近似算法中的技巧之一原始对偶模式
原始对偶模式
背景回顾
在过去的四十年里,组合优化受到线性规划的强烈影响。随着对线性规划的数学和算法的理解,出现了大量的思想和工具,然后应用到组合优化。其中许多思想和工具今天仍在使用,并形成了我们理解组合优化的基础,借助于线性规划对偶理论,人们提出了一个新的设计近似算法的技巧——原始对偶模式(PD)。
原对偶模式(The Primal-Dual Method)起源于精确算法的设计。在这种情况下,这种模式为P中的一些基础问题产生了最有效的算法,包括匹配、网络流和最短路径。这些问题的性质是它们的LP松弛具有整数最优解。比如在黄红选的《数学规划》[7]中对原始对偶算法的设计思路也是保证对偶可行,满足互补松弛性条件,逐步改善原始不可行性。当它们都被满足时,两个解都是最优解。在迭代过程中,总是对原始解进行整数修正,最终得到一个整数最优解。算法的基本过程如下:

有了原始对偶模式(PD),当我们要求一个整数规划问题的近似解时,在将它进行松弛以后,我们不必求出相应的线性规划问题的最优解。正如我们将看到的,PD方法是非常强大的。通常,我们可以用PD方法得到一个好的近似算法,然后从中提取出一个好的组合算法。相反,有时我们可以使用PD方法来证明组合算法的良好性能,只需将它们重新解释为PD算法,到目前为止,我们已经看到了许多基于线性规划(LP)松弛的算法,通常涉及将给定的分数LP解舍入到近似相同的目标值的整数解。
基础介绍
对偶理论的提出者—约翰·冯·诺伊曼(John Von Nouma,1903-1957),美籍匈牙利数学家、计算机科学家、博弈论、核武器和生化武器等领域内的科学全才之一,被后人称为“现代计算机之父”、“博弈论之父”

对偶理论有许多重要应用:在原始的和对偶的两个线性规划中求解任何一个规划时,会自动地给出另一个规划的最优解;当对偶问题比原始问题有较少约束时,求解对偶规划比求解原始规划要方便得多;对偶规划中的变量就是影子价格,可以为企业管理决策提供有用信息。
我们从一个通用的覆盖LP开始讲解对偶理论。假设我们有矩阵 A 和向量 c ∈ R n c\in R^{n} c∈Rn, b ∈ R m b\in R^{m} b∈Rm。我们可以将原始LP表示为

现在假设我们想要确定这个LP的最优值的一个下界。做到这一点的一种方法是对于某些 Z Z Z,使用LP中的约束,找到“看起来”像 ∑ j c j x j ≥ Z \sum_j c_jx_j\ge Z ∑jcjxj≥Z的约束。要做到这一点,注意来自LP的约束的任何凸组合也是有效的约束。因此,如果我们在约束上有非负的乘子 y i y_i yi,我们得到一个新的约束,它被原LP的所有可行解满足,即如果对于所有的 i i i, ∑ j a i j x j ≥ b i \sum_j a_{ij}x_j\ge b_i ∑jaijxj≥bi有
∑ i y i ( ∑ j a i j x j ) ≥ ∑ i y i b i ( 1 ) \sum_i y_i(\sum_j a_{ij}x_j)\ge \sum_i y_ib_i\qquad(1) i∑yi(j∑aijxj)≥i∑yibi(1)
注意,我们要求 y i y_i yi为非负,因为将一个不等式乘以一个负数会改变不等式的符号。(如果约束的形式为 ∑ j a i j x j = b i \sum_j a_{ij}x_j= b_i ∑jaijxj=bi,那么它的乘数 y i y_i yi可以是任何实数)。考虑公式(1),如果我们确保 ∑ i y i ( ∑ j a i j x j ) ≤ ∑ j c j x j \sum_i y_i(\sum_j a_{ij}x_j)\le \sum_jc_jx_j ∑iyi(∑jaijxj)≤∑jcjxj我们将得到原始LP最优值的一个下界,即
∑ i y i b i ≤ ∑ i y i ( ∑ j a i j x j ) ≤ ∑ j c j x j \sum_i y_ib_i\le \sum_i y_i(\sum_j a_{ij}x_j)\le\sum_jc_jx_j i∑yibi≤i∑yi(j∑aijxj)≤j∑cjxj
