文章目录
前言
近期在上南方科技大学何炳生老师的数值分析课程时,学习了解线性方程组的三种迭代方法,即:雅克比(Jacobi)迭代;高斯-塞德尔(Gauss-Seidel)迭代以及超松弛(SOR)迭代。并按要求使用MATLAB对这三种迭代方法进行了仿真设计。通过仿真设计也对这三种迭代法有了一定的认识,希望通过此贴以通俗的形式分享自己对于这类方法的理解,文中一些不够准确或错误的表达,还望大家指证。
一、解线性方程组的方法
求解线性方程组在很多工程领域都是很重要的内容,无论是机器学习也好亦或是其他的工程优化也好。通常来说,对于一个线性方程组 A X = b AX=b AX=b,对其的数值解法一般有两类:直接法和迭代法。
- 直接法实际就是通过使用各种线性代数知识在有限步算数运算,计算出该线性方程组精确解的办法(在计算过程中没有舍入误差的情况下),例如本科线性代数中的克拉默法则以及考研线性代数大题最常用的高斯消去法。
- 迭代法则是用某种极限过程去逐步逼近线性方程组的精确解的方法,也就是最后得到的是一个无限逼近与精确解的近似解,这个解只有在迭代无穷次下可以看做是精确解(一般有限步内得不到精确解)。
对于熟悉直接法的人而言,可以发现这种方法的求解过程在计算机下编程实际是较为复杂的,例如:高斯消去法常规的求解过程就要求先构建增广矩阵,而后做初等行变换消元将系数矩阵化为一个上三角矩阵,然后再回代求解出解向量 X X X,并且从计算量而言也是较为复杂的,尽管之后变形出了例如三角分解(LU分解)这样的变形解法,但从编程的角度考虑依然是不直观的。
而迭代法,其基本思想是将线性方程组转化为便于迭代的等价方程组,然后基于初始 X X X值即 X = x i ( 0 ) = 0 ( i = 1 , 2 , 3 , . . . n ) X = x_{i}^{(0)} = 0 (i = 1,2,3,...n) X=xi(0)=0(i=1,2,3,...n),然后按照一定的计算规则,不断地修正得到新的解 X X X,最终得到满足精度要求的方程组的近似解。这显然是更加直观且易于编程设计的一种方法。而这其中就有三种最常见的迭代方式,即:
- 雅克比(Jacobi)迭代
- 高斯-塞德尔(Gauss-Seidel)迭代
- 超松弛(SOR)迭代
二、解线性方程组的迭代法及其代码实现
1. 迭代法的收敛性
在直接引入三种迭代法及其MATLAB实现之前,需要先提到一点就是迭代法的收敛性,简单的理解其实就是迭代法并不适用于所有线性方程组,即对于一类方程组迭代时会收敛,近似解会不断逼近精确解,但是对于另外一类方程组则会发散,近似解不断远离精确解。而决定迭代法是否收敛,是否可用于该方程组,主要需要考虑的其实就是系数矩阵 A A A。这里直接给出使上述三种迭代法收敛的充分条件:系数矩阵 A A A按行(或列)严格对角占优或满足弱对角占优不可约。
(由于本人能力有限,具体的关于于迭代法收敛的充要条件,请参照清华大学出版,李庆阳、王能超、易大义老师编的《数值分析》第五版内容)
2. 基本参数设置
基本参数:矩阵阶数,计算误差,最大迭代次数。其中计算误差和最大迭代次数是迭代终止的判断要求,达到精度或者迭代到最大次数时停止迭代并输出结果。此处对计算误差进行说明,当计算精度满足 m a x 1 ⩽ i ⩽ n ∣ x i ( k + 1 ) − x i ( k ) ∣ < e p s \mathop{max}\limits_{1\leqslant i\leqslant n}\left | x_{i}^{(k+1)} - x_{i}^{(k)}\right | < eps 1⩽i⩽nmax∣∣∣xi(k+1)−xi(k)∣∣∣<eps 时结束迭代。
%==基本参数
%矩阵阶数n
n = 4;
%计算误差
eps = 0.000005;
%最大迭代次数
Nmax = 10000;
