前言
2025年春节期间,deepseek火爆全球——特别是deepseek V3和deepseek R1,其背后的MoE架构引发大量关注,考虑到MoE模型的重要性,特把MoE相关的模型独立成此文
同时因为本文,涉及到了多篇文章的改动,如下表格所示
《从Mistral 7B到MoE模型Mixtral 8x7B的全面解析:从原理分析到代码解读》
《七月论文审稿GPT第3.2版和第3.5版:通过paper-review数据集分别微调Mistral、gemma》
《一文通透DeepSeek V2:详解MoE、Math版提出的GRPO、V2版提出的MLA(改造Transformer注意力)》
《一文速览Gemma 2及其微调:早期paper-7方面review微调Gemma2》
1
后半部分Mixtral 8x7B 抽取出来,放到本文MoE模型的前半部分
2
标题变成了《一文速览Mistral 7B及其微调——我司论文审稿GPT第3.2版:微调Mistral 7B instruct 0.2》
微调Mistral部分抽取出来,放到《Mistral 7B文章》中
3
DeepSeekMoE部分 及 DeepSeek LLM部分 都放到本文MoE模型中
4
微调gemma部分放到此文《一文速览Gemma 2及其微调:早期paper-7方面review微调Gemma2》中
标题变成了《一文速览Gemma 2及其微调:从论文审稿GPT第3.5版(微调Gemma),到第5.2版(早期paper-7方面review微调Gemma2)》
5
相当于标题直接变成了
《一文速览DeepSeekMath及其提出的GRPO:Math模型的三阶段训练方式与群体相对策略优化GRPO》