改变求和顺序,我们得到
∑ i y i b i ≤ ∑ i y i ( ∑ j a i j x j ) = ∑ j ( ∑ i y i a i j ) x j ≤ ∑ j c j x j ( 2 ) \sum_i y_ib_i\le \sum_i y_i(\sum_j a_{ij}x_j)=\sum_j (\sum_i y_ia_{ij})x_j\le\sum_jc_jx_j\qquad(2) i∑yibi≤i∑yi(j∑aijxj)=j∑(i∑yiaij)xj≤j∑cjxj(2)
并且可以通过要求 y i y_i yi满足以下条件来确保该和至多为
∑ i y i a i j ≤ c j ∀ j = 1 , . . . , n ( 3 ) \sum_i y_ia_{ij}\le c_j \quad \forall j= 1,...,n \qquad (3) i∑yiaij≤cj∀j=1,...,n(3)
注意,在上一步中,我们依赖于 x j x_j xj是非负的这一事实,同时, y i y_i yi的约束是线性的,我们得到的下限也是线性的。这样我们就可以写出一个LP来寻找最佳的下界。可以的写出对偶规划(DLP):

可以用更简洁的符号表示:
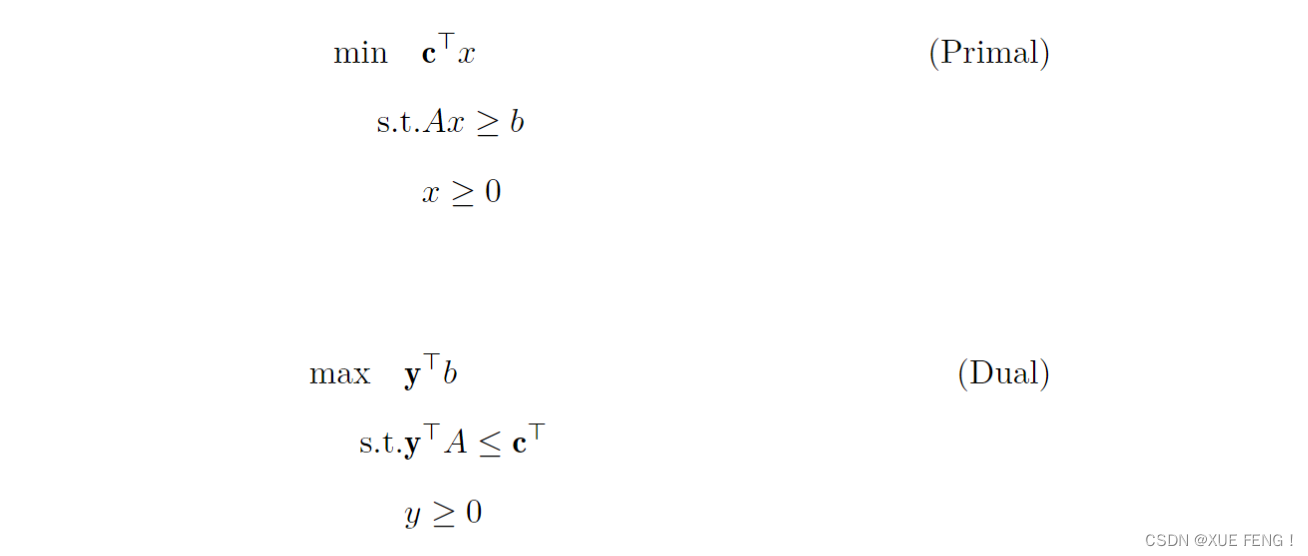
弱对偶性:对于任何可行的原始对偶解 ( x , y ) (x,y) (x,y),有
y ⊤ b ≤ c ⊤ x \mathbf{y}^\top b\le\mathbf{c}^\top x y⊤b≤c⊤x
证明由公式(2)可得。
强对偶性:如果原始或对偶有有界最优解,那么它们都有。而且它们的客观价值是平等的。也就是说,如果 x x x对原始最优, y y y对对偶最优,那么
y ⊤ b = c ⊤ x \mathbf{y}^\top b=\mathbf{c}^\top x y⊤b=c⊤x
我们一般不会证明强对偶定理,然而,证明这一点的一种方法是看公式(2),并注意到如果 y ⊤ b = c ⊤ x \mathbf{y}^\top b=\mathbf{c}^\top x y⊤b=c⊤x,则不等式一定是严格的,有人可能会说,如果 y ⊤ b ≤ c ⊤ x \mathbf{y}^\top b\le\mathbf{c}^\top x y⊤b≤c⊤x,则我们一定可以对 x x x或 y y y进行一些改进。强对偶性给出了最优 ( x , y ) (x,y) (x,y)对的附加约束,即以下等式,这些等式是通过将公式(2)与 y ⊤ b = c ⊤ x \mathbf{y}^\top b=\mathbf{c}^\top x y⊤b=c⊤x组合而得到的。
∑ i y i b i = ∑ i y i ( ∑ j a i j x j ) \sum_i y_ib_i= \sum_i y_i(\sum_j a_{ij}x_j) i∑yibi=i∑yi(j∑aijxj)
∑ j ( ∑ i y i a i j ) x j = ∑ j c j x j \sum_j (\sum_i y_ia_{ij})x_j=\sum_jc_jx_j j∑(i∑yiaij)xj=j∑cjxj
将这些方程与原始和对偶线性规划中的约束条件相结合,我们可以得到互补松弛条件。
互补松弛性 :设 ( x , y ) (x,y) (x,y)是一对具有有界最优解的原始对偶线性规划的解,那么 x x x和 y y y都是最优的当且仅当下列条件成立:
原始互补松弛条件:
∀ j = 1 , . . . , n , x j = 0 o r ∑ i y i a i j = c j \forall j=1,...,n,\quad x_j=0\quad or\quad \sum_i y_ia_{ij}=c_j ∀j=1,...,n,xj=0ori∑yiaij=cj
对偶互补松弛条件:
∀ i = 1 , . . . , m , y i = 0 o r ∑ j x j a i j = b i \forall i=1,...,m,\quad y_i=0\quad or \quad\sum_j x_ja_{ij}=b_i ∀i=1,...,m,yi=0orj∑xjaij=bi
在设计基于线性规划的近似算法时,首先,我们将一个求最小值(或者求最大值)的问题 Π \Pi Π松弛为一个线性规划 Π L P \Pi_{LP} ΠLP。然后,我们求出线性规划问题 Π L P \Pi_{LP} ΠLP的一个最优解 O P T L P OPT_{LP} OPTLP,并对其进行舍入处理成为问题 Π \Pi Π的一个可行解。注意线性规划问题的最优解 O P T L P OPT_{LP} OPTLP的目标值给出了问题 Π \Pi Π的最优解OPT的一个下界(或者上界),我们常用这两个值的差来估算这个近似算法的性能比。现在根据对偶理论可知,每一个对偶可行解为我们提供了线性规划问题 Π L P \Pi_{LP} ΠLP最优值的一个下界(或者上界),因此,它也是原问题 Π \Pi Π的最优值OPT的一个下界(或者上界)。这意味着,一个“足够好的”对偶可行解还可以用来确定近似算法的性能比。因此,我们就不必求出线性规划问题 Π L P \Pi_{LP} ΠLP的最优解 O P T L P OPT_{LP} OPTLP及相应的目标值,而仅仅需要求出一个“足够好的”对偶可行解,然后将其转化为原问题 Π \Pi Π的一个可行解,最后用这两个解的目标值之差来估算近似算法的性能比。
原始对偶模式
原始对偶模式是设计近似算法的首选方法,因为它通常给出具有良好近似保证和良好运行时间的算法。其基本思想是处理NP-难问题及其对偶的LP松弛问题,然后迭代变换原解和对偶解,直到满足松弛的原始对偶互补松弛条件。
松弛的原始互补松弛条件:
∀ j = 1 , . . . , n , x j = 0 o r c j α ≤ ∑ i y i a i j ≤ c j \forall j=1,...,n,\quad x_j=0\quad or \quad \frac{c_j}{\alpha}\le \sum_i y_ia_{ij}\le c_j ∀j=1,...,n,xj=0orαcj≤i∑yiaij≤cj
松弛的对偶互补松弛条件:
∀ i = 1 , . . . , m , y i = 0 o r b i ≤ ∑ j x j a i j ≤ β ⋅ b i \forall i=1,...,m,\quad y_i=0\quad or\quad b_i \le\sum_j x_ja_{ij}\le \beta\cdot b_i ∀i=1,...,m,yi=0orbi≤j∑xjaij≤β⋅bi
如果x和y分别是原可行解和对偶可行解,满足上述松弛性互补条件,则
∑ j c j x j ≤ α β ∑ i y i b i \sum_jc_jx_j\le \alpha \beta\sum_i y_ib_i j∑cjxj≤αβi∑yibi
证明:
∑ j c j x j ≤ α ∑ j ( ∑ i y i a i j ) x j = α ∑ i y i ( ∑ j a i j x j ) ≤ α β ∑ i y i b i \sum_jc_jx_j\le \alpha\sum_j (\sum_i y_ia_{ij})x_j \\ =\alpha \sum_i y_i(\sum_j a_{ij}x_j)\le \alpha \beta \sum_i y_ib_i j∑cjxj≤αj∑(i∑yiaij)xj=αi∑yi(j∑aijxj)≤αβi∑yibi
引理1说明,算法的逼近保证为 α β \alpha \beta αβ。
线性规划松弛的整间隙
给定最小化问题 Π \Pi Π的线性规划松弛,用 O P T f ( I ) OPT_f(I) OPTf(I)表示实例I的最优分数解的费用,即线性规划松弛最优解的目标函数值。则松弛的整间隙(有时也称为整比率)为