矩阵设置:由于以下三种迭代法收敛的充分条件为系数矩阵A满足严格对角占优或按行(或列)满足若对角占优不可约,故在参数设置上设计了两种方法,为方便对比计算结果,之后采用的均是方法一所设置的矩阵。
方法一:手动输入系数矩阵 A A A及结果向量 b b b
% 方法一 : 自行设置矩阵
A = [-4,1,1,1;
1,-4,1,1;
1,1,-4,1;
1,1,1,-4];
B = [1,1,1,1];
方法二:根据设置的矩阵阶数,自动生成强对角占优矩阵
% 方法二:随机生成矩阵
% 系数矩阵(默认生成一个对角占优矩阵)
A = 100 * rand(n) - 50;
for i=1:n
A(i,i) = sum(abs(A(i,:)))+25 * rand(1);
end
%结果向量
B = 100 * rand([n 1]);
3. 雅克比(Jacobi)迭代
雅克比迭代实际是将系数矩阵A分解为了三个矩阵的组合,如下图
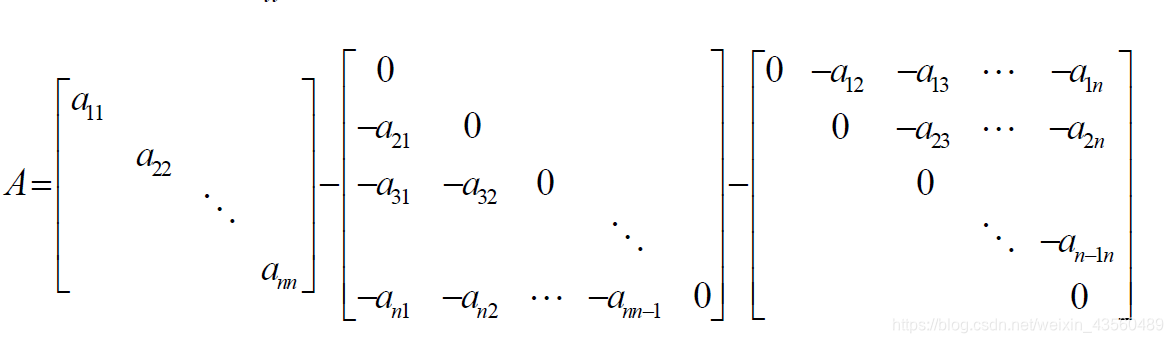
将其记做 A = D − L − U A = D-L-U A=D−L−U,则原方程组 A X = b AX=b AX=b 等价于 ( D − L − U ) X = b (D-L-U)X = b (D−L−U)X=b,即
D X = ( L + U ) X + b DX = (L+U)X+b DX=(L+U)X+b
因为 a i i ≠ 0 ( i = 1 , 2 , . . . n ) a_{ii}\neq 0 (i = 1,2,...n) aii=0(i=1,2,...n),故
X = D − 1 ( L + U ) X + D − 1 b X = D^{-1}(L+U)X+D^{-1}b X=D−1(L+U)X+D−1b
由此便可以得到一个迭代公式
X ( k + 1 ) = D − 1 ( L + U ) X ( k ) + D − 1 b X^{(k+1)}=D^{-1}(L+U)X^{(k)}+D^{-1}b X(k+1)=D−1(L+U)X(k)+D−1b
令 B = D − 1 ( L + U ) B = D^{-1}(L+U) B=D−1(L+U), f = D − 1 b f = D^{-1}b f=D−1b,即可得到雅克比迭代公式
X ( k + 1 ) = B X ( k ) + f X^{(k+1)}=BX^{(k)}+f X(k+1)=BX(k)+f
写成便于编程理解的形式即:
X i ( k + 1 ) = 1 a i i ( b i − ∑ j = 1 j ≠ i n a i j X j ( k ) ) X_{i}^{(k+1)}=\frac{1}{a_{ii}}(b_{i} - \sum\limits_{\mathop{j=1}\limits_{j\neq i}}^{n}a_{ij}X_{j}^{(k)}) Xi(k+1)=aii1(bi−j=ij=1∑naijXj(k))
代码:
x(n) = 0;
y(n) = 0;
count = 1;
while(1)
for i = 1:n
for j = 1:n
%j≠k时
if i ~= j
y(i) = y(i) + A(i,j)*x(j);
end
end
y(i)=( B(i) - y(i))/A(i,i);
end
if max(abs(x-y)) < eps
%c为将结果回带到方程组中求解的结果向量,以确认结果无误
c = A * y';
fprintf('迭代结束,次数%d,最终结果:\n',count);
disp(y);
disp(c);
break;
else
fprintf('第%d次迭代结果:\n',count);
disp(y)
end
if count == Nmax
c = A * y';
fprintf('超过最大迭代次数,迭代结束,最终结果:\n');
disp(y);
disp(c);
break;
end
