注意:文中彩色代码均在Visual Studio 2022编译器中编写,本文为C语言数据结构手抄版,文中有部分改动,非原创。
目录
第八章 查找
学习目标
1,熟练掌握顺序查找、二分查找和分块查找的方法,并能灵活应用。
2,熟练掌握二叉排序树的构造方法及查找过程。
3,了解B树的特点及建树过程。
4,熟练掌握散列表的构造方法及其查找过程。
5,熟练掌握各种查找方法在等概率情况下查找成功的平均查找长度的计算方法。
8.1.基本概念
查找(Search)又称检索,是数据处理中经常使用的一种重要运算。人们在日常生活中几乎每天都要做查找工作,如查找电话号码、查找图书书号、查找字典等。由于查找运算频率很高,在任何一个计算机应用软件和系统软件中都会涉及,所以,当问题所涉及的数据量很大时,查找方法的效率就显得格外重要。对各种查找方法的效率进行分析比较是本章的主要内容。
查找同排序一样,也有内查找和外查找之分:若整个查找过程都在内存中进行,则称之为内查找;反之,称为外查找。由于查找运算的主要操作是关键字的比较,因此,通常把查找过程中的平均比较次数(也称为平均查找长度)作为衡量一个查找算法效率优劣的标准。平均查找长度(Average Search Length, ASL)的计算公式定义为:

其中, n为结点的个数, Pi是查找第i个结点的概率。在本章后面的介绍中,若不作说明,均认为查找每个结点是等概率的,即P1=P2=···=Pn=1/n; Ci为找到第i个结点所需要比较的次数。若查找每个元素的概率相等,则平均查找长度计算公式可简化为
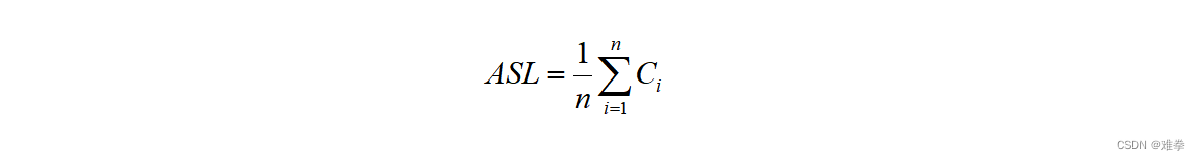
8.2.顺序表的查找
顺序表是指线性表的顺序存储结构。在顺序表上的查找方法有多种,这里只介绍最常用的、最主要的两种方法,即顺序查找和二分查找。
| 顺序查找 |
折半查找 |
分块查找 |
|
| ASL |
最大 |
最小 |
中间 |
| 表结构 |
有序表、无序表 |
有序表 |
分块有序 |
| 存储结构 |
顺序表、线性链表 |
顺序表 |
顺序表、线性链表 |
8.2.1.顺序查找
顺序查找(Sequential Search)又称线性查找,是一种最简单和最基本的查找方法。其基本思想是:从表的一端开始,顺序扫描线性表,依次把扫描到的记录关键字与给定的值value相比较,若某个记录的关键字等于value,则表明查找成功,返回该记录所在的下标;若直到所有记录都比较完,仍未找到关键字与value相等的记录,则表明查找失败,返回0值。顺序查找的算法描述如下:
| #define _CRT_SECURE_NO_WARNINGS //规避C4996告警 #include <stdio.h> #include <stdlib.h> int main() { int array[] = { -1, 278, 109, 63, 930, 589, 184, 505, 269, 8, 83}, n = 10, value = 505; // 0号位置做哨兵 防止数组访问越界 array[0] = value; int i = n; while (array[i] != value) { i--; } printf("值value在数组中索引:%d", i); return 0; } |
由于这个算法省略了对下标越界的检查,查找速度有了很大的提高。哨兵也可设在高端,算法留给读者自己设计。尽管如此,顺序查找的速度仍然是比较慢的,查找最多需要比较n+1次。若整个表array[1..n]已扫描完,还未找到与value相等的记录,则循环必定终止于array[0]==i,返回值为0,表示查找失败,总共比较了n+1次;若循环终止于i>0,则说明查找成功,此时,若i=n,则比较次数Cn=1;若i=1,则比较次数C1=n;一般情况下Ci=n-i+1。因此,查找成功时平均查找长度为:

即顺序查找成功时的平均查找长度约为表长的一半(假定查找某个记录是等概率)。
查找长度:即查找元素的比较次数。
如果查找成功和不成功机会相等,那么顺序查找的平均查找长度:

顺序查找的优点是简单的,且对表的结构无任何要求,无论是顺序存储还是链式存储,无论是否有序,都同样适用,缺点是效率低。
假设要查找的顺序表是按关键字递增有序的,如果要按前面所给的顺序查找算法同样是可以实现的,但是,表有序的条件就没能用上,这其实就是资源上的浪费。那么,如何又能用上这个条件呢?可用下面给出的算法来实现:
| #define _CRT_SECURE_NO_WARNINGS //规避C4996告警 #include <stdio.h> #include <stdlib.h> int main() { int array[] = { -1, 15, 18, 30, 35, 36, 45, 48, 53, 72, 93 }, n = 10, value = 36; // 0号位置做哨兵 防止数组访问越界 array[0] = value; int i = n; while (array[i] > value) { i--; } if (array[i] == value) { printf("值value在数组中索引:%d", i); } else { printf("值value在数组中索引:%d", i); } return 0; } |
上述算法中,循环语句是判断当要查找值value小于表中当前关键字值时,就循环向前查找,一旦大于或等于关键字值时就结束循环。然后再判断是否相等,若相等,则返回相等元素下标;否则,返回0值表示未查到。该算法查找成功的平均查找长度与无序表.查找算法的平均查找长度基本一样,只是在查找失败时,无序表的查找长度是n+1,而该算法的平均查找长度则是表长的一半,因此,该算法的平均查找长度是:

顺序查找的优点是算法简单,且对表的存储结构无任何要求,无论是顺序结构还是链式结构,也无论结点关键字是有序还是无序,都适应顺序查找;其缺点是当n较大时,其查找成功的平均查找长度约为表长的一半(n+1) /2,查找失败则需要比较n+1次,查找效率低。查找时间与表长n有关系,顺序查找法的平均比较次数为(n+1)/2次,则其时间复杂度就是(n+1)/2,当n->无穷大时,该表达式与n为同阶无穷大,记为O(n),所以其时间复杂度为O(n)。
8.2.2.二分查找
二分查找(Binary Search)又称折半查找,是一种效率较高的查找方法。二分查找要求查找对象的线性表必须是顺序存储结构的有序表(不妨设递增有序)。
二分查找的过程是:首先将待查的value值和有序表array[1..n]的中间位置mid上的记录的关键字进行比较,若相等,则查找成功,返回该记录的下标mid;否则,若array[mid]>value,则value在左子表array[1..mid-1]中,接着再在左子表中进行二分查找即可;否则,若array[mid]<value,则说明待查记录在右子表array[mid+1..n]中,接着只要在右子表中进行二分查找即可。这样,经过一次关键字的比较,就可缩小一半的查找空间,如此进行下去,直到找到关键字为value的记录或者当前查找区间为空时(即查找失败)为止。二分查找的过程是递归也可以是非递归的,因此可用递归的方法来处理,其递归算法描述如下:
| #define _CRT_SECURE_NO_WARNINGS //规避C4996告警 #include <stdio.h> #include <stdlib.h> int find(int* array, int value, int low, int high) { int mid = (low + high) / 2; if (value == array[mid]) { return mid; } if (value > array[mid]) { return find(array,value, mid + 1, high); } else { return find(array, value, low, mid - 1); } } int main() { int array[] = { 15, 18, 30, 35, 36, 45, 48, 53, 72, 93 }, size = 10, value = 36; printf("值value在数组中索引:%d", find(array, value, 0, size)); return 0; } |
二分查找算法也可以用非递归的方法来实现,其算法描述如下:
| #define _CRT_SECURE_NO_WARNINGS //规避C4996告警 #include <stdio.h> #include <stdlib.h> int find(int* array, int value, int low, int high) { int mid = -1; while (1) { mid = (low + high) / 2; if (value == array[mid]) { return mid; } if (value > array[mid]) { low = mid + 1; } else { high = mid - 1; } } } int main() { int array[] = { 15, 18, 30, 35, 36, 45, 48, 53, 72, 93 }, size = 10, value = 36; printf("值value在数组中索引:%d", find(array, value, 0, size)); return 0; } |
例如,给定一组关键字为(13, 25, 36, 42, 48, 56, 64, 69, 78, 85, 92),查找42和80的二分查找过程如图8.1所示。

显然,二分查找过程可用一棵二叉树来描述。树中每个子树的根结点对应当前查找区间的中位记录array[mid],它的左子树和右子树分别对应区间的左子表和右子表,通常将此树称为二叉判定树。由于二分查找是在有序表上进行的,所以其对应的判定树必定是一棵二叉排序树(此概念将在第8.2.3节介绍)。例如,在上面的例子中,查找第6个结点仅需比较1次,查找第3或第9个结点需要比较2次,查找第1、4、7或第10个结点则需要比较3次;查找第2、5、8或第11个结点需要比较4次。整个查找过程可用图8.2所示的二叉树来描述。

从判定树上可见,查找42的过程恰好走了一条从根到结点④的路径,关键字比较的次数恰好为该结点在树中的层数。若查找失败(如查找80),则其比较过程是经历了一条从判定树根到某个外部结点的路径,所需的关键字比较次数是该路径上结点(6、9、10)的总数3,因此,二分查找算法在查找成功时,进行关键字比较的次数最多不超过判定树的深度。假设有序表的长度n=2h-1, h=log2 (n+1),则描述二分查找的判定树是深度为h的满二叉树,树中层次为1的结点有1个,层次为2的结点有2个,··· ···,层次为h的结点有2h-1个。假设每条记录的查找概率相等,即Pi=1/n,则查找成功时二分查找的平均长度为

因为树中第j层上结点个数为2j-1,查找它们所需要比较的次数是j。当n很大很大时,可用近似公式ASL=log2 (n+1)-1来表示二分查找成功时的平均查找长度。二分查找失败时,所需要比较的关键字个数不超过判定树的深度。因为判定树中度数小于2的结点只可能在最下面的两层,所以n个结点的判定树的深度和n个结点的完全二叉树的深度相同,即为