把此文《一文通透DeepSeek V2:详解MoE、Math版提出的GRPO、V2版提出的MLA(改造Transformer注意力)》的Math版提出的GRPO部分独立成文,放到《七月论文审稿GPT第3.2版和第3.5版》中
第一部分首个开源MoE大模型Mixtral 8x7B
本文的前两部分一开始写于2023年12.23日,当时是属于此文《从Mistral 7B到MoE模型Mixtral 8x7B的全面解析:从原理分析到代码解读》的后半部分
当时的前言是
- 对于Mixtral 8x7B,OpenAI 团队一直对 GPT-4 的参数量和训练细节守口如瓶。早些时候,有人爆料 GPT-4 是采用了由 8 个专家模型组成的集成系统
后来又有传闻称,ChatGPT 也只是百亿参数级的模型(大概在 200 亿左右)- 传闻无从证明,但 Mixtral 8x7B 可能提供了一种「非常接近 GPT-4」的开源选项,特此,本文全面解析下:从原理解析到代码解读(在此文之前,尚没有资料扒得像本文这样如此之细)
1.1 Mixtral 8x7B的整体架构与模型细节
23年12月8日,Mistral AI 在 X 平台甩出一条磁力链接(当然,后来很多人打开一看,发现是接近 87 GB 的种子)

看上去,Mixtral 8x7B的架构此前传闻的GPT-4架构非常相似(很像传闻中GPT-4的同款方案),但是「缩小版」:
- 8 个专家总数,而不是 16 名(减少一半)
- 每个专家为 7B 参数,而不是 166B(减少 24 倍)
- 47B 总参数(估计)而不是 1.8T(减少 42 倍)