count = count + 1;
x = y;
y(1: n) = 0;
end
仿真结果:

4. 高斯-塞德尔(Gauss-Seidel)迭代
在雅克比迭代中,我们可以看出,每一次迭代得到的新的解向量 X ( k + 1 ) X^{(k+1)} X(k+1)中的每一个元素均是由上一个解向量 X ( k ) X^{(k)} X(k)的所有元素计算得出,但实际上计算新的解向量 X ( k + 1 ) X^{(k+1)} X(k+1)的一个元素时,其前面的元素实际已经计算得出了,所以高斯-塞德尔(Gauss-Seidel)迭代的核心思想即:将本次迭代中前面已经计算出来的元素加入到迭代公式中,替代掉相对应的上一个解向量中的元素,从而实现加速收敛。
高斯-塞德尔(Gauss-Seidel)迭代迭代公式可以写作
X i ( k + 1 ) = 1 a i i ( b i − ∑ j = 1 i − 1 a i j X j ( k + 1 ) − ∑ j = i + 1 n a i j X j ( k ) ) X_{i}^{(k+1)}=\frac{1}{a_{ii}}(b_{i} - \sum\limits_{j = 1}^{i - 1}a_{ij}X_{j}^{(k+1)} - \sum\limits_{\mathop{j=i+1}}^{n}a_{ij}X_{j}^{(k)}) Xi(k+1)=aii1(bi−j=1∑i−1aijXj(k+1)−j=i+1∑naijXj(k))
代码:
x(n) = 0;
y(n) = 0;
count = 1;
%中间变量
x1(n) = 0;
x2(n) = 0;
while(1)
x1(1:n) = 0;
x2(1:n) = 0;
for i = 1:n
for j = 1: i-1
x1(i) =x1(i) + A(i,j) * y(j);
end
for k = i + 1 : n
x2(i) = x2(i) + A(i,k) * x(k);
end
y(i)=(B(i) - x1(i) - x2(i))/A(i,i);
end
if max(abs(x-y)) < eps
c = A * y';
fprintf('迭代结束,次数%d,最终结果:\n',count);
disp(y);
disp(c);
break;
else
fprintf('第%d次迭代结果:\n',count);
disp(y)
end
if count == Nmax
c = A * y';
fprintf('超过最大迭代次数,迭代结束,最终结果:\n');
disp(y);
disp(c);
break;
end
count = count + 1;
x = y;
end
仿真结果:

5. 超松弛(SOR)迭代
超松弛迭代法实际是在高斯-塞德尔迭代的基础上的一个加速方法,可以看做是带参数的高斯-塞德尔迭代,是求解大型稀疏矩阵方程组的有效方法,有着很广泛的应用,其核心思想为将高斯-塞德尔迭代求解出的新的解向量元素与上一个解向量中相对应的元素,做加权平均组合成一个全新的解向量的元素,这个全新的解向量即为超松弛迭代法的解,其中的权重被称为松弛因子
其具体计算公式如下:
- 用高斯-塞德尔迭代公式定义一个辅助量
X ~ i ( k + 1 ) = 1 a i i ( b i − ∑ j = 1 i − 1 a i j X j ( k + 1 ) − ∑ j = i + 1 n a i j X j ( k ) ) \widetilde{X}_{i}^{(k+1)}=\frac{1}{a_{ii}}(b_{i} - \sum\limits_{j = 1}^{i - 1}a_{ij}X_{j}^{(k+1)} - \sum\limits_{\mathop{j=i+1}}^{n}a_{ij}X_{j}^{(k)}) X i(k+1)=aii1(bi−j=1∑i−1aijXj(k+1)−j=i+1∑naijXj(k)) - 将 X i ( k + 1 ) X_{i}^{(k+1)} Xi(k+1)取做 X ~ i ( k + 1 ) \widetilde{X}_{i}^{(k+1)} X