由此可见,二分查找的最坏性能和平均性能相当接近。
【例8.1】试写一算法,利用二分查找算法在有序表array中插入一个元素value,并保持表的有序性。
分析:依题意,先在有序表array中利用二分查找算法查找关键字值等于或大于value的结点:若关键字等于value,mid正好指向插入位置索引;若关键字大于value,low正好指向插入位置索引;若low大于有序表array最大元素索引,则此时high正好指向插入位置索引。然后采用移动法插入array中即可。因此,实现本题功能的算法如下:
| #define _CRT_SECURE_NO_WARNINGS //规避C4996告警 #include <stdio.h> #include <stdlib.h> void find(int* array, int value, int low, int high, int size) { int mid = -1, find = 0; while (low <= high && !find) { mid = (low + high) / 2; if (value > array[mid]) { low = mid + 1; } else if (value < array[mid]) { high = mid - 1; } else { find = mid; } }
if (!find && low < size) { find = low; } else if(!find) { find = high; } for (int i = size - 1; i > find; i--) { array[i] = array[i - 1]; } array[find] = value; } int main() { int array[] = { 15, 18, 30, 35, 36, 45, 48, 53, 72, 93, -1}, high = 10, value = 37; find(array, value, 0, high, high + 1); for (int i = 0; i < high + 1; i++) { printf("%d ", array[i]); } return 0; } |
【例8.2】对19个记录的有序表进行二分查找,试画出描述二分查找过程的二叉树,并计算在每个记录的查找概率相同的情况下的平均查找长度。
分析:二分查找过程的二叉树如图8.3所示。
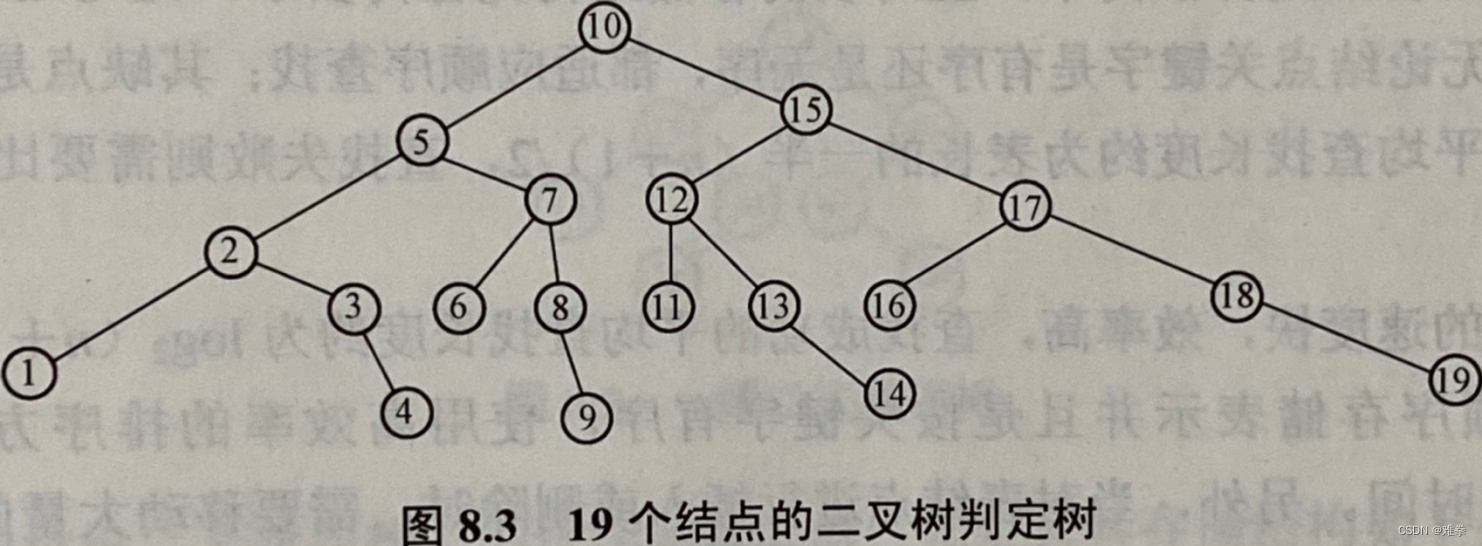
我们知道,在二叉判定树上表示的结点所在的层数(深度)就是查找该结点所需要比较的次数,因此,其平均查找长度(平均比较次数):
ASL=((1+2*2+3*4+4*8)+(5*4))/19=69/19≈3.42
二分查找的速度快,效率高,查找成功的平均查找长度约为1og2 (n+1)-1,但是它要求表以顺序存储表示并且是按关键字有序,使用高效率的排序方法也要花费O(nlog2n)的时间。时间复杂度即是while循环的次数。总共有n个元素,渐渐跟下去就是n,n/2,n/4,....n/2^k,其中k就是循环的次数。由于n/2k取整后>=1,即令n/2^k=1,可得k=log2n,(是以2为底,n的对数)所以时间复杂度可以表示O(h)=O(log2n)。另外,当对表结点进行插入或删除时,需要移动大量的元素,所以二分查找适用于表不易变动且又经常查找的情况。
8.2.3.索引顺序查找(分块查找)
索引顺序查找又称分块查找,是一种介于顺序查找和二分查找之间的查找方法。
分块查找是折半查找和顺序查找的一种改进方法,折半查找虽然具有很好的性能,但其前提条件是线性表顺序存储而且按照关键码排序,这一前提条件在结点树很大且表元素动态变化时是难以满足的。而顺序查找可以解决表元素动态变化的要求,但查找效率很低。如果既要保持对线性表的查找具有较快的速度,又要能够满足表元素动态变化的要求,则可采用分块查找的方法。
分块查找的速度虽然不如折半查找算法,但比顺序查找算法快得多,同时又不需要对全部节点进行排序。当节点很多且块数很大时,对索引表可以采用折半查找,这样能够进一步提高查找的速度。
分块查找由于只要求索引表是有序的,对块内节点没有排序要求,因此特别适合于节点动态变化的情况。当增加或减少节以及节点的关键码改变时,只需将该节点调整到所在的块即可。在空间复杂性上,分块查找的主要代价是增加了一个辅助数组。
需要注意的是,当节点变化很频繁时,可能会导致块与块之间的节点数相差很大,某些块具有很多节点,而另一些块则可能只有很少节点,这将会导致查找效率的下降。
| #define _CRT_SECURE_NO_WARNINGS //规避C4996告警 #include <stdio.h> #include <stdlib.h> struct Lump { int index; int value; }; void insertSort(struct Lump* lump, int size) { struct Lump sentry = { 0, -1}; int j; for (int i = 1; i < size; i++) { if (lump[i].value < lump[i - 1].value) { sentry = lump[i]; for (j = i; j > 0 && lump[j - 1].value > sentry.value; j--) { lump[j] = lump[j - 1]; } lump[j] = sentry; } } } void initLumpFind(struct Lump* lump, int lumpSize, int* array, int size) { int j = 0; for (int i = 0; i < lumpSize; i++) { int max = -1, lumpIndex = size / lumpSize + j - 1; if (i == lumpSize - 1) lumpIndex = size - 1; for (; j <= lumpIndex; j++) { if (max < array[j]) { max = array[j]; lump[i].index = lumpIndex; lump[i].value = max; } } } insertSort(lump, lumpSize); } int lumpFind(struct Lump* lump, int lumpSize, int* array, int size, int findValue) { int startIndex = -1, endIndex = -1; for (int i = 0; i < lumpSize; i++) { if (findValue <= lump[i].value) { if(findValue == lump[i].value) return lump[i].index; endIndex = lump[i].index; startIndex = endIndex - size / lumpSize + 1; if (endIndex == size - 1) { startIndex = startIndex - (size % lumpSize); } break; } } for (int i = startIndex; i <= endIndex; i++) { if (findValue == array[i]) { return i; } } return -1; } int main() { struct Lump lump[3] = { 0 }; int lumpSize = 3, findValue = 53; int array[] = { 53, 72, 93, 36, 45, 48, 15, 18, 35, 30}, size = 10; initLumpFind(&lump, lumpSize, &array, size); printf("找到元素索引:%d", lumpFind(&lump, lumpSize, &array, size, findValue)); return 0; } |
分块查找要求按如下的索引方式来存储线性表:将表array[1..n]均分为b块,第一块中的结点个数为(n/b)向上取整,第b块的结点数≤(n/b)向上取整;每一块中的关键字不一定有序,但前一块中的最大关键字必须小于后一块的最小关键字,即要求表是“分块有序”的;抽取各块中的最大关键字及其起始位置构成一个索引表ID[1..b],即ID[i] (1≤i≤b)中存放着第i块的最大关键字及该块在表array中的起始位置,显然,索引表是按关键字递增有序的。表及其索引表如图8.4所示。
分块查找的基本思想是:首先查找索引表,可用二分查找或顺序查找,然后在确定的块中进行顺序查找。由于分块查找实际上是两次查找过程,因此整个查找过程的平均查找长度,是两次查找的平均查找长度之和。

查找块有两种方法,一种是二分查找,若按此方法来确定块,则分块查找的平均查找长度为:
ASLblk=ASLbin+ASLseq=log(b+1)-1+(s-1)/2≈log(n/s+1)+s/2
另一种是顺序查找,此时的分块查找的平均查找长度为:
ASLblk=(b+1)/2+(s+1)/2=(s2+2s+n)/(2s)
分块查找的优点是,在表中插入或删除一个记录时,只要找到该记录所属的块,就可以在该块内进行插入或删除运算。因为块内记录是无序的,所以插入或删除比较容易,无需移动大量记录。分块查找的主要缺点是需要增加一个辅助数组的存储空间和将初始表块排序的运算,它也不适宜用链式存储结构。若以二分查找确定块,则分块查找成功的平均查找长度为1og2 (n/s+1) +s/2;若以顺序查找确定块,则分块查找成功的平均查找长度为(s2+2s+n)/(2s),其中, s为分块中的结点个数,n为关键字个数。
如果线性表既要快速查找又要经常动态变化,可采用分块查找。分块查找算法的时间复杂度为:

8.3.树表的查找
树表查找是对树形存储结构所做的查找。树形存储结构是一种多链表,表中的每个结点包含有一个数据域和多个指针域,每个指针域指向一个后继结点。树形存储结构和树形逻辑结构是完全对应的,都表示一个树形图,只是用存储结构中的链指针代替逻辑结构中的抽象指针罢了。因此,往往把树形存储结构(即树表)和树形逻辑结构(树)统称为树结构或树。在本节中,将分别讨论在树表上进行查找和修改的方法。
8.3.1.二叉排序树(二叉查找树)
二叉排序树(Binary Sort Tree, BST)又称二叉查找树,是一种特殊的二叉树,它或者是一棵空树,或者是具有下列性质的二叉树:
(1)若它的右子树非空,则右子树上所有结点的值均大于根结点的值。
(2)若它的左子树非空,则左子树上所有结点的值均小于根结点的值。
(3)左、右子树本身又各是一棵二叉排序树。
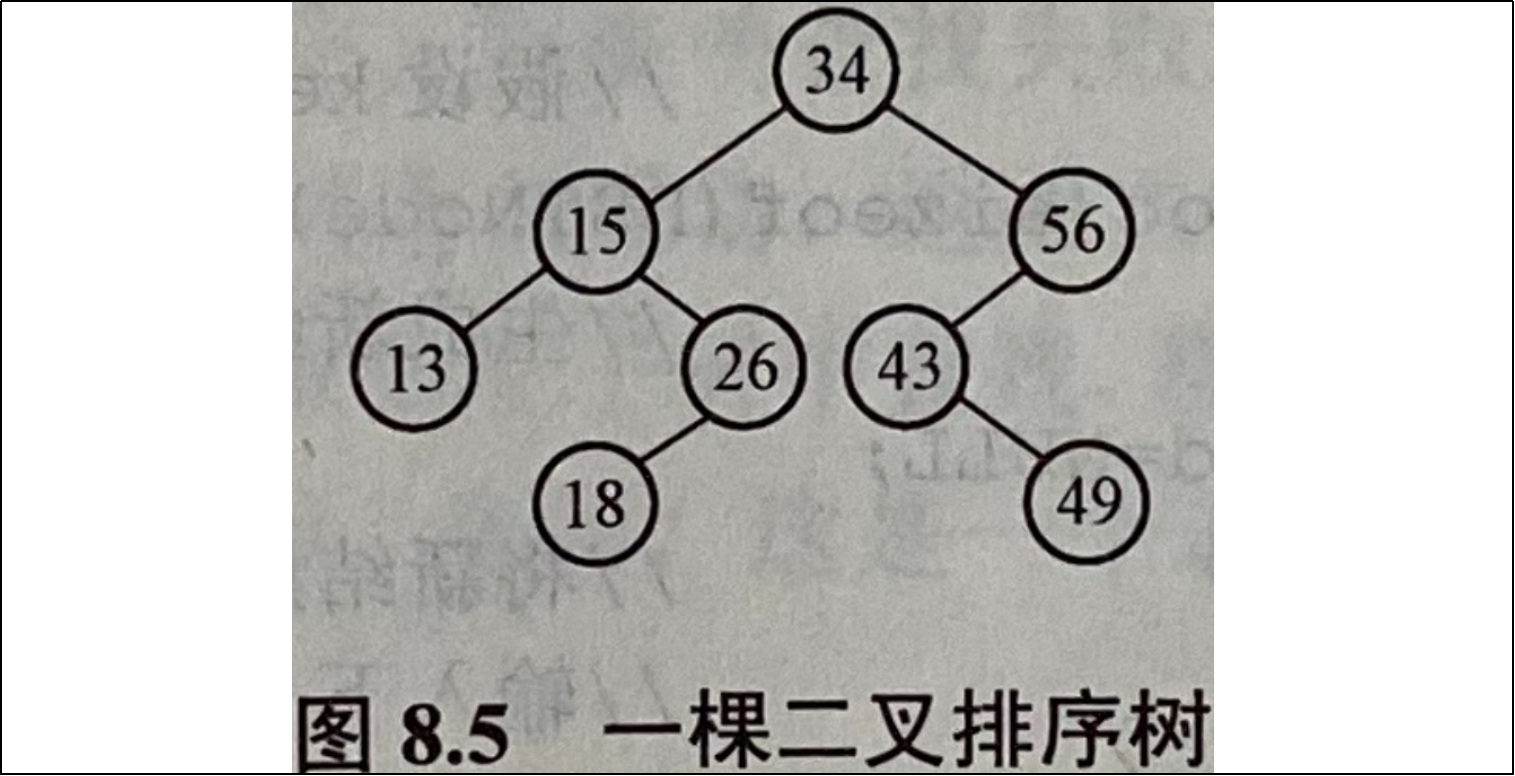
从上述性质可推出二叉排序树的另一个重要性质,即按中序遍历二叉排序树所得到的遍历序列是一个递增有序序列。例如,图8.5所示就是一棵二叉排序树,树中每个结点的关键字都大于它左子树中所有结点的关键字,而小于它右子树中所有结点的关键字。若对其进行中序遍历,得到的遍历序列为: 13, 15, 18, 26, 34, 43, 49, 56,可见,此序列是一个有序序列。
在介绍和讨论二叉排序树上的操作运算之前,先定义其存储结构如下:
| struct BinaryNode { char* data; struct BinaryNode* left; struct BinaryNode* right; }; |
1.二叉排序树的插入和生成
在二叉排序树中插入新结点,只要保证插入后仍满足二叉排序树的性质即可。其插入过程是这样进行的:若二叉树tree为空,则新结点*node作为根结点插入到空树中。当二叉树tree为,非空时,将插入结点的关键字node->key与根结点关键字rootNode->key比较:若node->key等于rootNode->key,则说明树中已有此结点,无需插入;若node->key小于rootNode->key,则将新结点插入到左子树,否则插入到右子树。
二叉树的创建使用第五章5.3.1小节封装的二叉树生成算法,在二叉树源码中添加创建一个空二叉树的逻辑。
| struct BinaryTree* initEmtpyBinaryTree() { struct BinaryTree* binaryTree = malloc(sizeof(struct BinaryTree)); if (binaryTree == NULL) { #if PRINT printf("创建空二叉树失败,内存空间不足!\n"); #endif return NULL; } binaryTree->root = NULL; binaryTree->depth = 0; setBinaryTreeFunction(binaryTree); return binaryTree; } |
新增insert函数,在数据在插入二叉树时使二叉树始终保持是一个二叉排序树。二叉排序树的生成是比较简单的,其基本思想是:从空的二叉树开始,每输入一个结点数据,生成一个新结点,就调用一次插入算法将它插入到当前生成的二叉排序树中。其生成算法描述如下:
| void insertBinaryTree(char* data, struct BinaryTree* binaryTree) { if (binaryTree == NULL) { #if PRINT printf("二叉树不存在!\n"); #endif return; } if (data == NULL) { #if PRINT printf("插入二叉树数值为空!\n"); #endif return; } struct BinaryNode* pointer = binaryTree->root; if (binaryTree->root == NULL) { pointer = malloc(sizeof(struct BinaryNode)); if (pointer == NULL) { #if PRINT printf("二叉树结点失败,内存空间不足!\n"); #endif return; } pointer->data = data; pointer->left = NULL; pointer->right = NULL; binaryTree->root = pointer; return; } struct BinaryNode* front = NULL; int depth = 1; while (pointer != NULL) { front = pointer; depth++; if (strcmp(data, pointer->data) > 0) { pointer = pointer->right; } else if (strcmp(data, pointer->data) == 0) { #if PRINT printf("插入二叉树数据%s已存在!\n", data); #endif return; } else { pointer = pointer->left; } } binaryTree->depth = binaryTree->depth > depth ? binaryTree->depth : depth; struct BinaryNode* binaryNode = malloc(sizeof(struct BinaryNode)); if (binaryNode == NULL) { #if PRINT printf("二叉树结点失败,内存空间不足!\n"); #endif return; } binaryNode->data = data; binaryNode->left = NULL; binaryNode->right = NULL; if (strcmp(data, front->data) > 0) { front->right = binaryNode; } else { front->left = binaryNode; } } |
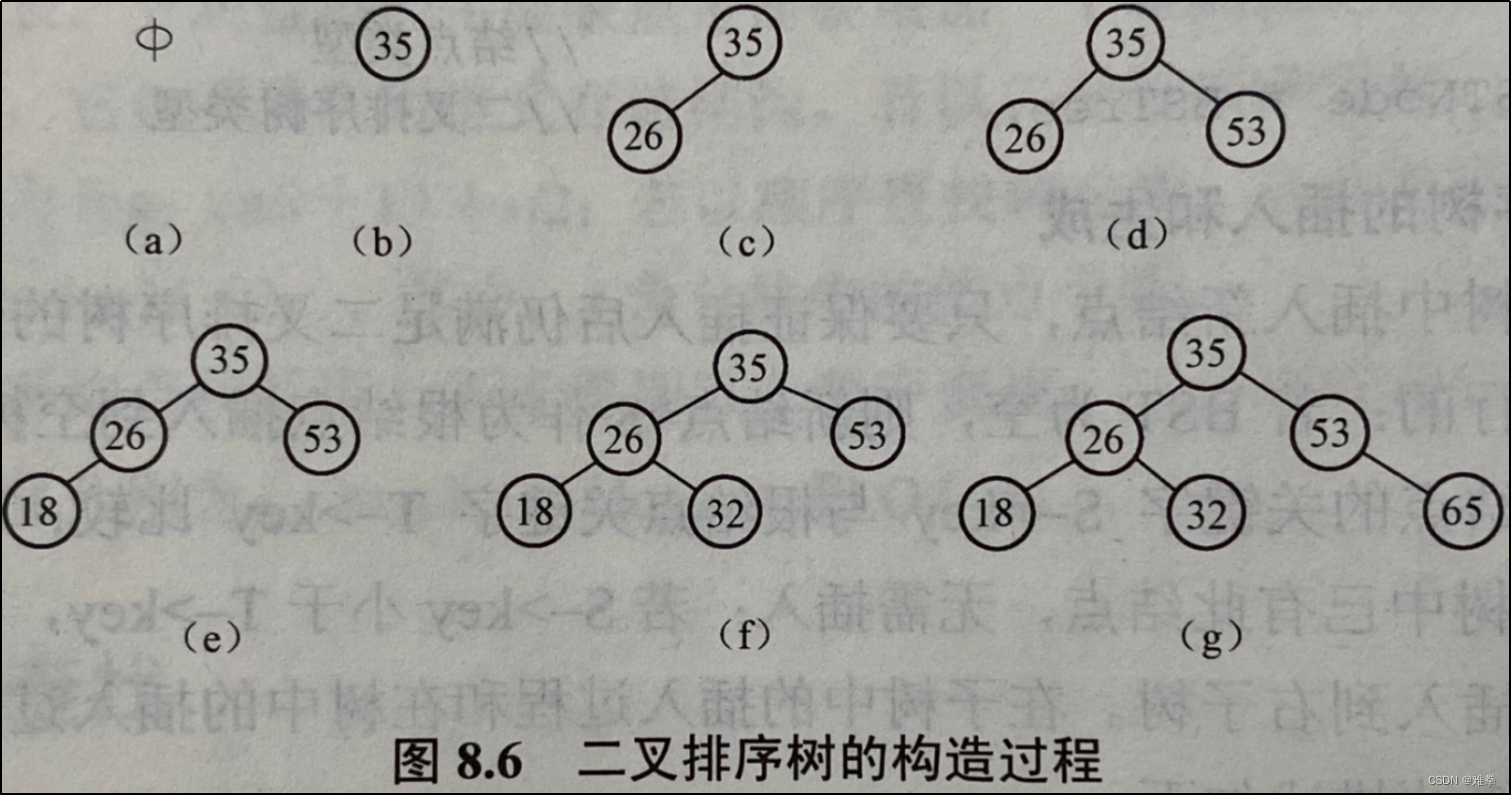
例如,已知输入关键字序列为(35, 26, 53, 18, 32, 65),按上述算法生成二叉排序树的过程如图8.6所示。
测试生成二叉排序树:
| #define _CRT_SECURE_NO_WARNINGS //规避C4996告警 #include <stdio.h> #include <stdlib.h> #include "binaryTree.h" int main() { struct BinaryTree* tree = initEmtpyBinaryTree(); tree->insert("35", tree); tree->insert("26", tree); tree->insert("53", tree); tree->insert("18", tree); tree->insert("32", tree); tree->insert("65", tree); tree->draw(tree); return 0; } |
运行结果:
| 35 / \ 26 53 / \ / \ 18 32 * 65 / \/ / \/ \ |
若输入关键字序列为(18, 26, 32, 35, 53, 65),则生成的二叉排序树如图8.7所示。从上例可以看到,同样的一组关键字序列,由于其输入顺序不同,所得到的二叉排序树也有所不同。上面生成的两棵二叉排序树,一棵的深度是3,而另一棵的深度则为6,因此,含有n个结点的二叉排序树不是唯一的。

测试生成二叉排序树:
| #define _CRT_SECURE_NO_WARNINGS //规避C4996告警 #include <stdio.h> #include <stdlib.h> #include "binaryTree.h" int main() { struct BinaryTree* tree = initEmtpyBinaryTree(); tree->insert("18", tree); tree->insert("26", tree); tree->insert("32", tree); tree->insert("35", tree); tree->insert("53", tree); tree->insert("65", tree); tree->draw(tree); return 0; } |
运行结果:

由二叉排序树的定义可知,在一棵非空的二叉排序树中,其结点的关键字是按照左子树、根和右子树有序的,所以对它进行中序遍历得到的结点序列是一个有序序列,如图8.7所示。一般情况下,构造二又排序树的真正目的并不是为了排序,而是为了更好地查找。因此,通常称二叉排序树为二叉查找树。
2.二叉排序树上的查找
二叉排序树可看成一个有序表,所以在二叉排序树上查找与二分查找类似,也是一个逐步缩小查找范围的过程。根据二叉排序树的定义,查找其关键字等于给定值data的元素的过程为:若二叉排序树为空,则表明查找失败,应返回空指针。否则,若给定值data等于根结点的关键字,则表明查找成功,返回当前根结点指针;若给定值data小于根结点的关键字,则继续在根结点的左子树中查找,若给定值data大于根结点的关键字,则继续在根结点的右子树中查找。显然,这是一个递归的查找过程,其递归算法描述如下:
二叉树的创建使用第五章5.3.1小节封装的二叉树生成算法。
| #define _CRT_SECURE_NO_WARNINGS //规避C4996告警 #include <stdio.h> #include <stdlib.h> #include "binaryTree.h" struct BinaryNode* find(struct BinaryNode* root, char* data) { if(root == NULL || strcmp(root->data, data) == 0) { return root; } if (strcmp(data, root->data) > 0) { find(root->right, data); } else { find(root->left, data); } } int main() { struct BinaryTree* tree = initEmtpyBinaryTree(); tree->insert("18", tree); tree->insert("26", tree); tree->insert("32", tree); tree->insert("35", tree); tree->insert("53", tree); tree->insert("65", tree); tree->draw(tree); char* data= "55"; struct BinaryNode* node = find(tree->root, data); if (node == NULL) { printf("元素值:%s不在二叉排序树中。", data); return 0; } printf("元素值:%s在二叉排序树中。", data); return 0; } |
运行结果:

将二叉排序树查找封装到第五章5.3.1小节封装的二叉树生成算法中。
| .h中添加: struct BinaryTree { ... ... struct BinaryNode* (*find)(char* data, struct BinaryTree* binaryTree); ... ... }; .c中添加: struct BinaryNode* findTreeData(char* data, struct BinaryTree* binaryTree) { if (binaryTree == NULL || binaryTree->root == NULL) { #if PRINT printf("二叉树不存在!\n"); #endif return; } struct BinaryNode* recursionFindData(struct BinaryNode* root, char* data, struct BinaryNode** parent); return recursionFindData(binaryTree->root, data, NULL); } struct BinaryNode* recursionFindData(struct BinaryNode* root, char* data, struct BinaryNode** parent) { if (root == NULL || strcmp(root->data, data) == 0) { return root; } if(parent != NULL) *parent = root; if (strcmp(data, root->data) > 0) { recursionFindData(root->right, data, parent); } else { recursionFindData(root->left, data, parent); } } |
测试:
| #define _CRT_SECURE_NO_WARNINGS //规避C4996告警 #include <stdio.h> #include <stdlib.h> #include "binaryTree.h" int main() { struct BinaryTree* tree = initEmtpyBinaryTree(); tree->insert("18", tree); tree->insert("26", tree); tree->insert("32", tree); tree->insert("35", tree); tree->insert("53", tree); tree->insert("65", tree); tree->draw(tree); char* data = "55"; struct BinaryNode* node = tree->find(data, tree); if (node == NULL) { printf("元素值:%s不在二叉排序树中。", data); return 0; } printf("元素值:%s在二叉排序树中。", data); return 0; } |
在二叉排序树上进行查找的过程中,给定值value与树中结点比较的次数最少为一次(即根结点就是待查的结点),最多为树的深度,所以平均查找次数要小于树的深度。若查找成功,则是从根结点出发走了一条从根到待查结点的路径;若查找不成功,则是从根结点出发走了一条从根结点到某个叶子的路径。同二分查找类似,与给定值的比较次数不会超过树的深度。若二又排序树是一棵理想的平衡树或接近理想的平衡树,如图8.6 (g)所示,则进行查找的时间复杂度为O(log2n);若退化为一棵单支树,如图8.8所示,则其查找的时间复杂度为O(n)。对于一般情况,其时间复杂度应为O(log2n),由此可知,在二叉排序树上查找比在线性表上进行顺序查找的时间复杂度O(n)要好得多,这正是构造二叉排序树的主要目的之一。例如,图8.6 (g)所示二叉排序树的平均查找长度为:

而图8.7表示的二叉排序树的平均查找长度为:

3.二叉排序树上的删除
从BST树上删除一个结点,仍然要保证删除后满足BST的性质。设被删除结点为removeNode,其父结点为parent,如图8.8 (a)所示的BST树。具体删除情况分析如下:
(1)若removeNode是叶子结点:直接删除removeNode,如图8.8 (b)所示。
(2)若removeNode只有一棵子树(左子树或右子树),直接用removeNode的左子树(或右子树)取代removeNode的位置而成为parent的一棵子树。即原来removeNode是parent的左子树,则removeNode的子树成为parent的左子树;原来removeNode是parent的右子树,则removeNode的子树成为parent的右子树,如图8.8 (c)所示。
(3)若removeNode既有左子树又有右子树,处理方法有以下两种,可以任选其中一种。
①用removeNode的直接前驱结点代替removeNode,即从removeNode的左子树中选择值最大的结点node放在removeNode的位置(用结点node的内容替换结点removeNode内容),然后删除结点node。node是removeNode的左子树中最右边的结点且设有右子树,对node的删除除同(2),如图8.8 (d)所示。
②用removeNode的直接后继结点代替removeNode,即从removeNode的右子树中选择值最小的结点node放在removeNode的位置(用结点node的内容替换结点removeNode的内容),然后删除结点node,node是removeNode的右子树中的最左边的结点且没有左子树,对node的删除同(2)。例如,对图8.8 (a)所示的二叉排序树,删除结点8后所得的结果如图8.8 (e)所示。
(4)如果删除的是根结点:
①只有一个根节点,直接删除;
②根节点只有一个左子树,将左子树提升为根结点,删除历史根结点;
③根节点只有一个右子树,将右子树提升为根结点,删除历史根结点;
④根结点左右子树都存在:
1.根节点的左子树链接到根节点的直接后继左子树上,根节点右子树成为新的根节点,删除历史根结点;
2.或者根结点的右子树链接到根节点的直接前驱右子树上,根结点的左子树成为新的根结点,删除历史根结点;

二叉树的创建使用第五章5.3.1小节封装的二叉树生成算法。
| #define _CRT_SECURE_NO_WARNINGS //规避C4996告警 #include <stdio.h> #include <stdlib.h> #include "binaryTree.h" struct BinaryNode* find(struct BinaryNode* root, char* data, struct BinaryNode** parent) { if (root == NULL || strcmp(root->data, data) == 0) { return root; } *parent = root; if (strcmp(data, root->data) > 0) { find(root->right, data, parent); } else { find(root->left, data, parent); } } int removeTreeNode(struct BinaryNode* parent, struct BinaryNode* removeNode) { int flag = -1; if (parent->left == removeNode) { flag = 1; } else { flag = 0; } if (removeNode->left == NULL && removeNode->right == NULL) { if (flag) { parent->left = NULL; } else { parent->right = NULL; } } else if (removeNode->left == NULL && removeNode->right != NULL) { if (flag) { parent->left = removeNode->right; } else { parent->right = removeNode->right; } } else if (removeNode->left != NULL && removeNode->right == NULL) { if (flag) { parent->left = removeNode->left; } else { parent->right = removeNode->left; } } else { struct BinaryNode* node = removeNode->left; struct BinaryNode* front = removeNode; while (node->right != NULL) { front = node; node = node->right; } removeNode->data = node->data; return removeTreeNode(front, node); } free(removeNode); removeNode = NULL; return 1; } int getTreeDepth(struct BinaryNode* root, int depth) { if (root == NULL) { return --depth; } int left = getTreeDepth(root->left, depth + 1); int right = getTreeDepth(root->right, depth + 1); return left > right? left:right; } int removeData(struct BinaryTree* tree, char* data) { struct BinaryNode* parent = NULL; struct BinaryNode* removeNode = find(tree->root, data, &parent); if (removeNode == NULL) { printf("删除元素%s不存在!", data); return 0; } if (parent == NULL) { if (removeNode->left != NULL && removeNode->right == NULL) { tree->root = removeNode->left; } else if (removeNode->left == NULL && removeNode->right != NULL) { tree->root = removeNode->right; } else { struct BinaryNode* node = removeNode->right; while (node->left != NULL) { node = node->left; } node->left = removeNode->left; tree->root = removeNode->right; } free(removeNode); removeNode = NULL; tree->depth = getTreeDepth(tree->root, 1); return 1; } int result = removeTreeNode(parent, removeNode); tree->depth = getTreeDepth(tree->root, 1); return result; } int main() { struct BinaryTree* tree = initEmtpyBinaryTree(); tree->insert("35", tree); tree->insert("65", tree); tree->insert("53", tree); tree->insert("18", tree); tree->insert("26", tree); tree->insert("32", tree); tree->draw(tree); char* data = "26"; printf("元素值删除%s!\n", removeData(tree, data) ? "成功" : "失败"); tree->draw(tree); return 0; } |
运行结果:
| 35 / \ 18 65 / \ / \ * 26 53 * / \ / \ / \ / \ * * * 32 * * * * / / / \/ / / / / \ 元素值删除成功! 35 / \ 18 65 / \ / \ * 32 53 * / \/ \/ / \ |
将二叉排序树删除算法封装到第五章5.3.1小节封装的二叉树生成算法中。
| .h文件: struct BinaryTree { ... ... int (*remove)(char* data, struct BinaryTree* binaryTree); ... ... }; .c文件: int removeTreeData(char* data, struct BinaryTree* binaryTree) { int getTreeDepth(struct BinaryNode* root, int depth); struct BinaryNode* parent = NULL; struct BinaryNode* removeNode = recursionFindData(binaryTree->root, data, &parent); if (removeNode == NULL) { printf("删除元素%s不存在!", data); return 0; } if (parent == NULL) { if (removeNode->left != NULL && removeNode->right == NULL) { binaryTree->root = removeNode->left; } else if (removeNode->left == NULL && removeNode->right != NULL) { binaryTree->root = removeNode->right; } else { struct BinaryNode* node = removeNode->right; while (node->left != NULL) { node = node->left; } node->left = removeNode->left; binaryTree->root = removeNode->right; } free(removeNode); removeNode = NULL; binaryTree->depth = getTreeDepth(binaryTree->root, 1); return 1; } int removeTreeNode(struct BinaryNode* parent, struct BinaryNode* removeNode); int result = removeTreeNode(parent, removeNode); binaryTree->depth = getTreeDepth(binaryTree->root, 1); return result; } int removeTreeNode(struct BinaryNode* parent, struct BinaryNode* removeNode) { int flag = -1; if (parent->left == removeNode) { flag = 1; } else { flag = 0; } if (removeNode->left == NULL && removeNode->right == NULL) { if (flag) { parent->left = NULL; } else { parent->right = NULL; } } else if (removeNode->left == NULL && removeNode->right != NULL) { if (flag) { parent->left = removeNode->right; } else { parent->right = removeNode->right; } } else if (removeNode->left != NULL && removeNode->right == NULL) { if (flag) { parent->left = removeNode->left; } else { parent->right = removeNode->left; } } else { struct BinaryNode* node = removeNode->left; struct BinaryNode* front = removeNode; while (node->right != NULL) { front = node; node = node->right; } removeNode->data = node->data; return removeTreeNode(front, node); } free(removeNode); removeNode = NULL; return 1; } int getTreeDepth(struct BinaryNode* root, int depth) { if (root == NULL) { return --depth; } int left = getTreeDepth(root->left, depth + 1); int right = getTreeDepth(root->right, depth + 1); return left > right ? left : right; } |
测试:
| #define _CRT_SECURE_NO_WARNINGS //规避C4996告警 #include <stdio.h> #include <stdlib.h> #include "binaryTree.h" int main() { struct BinaryTree* tree = initEmtpyBinaryTree(); tree->insert("35", tree); tree->insert("65", tree); tree->insert("53", tree); tree->insert("18", tree); tree->insert("26", tree); tree->insert("32", tree); tree->draw(tree); char* data = "26"; printf("元素值删除%s!\n", tree->remove(data, tree) ? "成功" : "失败"); tree->draw(tree); return 0; } |
【例8.3】 二叉排序树的生成和查找实例详解。已知长度为7的字符串组成的表为
(cat, be, for, more, at, he, can)
按表中元素的次序依次插入,画出插入完成后的二叉排序树,并求其在等概率情况下查找成功的平均查找长度。
分析:二叉排序树的构造过程是通过依次输入数据元素,并把它们插入到二叉树的适当位置上来完成的。具体的步骤是:每读入一个元素,建立一个新结点,若二叉排序树为非空,则将新结点关键字值与根结点关键字值比较,如果小于根结点关键字值,则插入到左子树中,否则插入到右子树中;若二叉排序树为空,则新结点作为二叉树的根结点。如本例给出的表生成二叉排序树的过程为:首先读入第一个元素cat,建立一个新结点,因为二叉排序树为空树,因此该结点作为根结点;接着读入第二个元素be,与根结点的cat比较, be<sat 所以以be为关键字的新结点作为根结点的左子树插入到二叉排序树中;再读入第三个元素for,比根结点关键字值cat大,插入到右子树中;再读第四个元素more,从根比较,比根结点关键字值cat大,应插入到右子树中,而右子树中已有结点存在,因此,再与右子树的根结点比较, more比for大,插入右子树,如此下去,直到所有元素插入完为止,由此可得二叉排序树如图8.9所示。

对于字符串的比较是按其在计算机中的ASCI码进行的,按字母顺序,排在前面的小,排在后面的大,如"a" <"b"。
由于在二叉排序树上查找时关键字的比较次数不会超过树的深度,即查找结点与其所在层数有关,第一层,需比较一次,第二层的只需要比较两次······所以在等概率情况下,以上所求二叉排序树的平均查找长度为:
ASL=(1+2x2+3×3+4X1)/7=18/7≈2.57
8.2.2.平衡二叉树
虽然二叉排序树上实现插入和查找等操作的平均时间复杂度为O(log2n),但在最坏情况下,由于树的深度为n,这时的基本操作时间复杂度也就会增加至O(n)。为了避免这种情况的发生,人们研究了多种动态平衡的方法,使得向树中插入或删除结点时,通过调整树的形态来保持树的平衡,使其既满足BST性质又保证二叉排序树的深度在任何情况下均为O(log2n),这种二叉排序树就是所谓的平衡二叉树。
问题:如何提高形态不均衡的二叉排序树的查找效率?解决办法:做"平衡化”处理,即尽量让二叉树的形态均衡!
1.概念
平衡二叉树(balanced binary tree)又称AVL树(Adelson-Velskii and Landis)
一棵平衡二叉树或者是空树,或者是具有下列性质的二叉排序树:
①左子树与右子树的高度之差的绝对值小于等于1;
②左子树和右子树也是平衡二叉排序树。
为了方便起见,给每个结点附加一个数字,给出该结点左子树与右子树的高度差。这个数字称为结点的平衡因子(BF)。
平衡因子=结点左子树的高度-结点右子树的高度
根据平衡二叉树的定义,平衡二叉树上所有结点的平衡因子只能是-1、0或1。