- 与原始 GPT-4 相同的 32K 上下文
在发布后 24 小时内,已经有开发者做出了在线体验网站:nateraw/mixtral-8x7b-32kseqlen – Run with an API on Replicate
两天后的23年12.11日,Mistral AI团队对外正式发布 Mixtral 8x7B,其在大多数基准测试中都优于 Llama 2 70B,推理速度提高了 6 倍,且它在大多数标准基准测试中匹配或优于 GPT3.5
为免歧义,补充说明下,Mistral AI团队目前总共发布了两个模型
- 今年10月发布的Mistral 7B
- 今年12月则发布的混合专家模型,称之为Mixtral 8x7B
特意注意,一个mis 一个mix,本质不同
而Mixtral 8x7B是一个纯解码器模型,下图是Mixtral的核心参数(可以把它和Mistral的核心参数做个对比)

-
其中前馈块从一组 8 个不同的参数组中进行选择(It is a decoder-only model where the feedforward block picks from a set of 8 distinct groups of parameters)
-
在每一层,对于每个token,路由器网络选择其中的两个组(“专家”)来处理token并通过组合相加得到它们的输出「At every layer, for every token, a router network chooses two of these groups (the “experts”) to process the token and combine their output additively」
相当于从下图的左侧变到了右侧(图源)
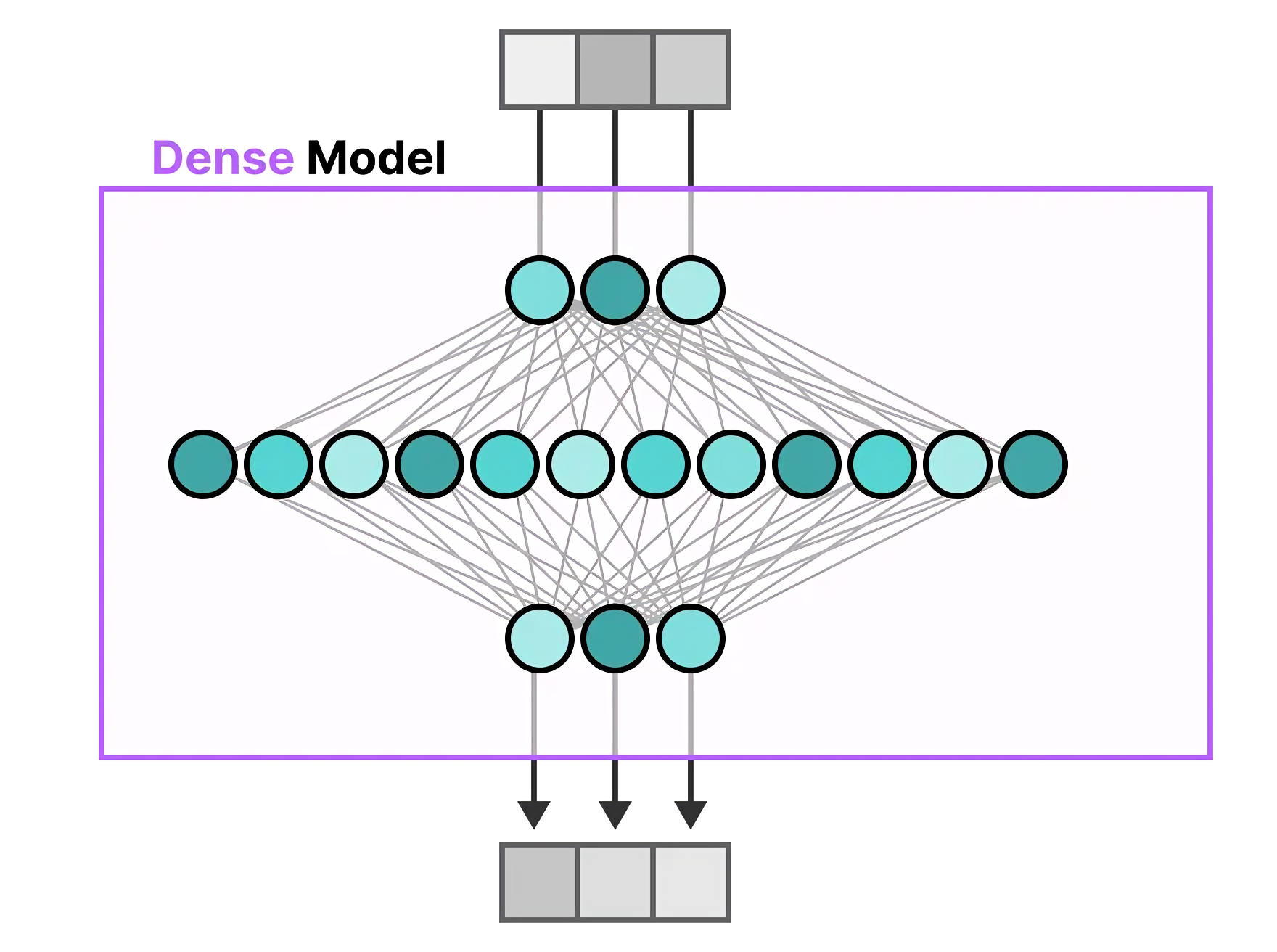
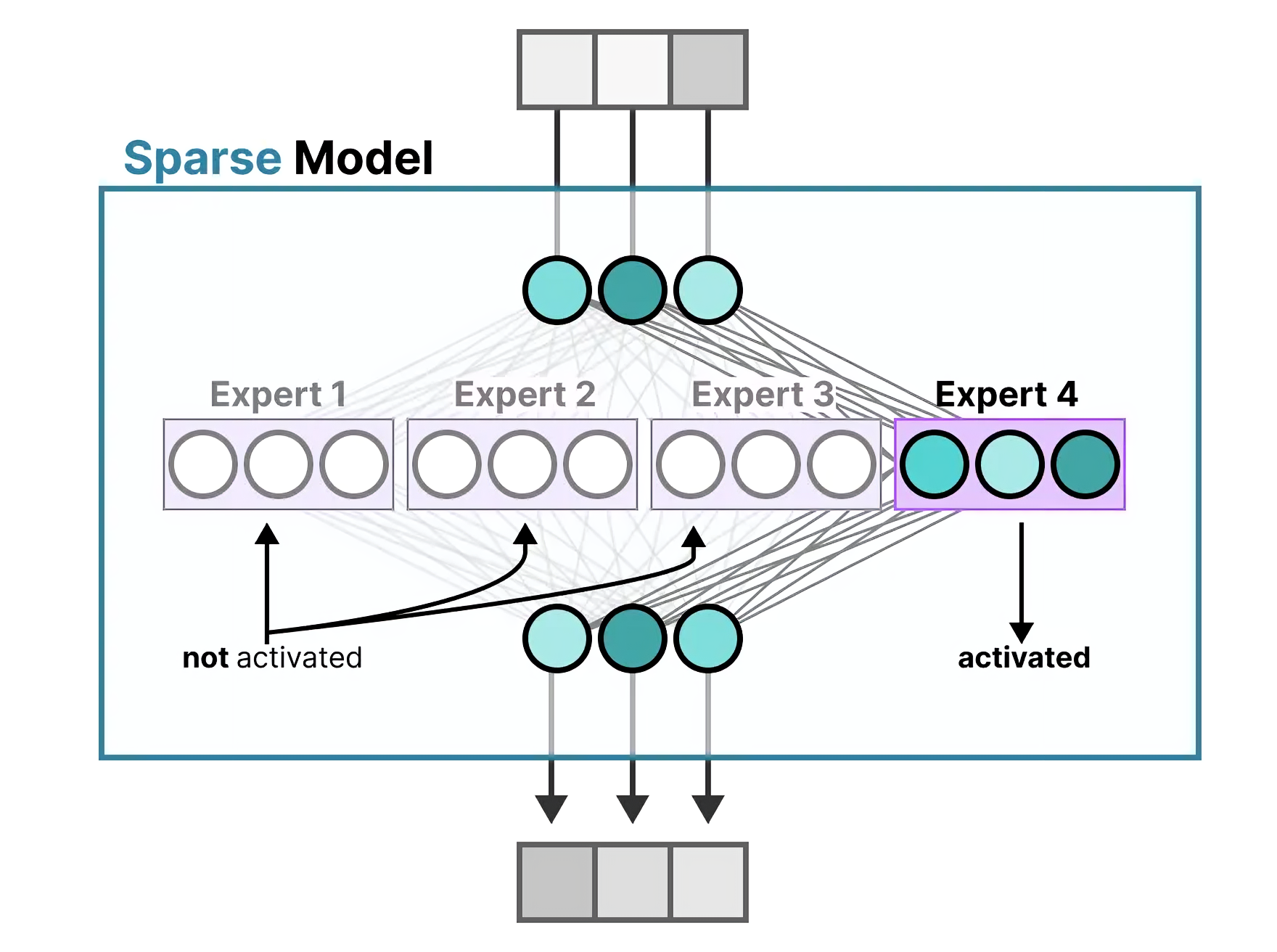
这点可能很多朋友不会特别在意,但你仔细品味下,你会发现大有天地,即:每个token 都由某两或三个专家负责完成,最后整个序列 则是由一系列「不同的两两专家」组合完成,下文还会详述该点
-
上下文长度达到32K
Mixtral is pretrained with multilingual data using a context size of 32k tokens
1.1.1 Mixtral 8x7B是一个稀疏的专家混合网络
如下图所示,传入模型的各个token在经过Attention层及残差连接后,进一步将由路由(Gating/Router)导向2个expert(FFN)中,之后对expert的输出进行加权聚合,再经过残差连接得到当前层的输出
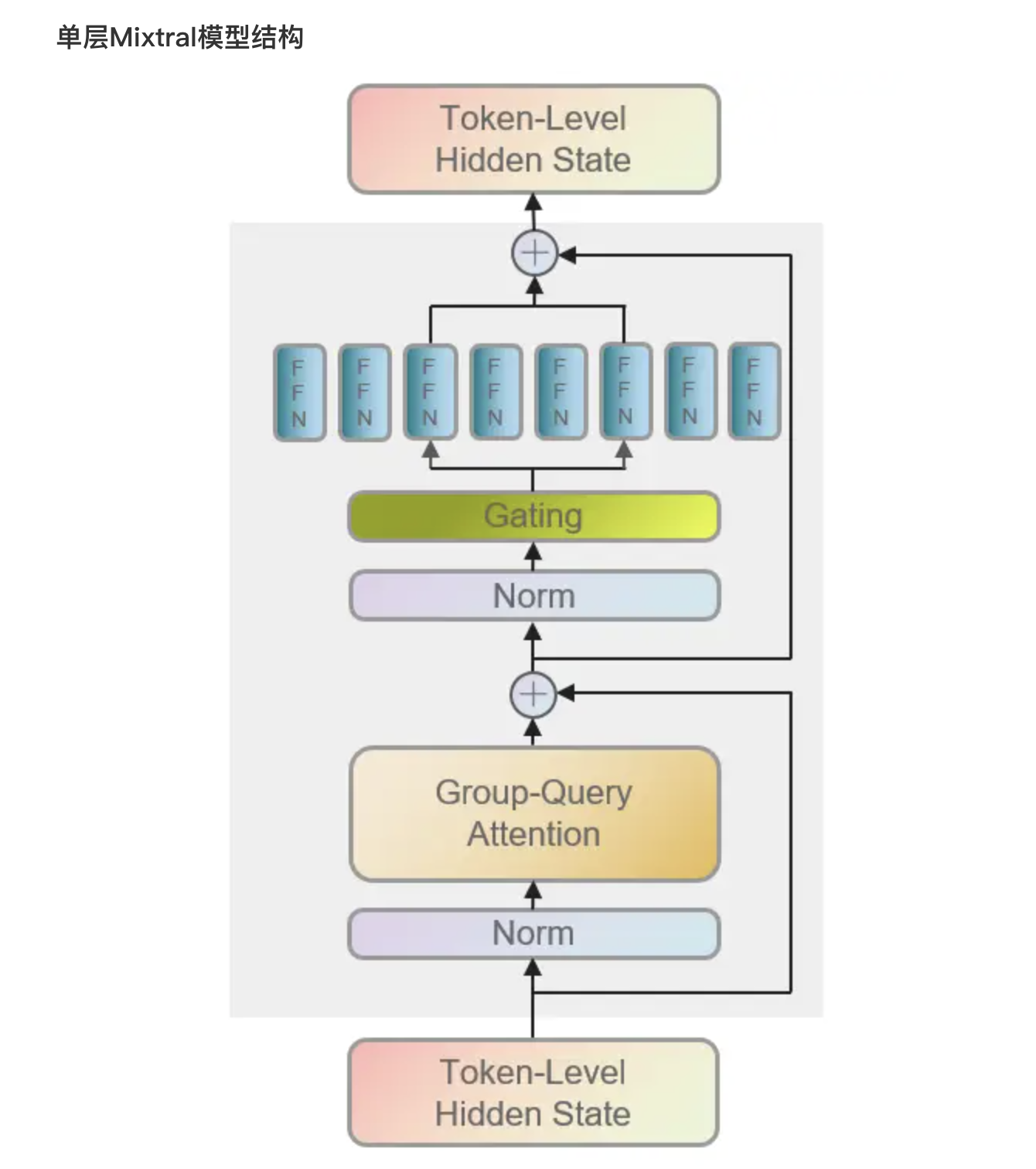
首先,即对于给定的输入,MoE模块的输出由“专家网络输出的加权和”决定,其中权重由“门控网络的输出”确定(The output of the MoE module for a given input x is determined by the weighted sum of the outputs of the expert networks, where the weights are given by the gating network’s output.)