i(k+1)与 X i ( k ) X_{i}^{(k)} Xi(k)的加权平均
X i ( k + 1 ) = ( 1 − ω ) X i ( k ) + ω X ~ i ( k + 1 ) X_{i}^{(k+1)}=(1-\omega )X_{i}^{(k)} + \omega\widetilde{X}_{i}^{(k+1)} Xi(k+1)=(1−ω)Xi(k)+ωX i(k+1)
即
X i ( k + 1 ) = ( 1 − ω ) X i ( k ) + ω a i i ( b i − ∑ j = 1 i − 1 a i j X j ( k + 1 ) − ∑ j = i + 1 n a i j X j ( k ) ) X_{i}^{(k+1)}=(1-\omega )X_{i}^{(k)} + \frac{\omega}{a_{ii}}(b_{i} - \sum\limits_{j = 1}^{i - 1}a_{ij}X_{j}^{(k+1)} - \sum\limits_{\mathop{j=i+1}}^{n}a_{ij}X_{j}^{(k)}) Xi(k+1)=(1−ω)Xi(k)+aiiω(bi−j=1∑i−1aijXj(k+1)−j=i+1∑naijXj(k))
式中的系数 ω \omega ω被称为松弛因子,当 ω = 1 \omega = 1 ω=1时即为高斯-塞德尔迭代,为了保证迭代过程收敛,要求 0 < ω < 2 0 < \omega<2 0<ω<2
当 0 < ω < 1 0 < \omega<1 0<ω<1时,是低松弛法;
当 1 < ω < 2 1 < \omega<2 1<ω<2时,是超松弛法;
代码:
x(n) = 0;
y(n) = 0;
count = 1;
%中间变量
x1(n) = 0;
x2(n) = 0;
%松弛因子w
w = 1.3;
while(1)
x1(1:n) = 0;
x2(1:n) = 0;
for i = 1:n
for j = 1: i-1
x1(i) =x1(i) + A(i,j) * y(j);
end
for k = i + 1 : n
x2(i) = x2(i) + A(i,k) * x(k);
end
temp = (B(i) - x1(i) - x2(i))/A(i,i);
y(i) = (1 - w)* x(i) + w * temp;
end
if max(abs(x-y)) < eps
c = A * y';
fprintf('迭代结束,次数%d,最终结果:\n',count);
disp(y);
disp(c);
break;
else
fprintf('第%d次迭代结果:\n',count);
disp(y)
end
if count == Nmax
c = A * y';
fprintf('超过最大迭代次数,迭代结束,最终结果:\n');
disp(y);
disp(c);
break;
end
count = count + 1;
x = y;
end
仿真结果:

总结
从结果上来看,对于所设置的系数矩阵A,要满足小数点后6位的精度要求,雅克比迭代法迭代次数39次;高斯赛德尔迭代法迭代次数22次;松弛因子为1.3时的SOR超松弛迭代法迭代12次。可见SOR迭代法是三种迭代法中收敛最快的。
除此之外,在测试SOR超松弛迭代法时还发现尽管其作为一种高斯赛德尔迭代法的加速,但有时,对于某些矩阵而言,松弛因子 w > 1 w>1 w>1反而会有反作用,此时使用 w = 1 w=1 w=1(即高斯赛德尔迭代法)效果会更好,个人认为关于 w w w的取值值得思考和探究。