对于一棵有n个结点的AVL树,其高度保持在O(log2n)数量级。
当我们在一个平衡二叉排序树上插入一个结点时,有可能导致失衡,即出现平衡因子绝对值大于1的结点,如: 2、-2。

如果在一颗AVL树中插入一个新的结点后造成失衡,则必须重新调整树的结构,使之恢复平衡。

2.平衡调整

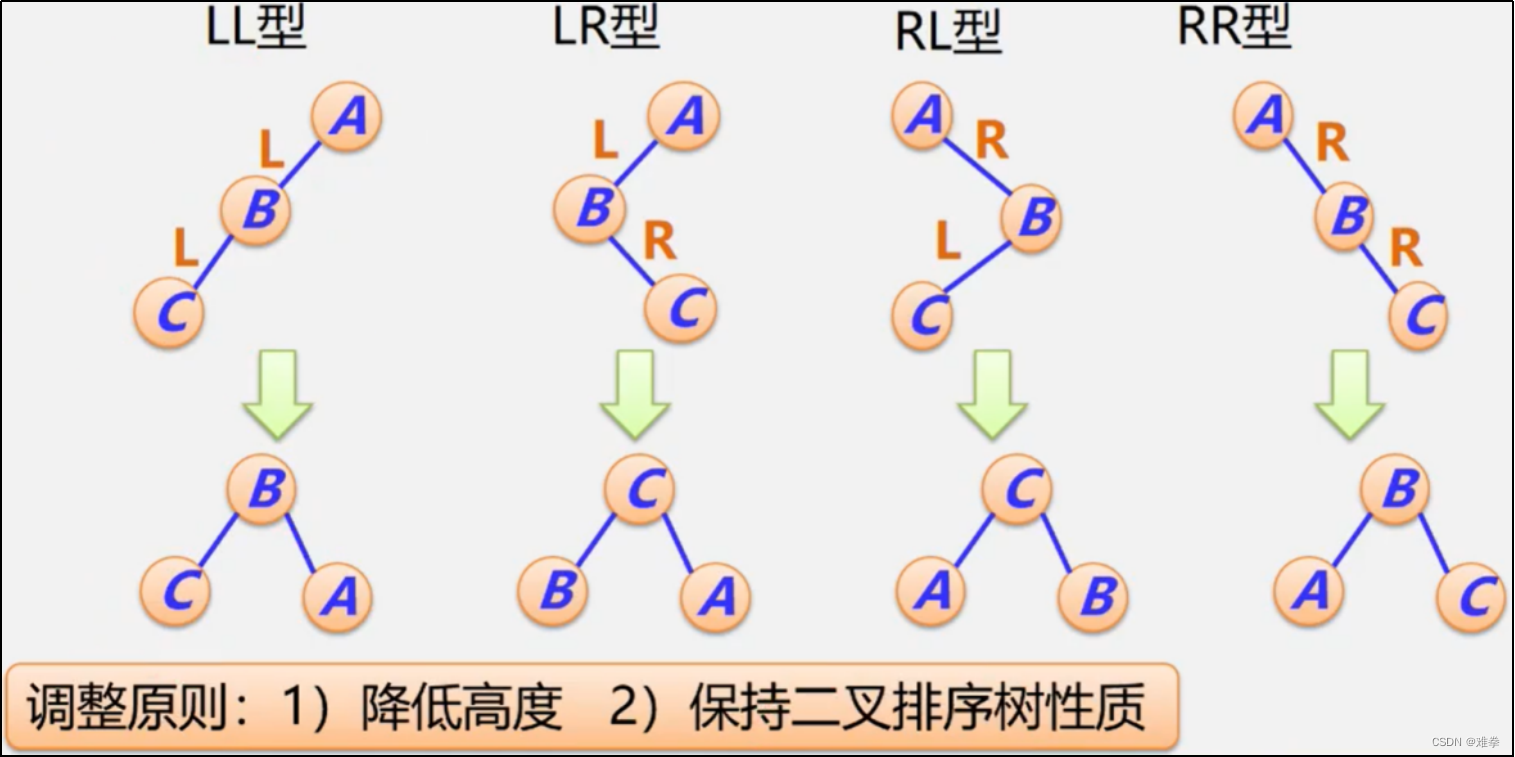
(1)LL型调整

调整过程
 · B结点带左子树α一起上升
· B结点带左子树α一起上升
· A结点成为B的右孩子
· 原来B结点的右子树β作为A的左子树

AVL树LL调整--例:

(2)RR型调整

调整过程

· B结点带左子树β一起上升
· A结点成为B的左孩子
· 原来B结点的左子树α作为A的左子树

AVL树RR调整--例:


(3)LR型调整

LR调整过程
· C结点穿过A、B结点上升
· B结点成为C的左孩子,A结点成为C的右孩子
· 原来C结点的左子树β作为B的右子树

AVL树LR调整--例:

(3)RL型调整
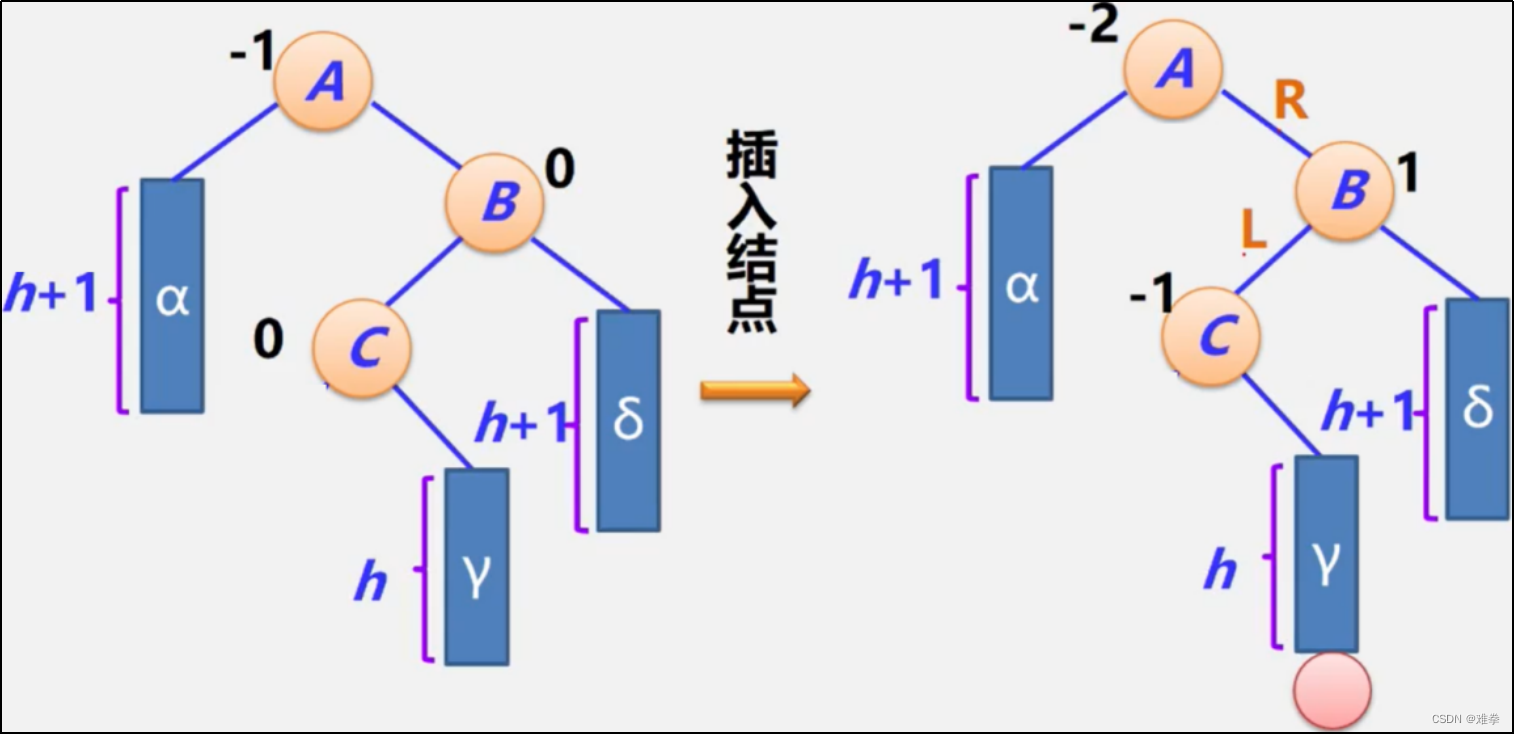
RL调整过程
· C结点穿过A、B结点上升
· B结点成为C的右孩子,A结点成为C的左孩子
· 原来C结点的左子树γ作为B的左子树
AVL树RL调整--例:


首先为了方便计算树的高度差在树结点中增加了当前结点的深度值depth,为了方便旋转树结点,在结点中增加了父结点指针。
| struct BinaryNode { char* data; int depth; struct BinaryNode* parent; struct BinaryNode* left; struct BinaryNode* right; }; |
根据上述理论修改二叉排序树的插入算法,使二叉排序树始终保持为一棵平衡二叉树。
| void insertBinaryTree(char* data, struct BinaryTree* binaryTree) { if (binaryTree == NULL) { #if PRINT printf("二叉树不存在!\n"); #endif return; } if (data == NULL) { #if PRINT printf("插入二叉树数值为空!\n"); #endif return; } struct BinaryNode* binaryNode = malloc(sizeof(struct BinaryNode)); if (binaryNode == NULL) { #if PRINT printf("创建二叉树结点失败,内存空间不足!\n"); #endif return; } binaryNode->data = data; binaryNode->left = NULL; binaryNode->right = NULL; if (binaryTree->root == NULL) { binaryNode->depth = 1; binaryNode->parent = NULL; binaryTree->root = binaryNode; return; } struct BinaryNode* pointer = binaryTree->root; struct BinaryNode* front = NULL; int depth = 1; while (pointer != NULL) { front = pointer; depth++; if (stringCompare(data, pointer->data) > 0) { pointer = pointer->right; } else if (stringCompare(data, pointer->data) == 0) { #if PRINT printf("插入二叉树数据%s已存在!\n", data); #endif return; } else { pointer = pointer->left; } } binaryTree->depth = binaryTree->depth > depth ? binaryTree->depth : depth; binaryNode->depth = depth; binaryNode->parent = front; if (stringCompare(data, front->data) > 0) { front->right = binaryNode; } else { front->left = binaryNode; } struct SequenceStack* stack = initSequenceStack(); stack = examineBalancedTree(binaryTree->root, 1, stack); while (stack->size(stack) > 0) { revolveTree(binaryTree, stack); stack = examineBalancedTree(binaryTree->root, 1, stack); } stack->destroy(stack); binaryTree->depth = getTreeDepth(binaryTree->root, 1); } struct StackBinaryNode { int isLeftDepth; struct BinaryNode* node; }; int getTreeDepth(struct BinaryNode* root, int depth); // removeTreeData::getTreeDepth struct SequenceStack* examineBalancedTree(struct BinaryNode* node, int depth, struct SequenceStack* stack) { if (node == NULL) { return stack; } int left = getTreeDepth(node->left, depth + 1); int right = getTreeDepth(node->right, depth + 1); if (abs(left - right) > 1) { struct StackBinaryNode* stackNode = malloc(sizeof(struct StackBinaryNode)); stackNode->node = node; if (left > right) { stackNode->isLeftDepth = 1; } else { stackNode->isLeftDepth = 0; } stack->push(stackNode, stack); } examineBalancedTree(node->left, depth, stack); examineBalancedTree(node->right, depth, stack); return stack; } void revolveTree(struct BinaryTree* binaryTree, struct SequenceStack* stack) { if (stack != NULL && stack->size(stack) > 0) { struct StackBinaryNode* stackNode = stack->top(stack); stack->pop(stack); int size = stack->size(stack); struct StackBinaryNode** stackArray = stack->clear(stack); for (int i =0; i< size; i++) { free(stackArray[i]); stackArray[i] = NULL; } struct BinaryNode* node = stackNode->node; int isLeftDepth = stackNode->isLeftDepth; free(stackNode); stackNode = NULL; if (isLeftDepth) { if (node->left->left != NULL) { node = node->left->left; revolveTreeLL(binaryTree, node); return; } else if (node->left->right != NULL) { node = node->left->right; revolveTreeLR(binaryTree, node); return; } } else { if (node->right->left != NULL) { node = node->right->left; revolveTreeRL(binaryTree, node); return; } else if (node->right->right != NULL) { node = node->right->right; revolveTreeRR(binaryTree, node); return; } } } } void moveDepthMark(struct BinaryNode* root, int depth); // removeTreeData::moveDepthMark void revolveTreeLL(struct BinaryTree* binaryTree, struct BinaryNode* node) { struct BinaryNode* parent = node->parent->parent->parent; struct BinaryNode* right = node->parent->parent; struct BinaryNode* root = node->parent; if (root->right != NULL) { right->left = root->right; } else { right->left = NULL; } root->right = right; right->parent = root; moveDepthMark(root, root->depth - 1); if (parent == NULL) { binaryTree->root = root; root->parent = NULL; return; } root->parent = parent; if (parent->left == right) { parent->left = root; } else { parent->right = root; } } void revolveTreeRR(struct BinaryTree* binaryTree, struct BinaryNode* node) { struct BinaryNode* parent = node->parent->parent->parent; struct BinaryNode* left = node->parent->parent; struct BinaryNode* root = node->parent; if (root->left != NULL) { left->right = root->left; } else { left->right = NULL; } root->left = left; left->parent = root; moveDepthMark(root, root->depth - 1); if (parent == NULL) { binaryTree->root = root; root->parent = NULL; return; } root->parent = parent; if (parent->left == left) { parent->left = root; } else { parent->right = root; } } void revolveTreeLR(struct BinaryTree* binaryTree, struct BinaryNode* node) { struct BinaryNode* parent = node->parent->parent->parent; struct BinaryNode* right = node->parent->parent; struct BinaryNode* left = node->parent; if (node->left != NULL) { left->right = node->left; right->left = NULL; } else { right->left = node->right; left->right = NULL; } node->left = left; left->parent = node; node->right = right; moveDepthMark(node, node->depth - 2); if (parent == NULL) { binaryTree->root = node; node->parent = NULL; return; } node->parent = parent; if (parent->left == right) { parent->left = node; } else { parent->right = node; } } void revolveTreeRL(struct BinaryTree* binaryTree, struct BinaryNode* node) { struct BinaryNode* parent = node->parent->parent->parent; struct BinaryNode* left = node->parent->parent; struct BinaryNode* right = node->parent; if (node->left != NULL) { left->right = node->left; right->left = NULL; } else { right->left = node->right; left->right = NULL; } node->left = left; left->parent = node; node->right = right; right->parent = node; moveDepthMark(node, node->depth - 2); if (parent == NULL) { binaryTree->root = node; node->parent = NULL; return; } node->parent = parent; if (parent->left == left) { parent->left = node; } else { parent->right = node; } } |
测试:
| #define _CRT_SECURE_NO_WARNINGS //规避C4996告警 #include <stdio.h> #include <stdlib.h> #include "binaryTree.h" int main() { struct BinaryTree* tree = initEmtpyBinaryTree(); tree->insert("10", tree); tree->insert("9", tree); tree->insert("8", tree); tree->insert("7", tree); tree->insert("6", tree); tree->insert("5", tree); tree->insert("4", tree); tree->insert("3", tree); tree->insert("2", tree); tree->insert("1", tree); tree->draw(tree); tree = initEmtpyBinaryTree(); tree->insert("1", tree); tree->insert("2", tree); tree->insert("3", tree); tree->insert("4", tree); tree->insert("5", tree); tree->insert("6", tree); tree->insert("7", tree); tree->insert("8", tree); tree->insert("9", tree); tree->insert("10", tree); tree->draw(tree); return 0; } |
测试结果,无论正序还是倒叙插入数据,二叉树始终保持平衡。
| 7 / \ 3 9 / \ / \ 2 5 8 10 / \ / \ / \ / \ 1 * 4 6 * * * * / / / / / / / / \ 5 / \ 3 7 / \ / \ 2 4 6 9 / \ / \ / \ / \ 1 * * * * * 8 10 / / / / / / / \/ \ |
修改删除逻辑,在删除树中结点时,修改结点的深度值depth和修改结点的父结点指针。
| int removeTreeNode(struct BinaryNode* parent, struct BinaryNode* removeNode); int getTreeDepth(struct BinaryNode* root, int depth); void moveDepthMark(struct BinaryNode* root, int depth); int removeTreeData(char* data, struct BinaryTree* binaryTree) { struct BinaryNode* parent = NULL; struct BinaryNode* removeNode = recursionFindData(binaryTree->root, data, &parent); if (removeNode == NULL) { printf("删除元素%s不存在!", data); return 0; } if (parent == NULL) { if (removeNode->left != NULL && removeNode->right == NULL) { binaryTree->root = removeNode->left; removeNode->left->parent = NULL; moveDepthMark(removeNode->left, 1); } else if (removeNode->left == NULL && removeNode->right != NULL) { binaryTree->root = removeNode->right; removeNode->right->parent = NULL; moveDepthMark(removeNode->right, 1); } else { struct BinaryNode* node = removeNode->right; moveDepthMark(removeNode->right, removeNode->depth); while (node->left != NULL) { node = node->left; } node->left = removeNode->left; removeNode->left->parent = node; binaryTree->root = removeNode->right; removeNode->right->parent = NULL; moveDepthMark(node, node->depth); } free(removeNode); removeNode = NULL; } else { removeTreeNode(parent, removeNode); } struct SequenceStack* stack = initSequenceStack(); stack = examineBalancedTree(binaryTree->root, 1, stack); while (stack->size(stack) > 0) { revolveTree(binaryTree, stack); stack = examineBalancedTree(binaryTree->root, 1, stack); } stack->destroy(stack); binaryTree->depth = getTreeDepth(binaryTree->root, 1); return 1; } int removeTreeNode(struct BinaryNode* parent, struct BinaryNode* removeNode) { int flag = -1; if (parent->left == removeNode) { flag = 1; } else { flag = 0; } if (removeNode->left == NULL && removeNode->right == NULL) { if (flag) { parent->left = NULL; } else { parent->right = NULL; } } else if (removeNode->left == NULL && removeNode->right != NULL) { if (flag) { parent->left = removeNode->right; } else { parent->right = removeNode->right; } removeNode->right->parent = parent; moveDepthMark(removeNode->right, removeNode->depth); } else if (removeNode->left != NULL && removeNode->right == NULL) { if (flag) { parent->left = removeNode->left; } else { parent->right = removeNode->left; } removeNode->left->parent = parent; moveDepthMark(removeNode->left, removeNode->depth); } else { struct BinaryNode* node = removeNode->left; struct BinaryNode* front = removeNode; while (node->right != NULL) { front = node; node = node->right; } removeNode->data = node->data; return removeTreeNode(front, node); } free(removeNode); removeNode = NULL; return 1; } void moveDepthMark(struct BinaryNode* root, int depth) { if (root == NULL) { return; } root->depth = depth; moveDepthMark(root->left, depth + 1); moveDepthMark(root->right, depth + 1); } int getTreeDepth(struct BinaryNode* root, int depth) { if (root == NULL) { return --depth; } int left = getTreeDepth(root->left, depth + 1); int right = getTreeDepth(root->right, depth + 1); return left > right ? left : right; } |
测试:
| #define _CRT_SECURE_NO_WARNINGS //规避C4996告警 #include <stdio.h> #include <stdlib.h> #include "binaryTree.h" int main() { struct BinaryTree* tree = initEmtpyBinaryTree(); tree->insert("10", tree); tree->insert("9", tree); tree->insert("8", tree); tree->insert("7", tree); tree->insert("6", tree); tree->insert("5", tree); tree->insert("4", tree); tree->insert("3", tree); tree->insert("2", tree); tree->insert("1", tree); tree->draw(tree); tree->remove("5", tree); tree->draw(tree); tree->remove("8", tree); tree->remove("10", tree); tree->draw(tree); // tree = initEmtpyBinaryTree(); // tree->insert("1", tree); // tree->insert("2", tree); // tree->insert("3", tree); // tree->insert("4", tree); // tree->insert("5", tree); // tree->insert("6", tree); // tree->insert("7", tree); // tree->insert("8", tree); // tree->insert("9", tree); // tree->insert("10", tree); // tree->draw(tree); // // tree->remove("9", tree); // tree->draw(tree); return 0; } |
测试结果,无论是删除结点还是从中间删除二叉排序树始终保持平衡:

注意:完整代码见5.4.3.封装二叉树算法。
例题:输入关键字序列(16,3,7,11,9,26,18,14,15),给出构造一颗AVL树的步骤。





8.3.3.B树(多路查找树)
B树是一种平衡的多路查找树,它在文件系统中非常有用。在本节中将介绍B树的存储结构及其基本运算。
1.B树的定义
一棵m (m≥3)阶的B树,或为空树,或为满足下列性质的m叉树:
(1)每个结点至少包含下列信息域:
(n, p0,k1,p1,k2,···,kn,pn)
其中, n为关键字的个数; ki(1≤i≤n)为关键字,且ki<ki+1 (1≤i≤n-1); pi (0≤i≤n)为指向子树根结点的指针,且pi所指向子树中所有结点的关键字均小于ki+1, pn所指子树中所有结点关键字均大于kn;
(2)树中每个结点至多有m棵子树。
(3)若树为非空,则根结点至少有1个关键字,至多有m-1个关键字。因此,若根结点不是叶子,则它至少有两棵子树。
(4)所有的叶结点都在同一层上,并且不带信息(可以看作是外部结点或查找矢败的结点,实际上这些结点不存在,指向它们的指针均为空),叶子的层数为树的高度h。
(5)每个非根结点中所包含的关键字个数满足:{m/2}向上取整-1≤n≤m-1。因为每个内部结点的度数(结点子树个数)正好是关键字总数加1,所以,除根结点之外的所有非终端结点(非叶子结点的最下层的结点称为终端结点)至少有{m/2}向上取整棵子树,至多有m棵子树。
例如,如图8.10所示为一棵4阶的B树,其深度为3。当然,同二叉排序树一样,关键字插入的次序不同,将可能生成不同结构的B树。该树共三层,所有叶子结点均在第三层上。在一棵4阶的B树中,每个结点的关键字个数最少为