-
当给定
个专家网络
,则专家层(expert layer)的输出为:
其中
表示第
个专家的门控gating网络的n维输出(denotes the n-dimensional output of the gating network for the i-th expert)
是第
-
如果门控gating向量稀疏,可以避免计算门为零的专家输出(If the gating vector is sparse, we can avoid computing the outputs of experts whose gates are zero)
且有多种实现G(x)的可选方法,但一种简单且高性能的方法是通过对线性层的Top-K logits进行softmax(but a simple and performant one is implemented by taking the softmax over the Top-K logits of a linear layer [28])
其中
如果_在logits的top-K坐标
中,则
,否则
_
_即where举个例子(例子来源于此),将输入(x)乘以路由器权重矩阵(W)——对应于上面公式中的
_
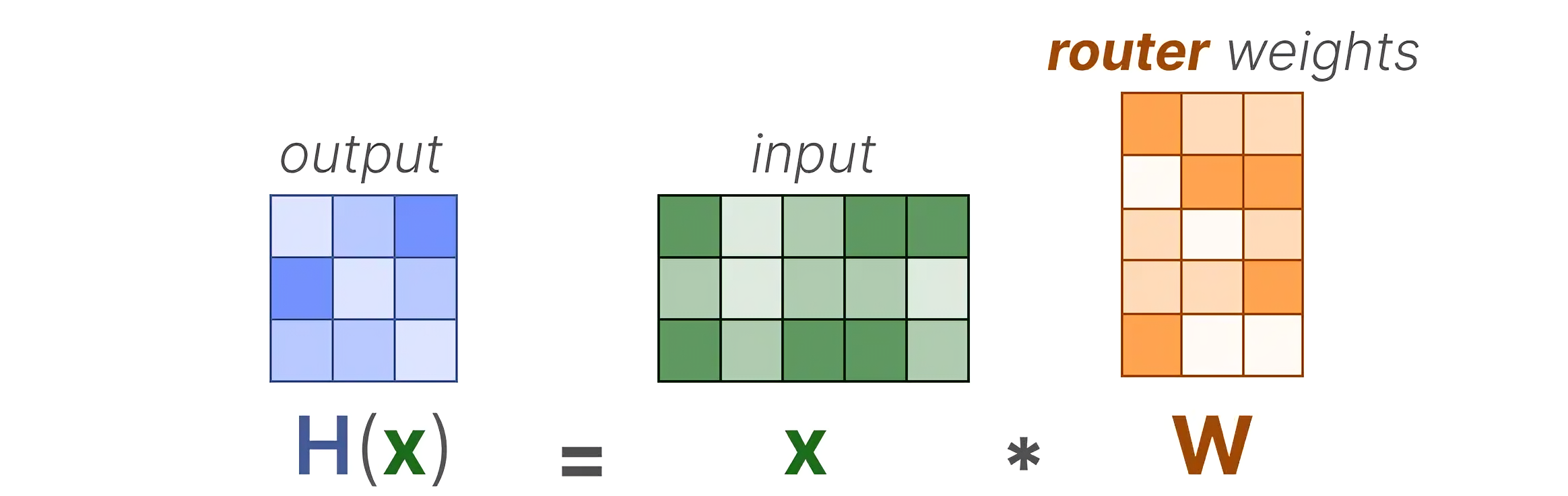
然后,在输出上应用SoftMax来为每个专家创建概率分布G(x):路由器使用此概率分布为给定的输入选择最佳匹配的专家——对应于上面的公式__

