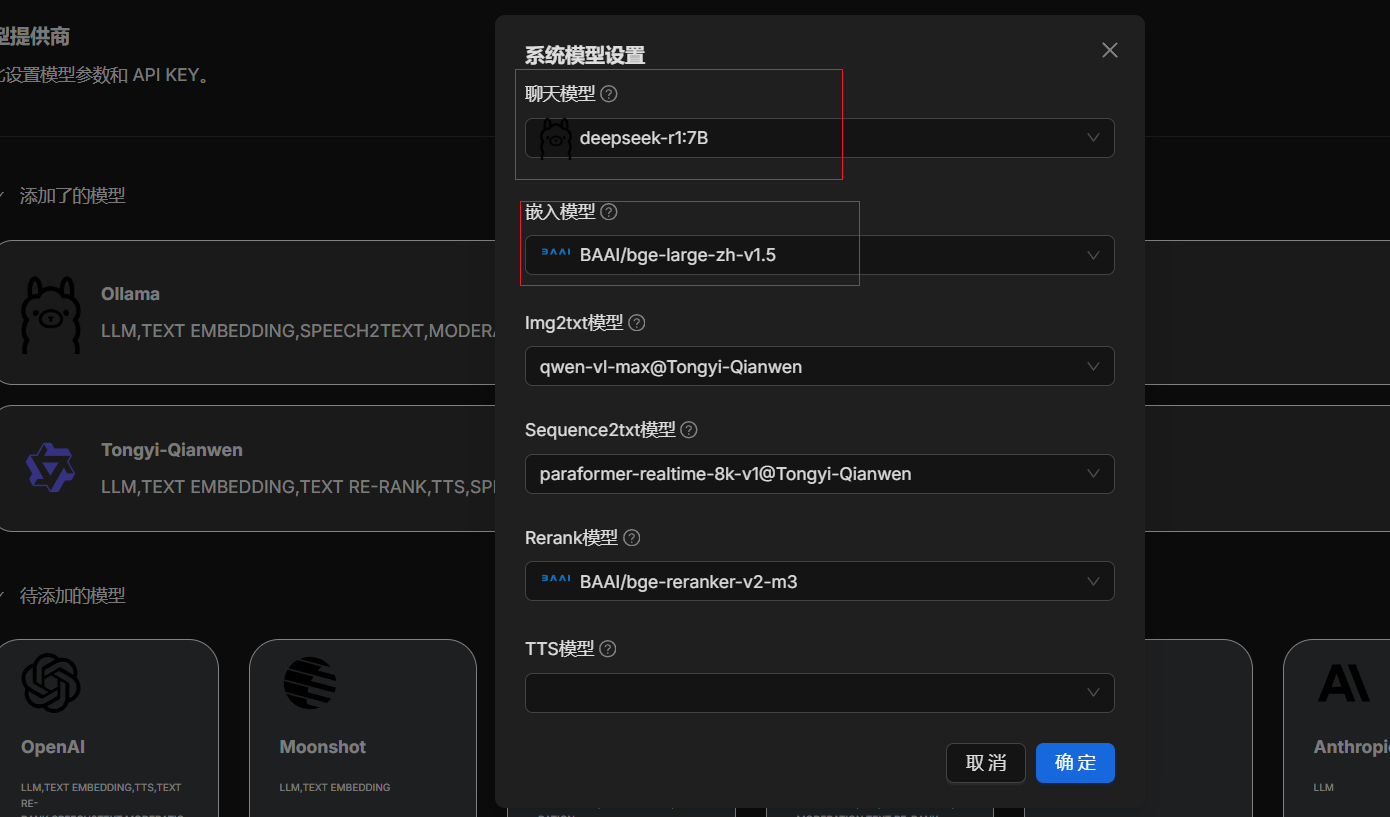
Embedding