最多为m-1=4-1=3;每个结点的子树数目最少为

最多为m=4。

B树的结点类型定义如下:
| struct TreeNode { int keyNum; char* keys; int poNum; char* pointers; struct TreeNode* parent; }; |
创建B树头文件:
| #pragma once #ifndef BALANCE_TREE_H #define BALANCE_TREE_H #include <Windows.h> #include "string.h" struct BalanceTree { int size; int nodeSize; struct BalanceNode* root; void (*draw)(struct BalanceTree* balanceTree); }; struct BalanceTree* initBalanceTree(int nodeSize); #endif |
初始化一个空的B树,实现B树绘图算法:
| #define _CRT_SECURE_NO_WARNINGS //规避C4996告警 #include <stdio.h> #include <stdlib.h> #include "balanceTree.h" #define PRINT 1 #define DRAW_BALANCE_NODE 1 struct BalanceNode { int keyNum; char** keys; int poNum; struct BalanceNode** pointers; struct BalanceNode* parent; }; void drawBalanceTree(struct BalanceTree* balanceTree); struct BalanceTree* initBalanceTree(int nodeSize) { struct BalanceTree* tree = malloc(sizeof(struct BalanceTree)); if (tree == NULL) { #ifdef PRINT printf("创建平衡多路查找树失败,内存空间不足!"); #endif return NULL; } tree->size = 0; tree->size = 0; tree->nodeSize = nodeSize; tree->root = NULL; tree->draw = drawBalanceTree; tree->insert = insertBalanceNode; return tree; } void printBalanceNode(struct BalanceNode* balanceNode, int nodeSize); int getBalanceNodeDepth(struct BalanceNode* balanceNode, int depth); void drawBalanceTree(struct BalanceTree* balanceTree) { if (balanceTree == NULL || balanceTree->root == NULL) { #ifdef PRINT printf("平衡多路查找树为空或不存在!\n"); #endif return; } #ifdef DRAW_BALANCE_NODE struct BalanceNode* balanceNode = balanceTree->root; printBalanceNode(balanceTree->root, balanceTree->nodeSize); int depth = getBalanceNodeDepth(balanceNode, 1); CONSOLE_SCREEN_BUFFER_INFO ipBuffer; GetConsoleScreenBufferInfo(GetStdHandle(STD_OUTPUT_HANDLE), &ipBuffer); COORD coord = { 0 }; coord.X = 0; coord.Y = ipBuffer.dwCursorPosition.Y + depth * 2; SetConsoleCursorPosition(GetStdHandle(STD_OUTPUT_HANDLE), coord); #endif } void printBalanceNode(struct BalanceNode* balanceNode, int nodeSize) { int depth = getBalanceNodeDepth(balanceNode, 0); int blank = depth * (nodeSize + 2) * 4; if (depth == 0) { blank = 0; } while (blank) { printf(" "); blank--; } int entity = nodeSize + 1; int pointer = 0; if (balanceNode->parent == NULL) { printf("%s↓", "#"); } else { printf("%s↓", balanceNode->parent->keys[0]); } printf("%d↓", balanceNode->keyNum); while (entity && pointer < balanceNode->keyNum) { printf("%s", balanceNode->keys[pointer]); printf("↓"); pointer++; } CONSOLE_SCREEN_BUFFER_INFO ipBuffer; GetConsoleScreenBufferInfo(GetStdHandle(STD_OUTPUT_HANDLE), &ipBuffer); COORD coord = { 0 }; coord.X = ipBuffer.dwCursorPosition.X - 1; coord.Y = ipBuffer.dwCursorPosition.Y + 1; SetConsoleCursorPosition(GetStdHandle(STD_OUTPUT_HANDLE), coord); printf("\\"); coord.X = ipBuffer.dwCursorPosition.X - balanceNode->keyNum * 1.5 - 1; SetConsoleCursorPosition(GetStdHandle(STD_OUTPUT_HANDLE), coord); printf("↓"); coord.X = ipBuffer.dwCursorPosition.X - balanceNode->keyNum * 2.5 - 2; SetConsoleCursorPosition(GetStdHandle(STD_OUTPUT_HANDLE), coord); printf("↓"); coord.X = ipBuffer.dwCursorPosition.X - balanceNode->keyNum * 3.5 - 3; SetConsoleCursorPosition(GetStdHandle(STD_OUTPUT_HANDLE), coord); printf("/"); int move = (nodeSize + 2) * 4 + balanceNode->keyNum * 2 + balanceNode->poNum * 2; if (depth > 0) { move *= depth; } coord.X = (ipBuffer.dwCursorPosition.X >= move ? ipBuffer.dwCursorPosition.X - move : 0); coord.Y = ipBuffer.dwCursorPosition.Y + 2; SetConsoleCursorPosition(GetStdHandle(STD_OUTPUT_HANDLE), coord); int child = 0; while (child < balanceNode->poNum) { struct BalanceNode* childNode = balanceNode->pointers[child]; printBalanceNode(childNode, nodeSize); child++; if (child >= balanceNode->poNum) { break; } if ((childNode->keyNum + childNode->poNum) < (nodeSize * 2 + 1)) { int moveBlank = nodeSize * 2 - (childNode->keyNum + childNode->poNum); if (depth > 1) { moveBlank = depth * nodeSize * 3; } while (moveBlank > 0) { printf(" "); moveBlank--; } } } coord.X = ipBuffer.dwCursorPosition.X + 1; coord.Y = ipBuffer.dwCursorPosition.Y; SetConsoleCursorPosition(GetStdHandle(STD_OUTPUT_HANDLE), coord); } int getBalanceNodeDepth(struct BalanceNode* balanceNode, int depth) { while (balanceNode->pointers[0] != NULL) { depth++; balanceNode = balanceNode->pointers[0]; } return depth; } |
2.B树上的插入和删除
在B树上插入和删除元素的运算比较复杂,它要求进行运算后的结点中

因此,涉及结点的分裂和合并问题。对于在B树中插入一个关键字;不是在树中添加一个叶结点,而是先在最低层的某个非终端结点中添加一个关键字。若该结点中关键字的个数不超过m-1,则插入完成,否则要产生结点“分裂”。“分裂”结点时把结点分成两个,将中间的一个关键字拿出来插入到该结点的双亲结点上,如果双亲结点中已有m-1个关键字,则插入后将引起双亲结点的分裂,这一过程可能波及B树的根结点,引起根结点的分裂,从而使B树长高一层。
B树插入算法实现:
1.在插入新的元素之前先在B树上寻找插入点;
| struct ResultBalanceInfo { struct BalanceNode* balanceNode; int index; int tag; }; int searchBalanceIndex(struct BalanceNode* balanceNode, char* data); struct ResultBalanceInfo* findBalanceNode(char* data, struct BalanceTree* balanceTree) { struct BalanceNode* balanceNode = balanceTree->root; struct BalanceNode* parent = NULL; int found = 0, index = 0; while (balanceNode != NULL && found == 0) { index = searchBalanceIndex(balanceNode, data); if (index > 0 && index <= balanceNode->keyNum && stringCompare(balanceNode->keys[index - 1], data) == 0) { index = index - 1; found = 1; } else { parent = balanceNode; balanceNode = balanceNode->pointers[index]; } } struct ResultBalanceInfo* result = malloc(sizeof(struct ResultBalanceInfo)); if (result == NULL) { #ifdef PRINT printf("搜索节点创建返回值对象,开辟内存失败!\n"); #endif return NULL; } result->index = index; if (found == 1) { result->balanceNode = balanceNode; result->tag = 1; } else { result->balanceNode = parent; result->tag = 0; } return result; } |
2.插入新的元素:
| struct BalanceNode* initBalanceNode(int nodeSize); void setBalanceNode(struct BalanceNode** root, char* data, struct BalanceNode* balanceNode, int index, int nodeSize); int insertBalanceNode(char* data, struct BalanceTree* balanceTree) { if (balanceTree == NULL) { #ifdef PRINT printf("平衡多路查找树不存在!"); #endif return NULL; } if (data == NULL) { #ifdef PRINT printf("插入数据不存在!"); #endif return NULL; } struct BalanceNode* root = balanceTree->root; if (root == NULL) { root = initBalanceNode(balanceTree->nodeSize); balanceTree->root = root; root->keys[root->keyNum++] = data; balanceTree->size++; return 1; } struct ResultBalanceInfo* result = findBalanceNode(data, balanceTree); setBalanceNode(&balanceTree->root, data, result->balanceNode, result->index, balanceTree->nodeSize); free(result); result = NULL; } struct BalanceNode* initBalanceNode(int nodeSize) { struct BalanceNode* balanceNode = malloc(sizeof(struct BalanceNode)); if (balanceNode == NULL) { #ifdef PRINT printf("创建平衡多路查找树结点失败,开辟内存失败!\n"); #endif return NULL; } char** keys = calloc(nodeSize, sizeof(char*)); struct BalanceNode** pointers = calloc(nodeSize + 1, sizeof(struct BalanceNode*)); if (keys == NULL || pointers == NULL) { #ifdef PRINT printf("创建平衡多路查找树结点存储结构失败,开辟内存失败!\n"); #endif return NULL; } balanceNode->keyNum = 0; balanceNode->keys = keys; balanceNode->poNum = 0; balanceNode->pointers = pointers; balanceNode->parent = NULL; } void setBalanceData(struct BalanceNode* balanceNode, int index, char* data, int nodeSize); void splitBrotherNode(struct BalanceNode** root, struct BalanceNode* balanceNode, int nodeSize); void setBalanceNode(struct BalanceNode** root, char* data, struct BalanceNode* balanceNode, int index, int nodeSize) { if (balanceNode->keyNum < nodeSize) { setBalanceData(balanceNode, index, data, nodeSize); if (balanceNode->keyNum < nodeSize) return; if (balanceNode->keyNum == nodeSize) { splitBrotherNode(root, balanceNode, nodeSize); } } else { #ifdef PRINT printf("插入节点数据时,空间不足!\n"); #endif return; } } void setBalanceData(struct BalanceNode* balanceNode, int index, char* data, int nodeSize) { int size = balanceNode->keyNum; if (size == nodeSize) { printf("数值越界\n"); } for (int i = size; i > index; i--) { balanceNode->keys[i] = balanceNode->keys[i - 1]; balanceNode->pointers[i] = balanceNode->pointers[i - 1]; } balanceNode->keys[index] = data; balanceNode->keyNum++; } |
如果插入后当前节点已经大于(m-1),就要分裂成两棵子树;分裂前节点的中间值上升交给父节点,如果父节点因为得到新的值而被插满,则父节点也要进行节点分裂算法:
| void splitBrotherBrother(struct BalanceNode* balanceNode, int midIndex, struct BalanceNode** brother, int nodeSize); struct BalanceNode* splitBrotherParent(struct BalanceNode** root, struct BalanceNode* balanceNode, struct BalanceNode* brother, char* parentData, int nodeSize); void splitBrotherNode(struct BalanceNode** root, struct BalanceNode* balanceNode, int nodeSize) { int midIndex = nodeSize / 2; struct BalanceNode* brother = NULL; splitBrotherBrother(balanceNode, midIndex, &brother, nodeSize); char* parentData = balanceNode->keys[midIndex]; balanceNode->keys[midIndex] = NULL; balanceNode->keyNum--; struct BalanceNode* parent = splitBrotherParent(root, balanceNode, brother, parentData, nodeSize); if (parent->keyNum >= nodeSize) { splitBrotherNode(root, parent, nodeSize); } } void splitBrotherBrother(struct BalanceNode* balanceNode, int midIndex, struct BalanceNode** brother, int nodeSize) { (*brother) = initBalanceNode(nodeSize); for (int i = midIndex + 1; i <= nodeSize; i++) { int pointIndex = i - (midIndex + 1); (*brother)->pointers[pointIndex] = balanceNode->pointers[i]; if ((*brother)->pointers[pointIndex] != NULL) { (*brother)->poNum++; balanceNode->poNum--; (*brother)->pointers[pointIndex]->parent = (*brother); } if (i < nodeSize) { (*brother)->keys[pointIndex] = balanceNode->keys[i]; } } (*brother)->parent = balanceNode->parent; (*brother)->keyNum = balanceNode->keyNum - (midIndex + 1); balanceNode->keyNum = midIndex + 1; } struct BalanceNode* splitBrotherParent(struct BalanceNode** root, struct BalanceNode* balanceNode, struct BalanceNode* brother, char* parentData, int nodeSize) { struct BalanceNode* parent = balanceNode->parent; if (balanceNode->parent == NULL) { parent = initBalanceNode(nodeSize); parent->keys[parent->keyNum++] = parentData; *root = parent; parent->pointers[parent->poNum++] = balanceNode; balanceNode->parent = parent; parent->pointers[parent->poNum++] = brother; brother->parent = parent; } else { int index = searchBalanceIndex(parent, parentData); for (int i = parent->keyNum; i > index; i--) { parent->keys[i] = parent->keys[i - 1]; parent->pointers[i + 1] = parent->pointers[i]; } parent->keys[index] = parentData; parent->keyNum++; parent->pointers[index + 1] = brother; parent->poNum++; } return parent; } |
测试插入数据:
| #define _CRT_SECURE_NO_WARNINGS //规避C4996告警 #include <stdio.h> #include <stdlib.h> #include "balanceTree.h" int main() { struct BalanceTree* tree = initBalanceTree(3); tree->insert("10", tree); tree->insert("20", tree); tree->insert("30", tree); tree->insert("40", tree); tree->insert("50", tree); tree->insert("60", tree); tree->insert("70", tree); tree->insert("80", tree); tree->insert("90", tree); tree->insert("15", tree); tree->insert("25", tree); tree->insert("45", tree); tree->insert("75", tree); tree->insert("95", tree); tree->insert("35", tree); tree->insert("36", tree); tree->insert("96", tree); tree->insert("97", tree); tree->insert("98", tree); tree->insert("99", tree); tree->insert("76", tree); tree->draw(tree); return 0; } |
测试结果生成了一个3阶高度为3节点数为13的B树,每个节点显示的格式为:
父节点第一个元素|节点数值个数|第一个元素|第二个元素|第三个元素|