s u p I O P T ( I ) O P T f ( I ) \underset{I}{sup}\frac{OPT(I)}{OPT_f(I)} IsupOPTf(I)OPT(I)
即最优整数解和最优分数解比率的上确界。
对于最大化问题,整间隙定义为这个比率的下确界,当线性规划的整间隙是1,我们称这种线性规划松弛为精确松弛。如果把算法找到的解的费用和最优分数解(或对偶可行解)的费用直接作比较,那么我们能够期待证明的最好近似因子应当是松弛的整间隙。有趣的是,原始对偶技术已经成功地得到近似保证恰好等于松弛的整间隙的算法。
原始对偶模式的近似算法
接下来我们介绍基于原始对偶模式的近似算法,如下:

原始对偶模式的优点在于,它避免了求原始线性规划问题的最优解所耗费的大量时间,从而减少了算法的运行时间。特别是,目前求解线性规划最快的内点算法的时间复杂度也是 O ( n 3.5 ) O(n^{3.5}) O(n3.5)的量级。而且,在某些实际应用中,需要求解的是在线问题,此时要求出线性规划问题的最优解就不太现实了,原始对偶模式所能带来的加速效果就是必需的了。
总结
我们主要介绍原始对偶技术的基本内容,后面将会展示原始-对偶技术对不同的问题是如何被修改的,以便为各种各样的NP-hard问题提供好的近似算法。敬请期待!
参考文献
[1] R. Bar-Yehuda and S. Even. A linear time approximation algorithm for the weighted vertex
cover problem. Journal of Algorithms, 2:198–203, 1981.
[2] Michel X. Goemans and David P. Williamson. The primal-dual method for approximation algorithms and its application to network design problems. In Dorit Hochbaum, editor, Approximation algorithms for NP-hard problems, chapter 4, pages 144–191. PWS Publishing Co., Boston, MA, USA, 1997.
[3] D. Williamson. The primal-dual method for approximation algorithms. Mathematical Programming, Series B, 91(3):447–478, 2002.
[4] H.W. Kuhn. The Hungarian method for the assignment problem. Naval Research Logistics Quarterly, 2:83–97, 1955.
[5] G.B. Dantzig, L.R. Ford, and D.R. Fulkerson. A primal–dual algorithm for linear programs. In H.W. Kuhn and A.W. Tucker, editors, Linear Inequalities and Related Systems, pages 171–181. Princeton University Press, Princeton, NJ, 1956.
[6] M.X. Goemans and D.P. Williamson. The primal–dual method for approximation algorithms and its applications to network design problems. In D.S.
[7] 黄红选.数学规划:清华大学研究生公共课教材.数学系列[M]:清华大学出版社,2006.