再其次,将每个选定的专家__G(x)与每个路由器的输出E(x)相乘,并对结果求和——对应于上面的公式
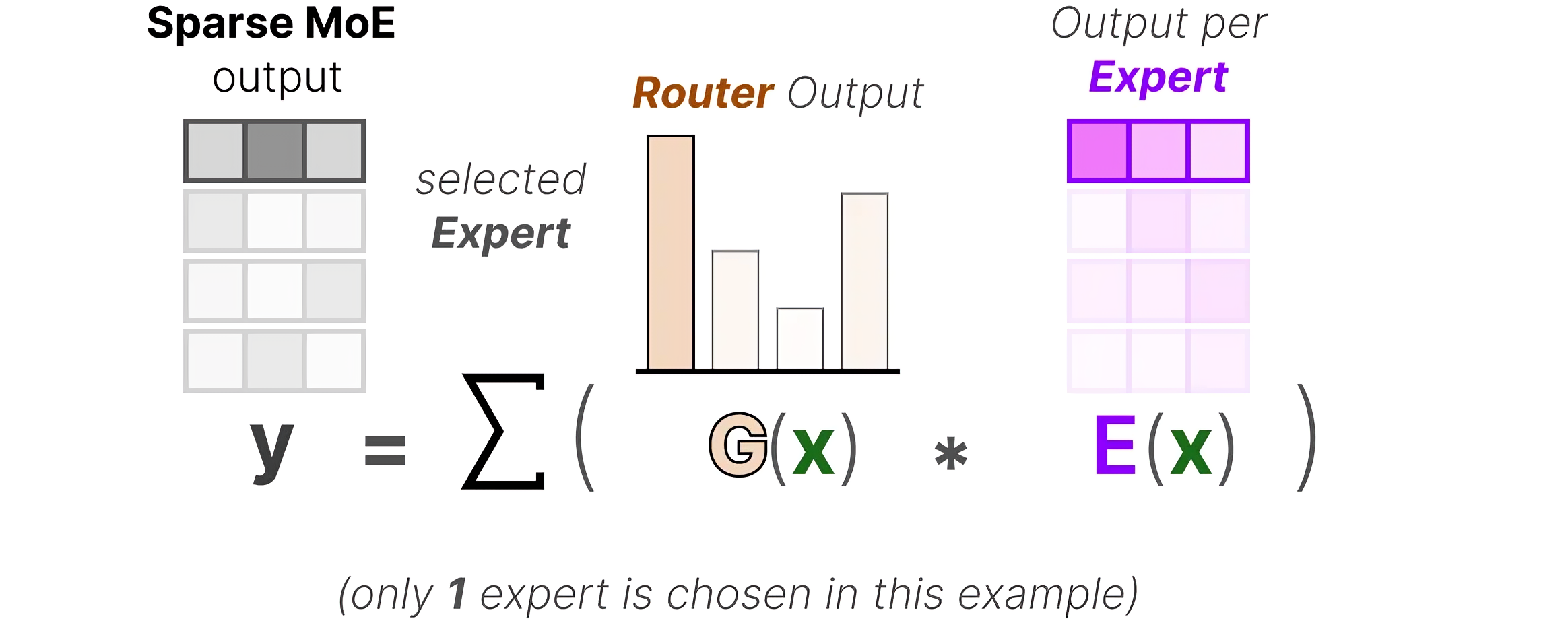
最后,上述整个流程如下所示「如下图左侧所示,当G(x)的权重结果计算出来后,根据所得权重结果选择4个专家中的最左边那个,然后将G(x)与最左边专家的输出结果E(x)相乘,得到 y 」

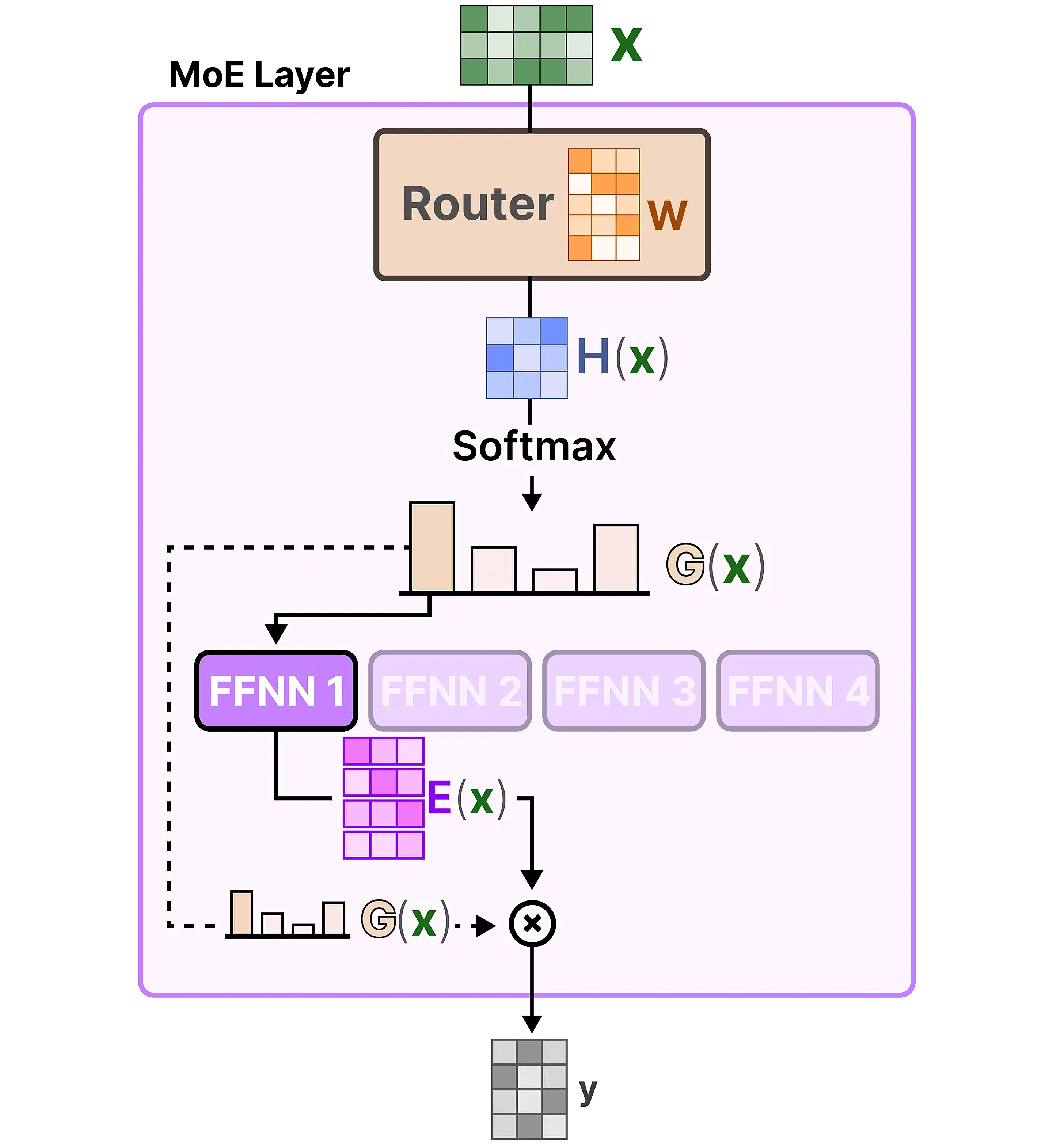
-
至于每个token所使用的专家数量
是可调的参数
当保持
The value of K – the number of experts