【例8.4】试画出将关键字序列: 24, 45, 53, 90, 3, 50, 30, 61, 12, 70, 100依次插入一棵初始为空的4阶B树中的过程。
分析:因为要求生成的是4阶B树,即m=4,当3个关键字24, 45, 53插入到一个新结点时,它既是根结点又是叶结点,因此得: [24 45 53]。当插入第4个关键字90时,关键字数等于4,此时违反了B树的性质,因此根据B树插入算法,将该结点以,中间位置上的关键字

为划分点,并将中间关键字45插入当前结点的双亲结点上,如图8.11 (a)所示。以下的几个关键字的插入相类似,分别如图8.11中图(b)、(c)和(d)所示。当第8个关键字61插入时,按算法应插入到结点[50 53 9]中,此时的结点关键字数已等于4,所以要产生分裂,即将结点中第2个关键字53插入到双亲结点上,并依此位置分裂为50和61 90两个结点,如图8.11 (e)所示。同理可得到图8.11 (f)、图8.11 (g)和图8.11 (h)。

代码插入算法与上图有一些差别,主要差别是在做分裂时,上图偏向右边分裂的元素多,代码中偏向左边分裂的元素多。
| #define _CRT_SECURE_NO_WARNINGS //规避C4996告警 #include <stdio.h> #include <stdlib.h> #include "balanceTree.h" int main() { struct BalanceTree* tree = initBalanceTree(4); //24, 45, 53, 90, 3, 50, 30, 61, 12, 70, 100 tree->insert("24", tree); tree->insert("45", tree); tree->insert("53", tree); tree->insert("90", tree); tree->insert("3", tree); tree->insert("50", tree); tree->insert("30", tree); tree->insert("61", tree); tree->insert("12", tree); tree->insert("70", tree); tree->insert("100", tree); tree->draw(tree); return 0; } |
运行结果:

同样,删除过程与插入类似,只是稍为复杂一点。在B树删除一个关键字,首先找到该关键字所在的结点,再进行关键字的删除。若所删关键字所在结点不在含有信息的最后一层上,即不是在叶子结点中,则将该关键字用其在B树中的后继来替代,然后再删除其后继信息。例如,在图8.12所示的B树上删除24,可以用该关键字的后继30替代24,然后再删除24,因此,只需要讨论删除最下层非终端结点中关键字的情形。

(1)若需删除关键字所在结点中的关键字数目不小于{m/2}向上取整,则只需要删除该结点中关键字ki和相应的指针pi,即删除操作结束。例如,在图8.12所示的B树上删除关键字3后, B树如图8.13所示。

(2)若需删除关键字所在结点中关键字数目等于{m/2}向上取整-1,即关键字数目已是最小值,直接删除该关键字会破坏B树的性质。
• 若所删结点的左(或右)邻兄弟结点中的关键字数目不小于{m/2}向上取整,则将其兄弟结点中的最大(或最小)的关键字上移至双亲结点中,而将双亲结点中相应的关键字移至删除关键字所在结点中。显然,双亲中中关键字数目不变。例如,要在图8.13中删除关键字12,则需要将其右邻兄弟结点中30上移到其双亲结点中。而将双亲结点中的24移到被删结点中,如图8.14所示。

• 若需删除关键字所在结点及其相邻的左、右兄弟(或只有一个兄弟)结点中关键字数目均等于{m/2}向上取整-1,则按上述的移动操作就不能实现。此时,就需要将被删结点与其左兄弟或右兄弟结点进行“合并”。假设该结点有右邻兄弟(对左邻兄弟的方法类似),其兄弟结点地址由双亲结点中指针pi指定,在删除关键字之后,关键字所在结点中剩余的指针加上双亲结点中的关键字ki一起,合并到pi指定的兄弟结点中。例如,在图8.14所示的B树中删除关键字50,则删除其所在结点,并将结点中剩余信息(即空指针)和双亲结点中的63一起合并到右邻兄弟结点中,如图8.15所示。
如果因该操作从而引起对父结点中关键字的删除,又可能要合并结点,这一过程可能波及根,引起对根结点中关键字的删除,从而可能使B树的高度降低一层。例如,在图8.15所示的B树中删除关键字24之后,其双亲结点中剩余信息应该与其双亲结点的双亲结点中关键字45一起合并到右邻兄弟结点中,删除后的B树如图8.16所示。

删除算法实现,先找到被删除节点:
1.如果被删除节点在叶子节点,则直接删除节点中的值即可,因为是叶子节点所以指针位置不用改变(指针值均为空);
2.如果被删除节点不在叶子节点,则找到当前节点的直接前驱叶子节点,从直接前驱中替换一个值到当前节点,删除直接前驱中的值;
3.如果被删除的叶子节点(或直接前驱)因为删除值元素导致当前节点关键字个数小于{m/2}向上取整-1,则需要对B树的结构做出调整,使B树保持平衡。
• 如果当前节点的兄弟节点中关键字个数大于{m/2}向上取整-1,则从兄弟节点中借一个关键字过来。兄弟节点的关键字给父节点,父节点中关键字下降给当前节点。
• 如果当前节点的兄弟大于2且兄弟节点中关键字个数均等于{m/2}向上取整-1,则与临近的兄弟节点合并为一个节点作为父节点的新孩子节点。父亲节点中当前位置的关键字与兄弟节点的关键加上当前节点中关键字合并为一个新叶子节点。
• 如果不能合并兄弟节点且兄弟节点也没有值可以借,则向父类延申搜素,向祖先节点(父亲的父亲节点)借值。
• 如果祖先节点也没有值可以借了,则将当前节点的父节点与其所有的孩子合并为一个节点,合并后的节点作为父节点的父节点的新孩子。此时B树失去了平衡,父节点的父节点与其另外一个孩子合并为一个新的节点,B树会因为父节点的父节点下降而导致树的高度下降一级。
| int findCurrentPointer(struct BalanceNode* parent, struct BalanceNode* current); void chooseCombineNode(struct BalanceNode* removeNode, int pointer, int nodeSize); enum BalanceLocationFlag { left = 1, mid = 2, right = 3, rightLeft = 4, leftRight = 5 }; struct BalanceNode* combineBrotherNode(struct BalanceNode* left, int leftPoint, struct BalanceNode* right, int rightPoint); enum MoveBalanceFlag { success = 1, combineLeftParent = 2, combineNode = 3, combineRoot = 4, combineRightParent = 5 }; enum MoveBalanceFlag moveRightBalanceValue(struct BalanceNode* parent, struct BalanceNode* removeNode, struct SequenceQueue* queue, int minSize, struct BalanceNode** root); enum MoveBalanceFlag moveLeftBalanceValue(struct BalanceNode* parent, struct BalanceNode* removeNode, struct SequenceQueue* queue, int minSize, struct BalanceNode** root); void combineLeftParentNode(struct BalanceNode* parent, int isLeft, struct BalanceNode** root); void combineRightParentNode(struct BalanceNode* parent, int isLeft, struct BalanceNode** root); void moveBalanceValue(struct SequenceQueue* queue); void moveBalanceNode(struct BalanceNode* removeNode, struct BalanceTree* balanceTree) { struct BalanceNode* parent = removeNode->parent; if (parent == NULL) { balanceTree->root = NULL; return; } int minSize = balanceTree->nodeSize / 2 - 1; if (balanceTree->nodeSize % 2 > 0) minSize++; enum BalanceLocationFlag locationFlag = mid; int pointer = findCurrentPointer(parent, removeNode); if (pointer == parent->keyNum) { if (parent->parent == NULL) { locationFlag = right; } else { int parentPointer = findCurrentPointer(parent->parent, parent); if (parentPointer == 0) { locationFlag = leftRight; } else if (parentPointer == parent->parent->keyNum) { locationFlag = right; } else { chooseCombineNode(removeNode, pointer, balanceTree->nodeSize); return; } } } else if (pointer == 0) { if (parent->parent == NULL) { locationFlag = left; } else { int parentPointer = findCurrentPointer(parent->parent, parent); if (parentPointer == 0) { locationFlag = left; } else if (parentPointer == parent->parent->keyNum) { locationFlag = rightLeft; } else { chooseCombineNode(removeNode, pointer, balanceTree->nodeSize); return; } } } else { chooseCombineNode(removeNode, pointer, balanceTree->nodeSize); return; } if (parent->poNum > 2) { if (locationFlag == right || locationFlag == leftRight) { combineBrotherNode(parent->pointers[pointer - 1], pointer - 1, removeNode, pointer); } if (locationFlag == left || locationFlag == rightLeft) { combineBrotherNode(removeNode, pointer, parent->pointers[pointer + 1], pointer + 1); } } else { struct BalanceNode* rootNode = removeNode; struct BalanceNode* rootParent = parent; struct SequenceQueue* queue = initSequenceQueue(); removeNode->keyNum++; enum MoveBalanceFlag moveFlag = 0; if (locationFlag == right || locationFlag == rightLeft) { again: queue->push(&removeNode->keys[0], queue); if (locationFlag == rightLeft) { removeNode = parent; parent = parent->parent; } moveFlag = moveRightBalanceValue(parent, removeNode, queue, minSize, &balanceTree->root); if (moveFlag == combineLeftParent) { parent = rootParent; int isLeft = 1; if (locationFlag == rightLeft) { isLeft = 0; } combineLeftParentNode(parent, isLeft, &balanceTree->root); } if (moveFlag == combineNode) { removeNode = rootNode; parent = rootParent; goto again; } } if (locationFlag == left || locationFlag == leftRight) { leftAgain: queue->push(&removeNode->keys[0], queue); if (locationFlag == leftRight) { removeNode = parent; parent = parent->parent; } moveFlag = moveLeftBalanceValue(parent, removeNode, queue, minSize, &balanceTree->root); if (moveFlag == combineRightParent) { parent = rootParent; int isLeft = 0; if (locationFlag == leftRight) { isLeft = 1; } combineRightParentNode(parent, isLeft, &balanceTree->root); } if (moveFlag == combineNode) { removeNode = rootNode; parent = rootParent; goto leftAgain; } } // 执行移位 if (moveFlag == success) { moveBalanceValue(queue); } queue->destroy(queue); } } int findCurrentPointer(struct BalanceNode* parent, struct BalanceNode* current) { int poNum = parent->poNum; while (poNum >= 0) { poNum--; if (parent->pointers[poNum] == current) return poNum; } return poNum; } void chooseCombineNode(struct BalanceNode* removeNode, int pointer, int nodeSize) { struct BalanceNode* parent = removeNode->parent; if (parent->pointers[pointer + 1]->keyNum < nodeSize) { combineBrotherNode(removeNode, pointer, parent->pointers[pointer + 1], pointer + 1); } else if (parent->pointers[pointer - 1]->keyNum < nodeSize) { combineBrotherNode(parent->pointers[pointer - 1], pointer - 1, removeNode, pointer); } else { struct BalanceNode* left = parent->pointers[pointer - 1]; removeNode->keys[removeNode->keyNum++] = left->keys[left->keyNum - 1]; left->keys[--left->keyNum] = NULL; } } struct BalanceNode* combineBrotherNode(struct BalanceNode* left, int leftPoint, struct BalanceNode* right, int rightPoint) { struct BalanceNode* parent = NULL; if (left->keys[0] == NULL && right->parent->keyNum <= 1) { parent = right->parent; free(left); left = NULL; parent->poNum--; int keyNum = right->keyNum; while (keyNum > 0) { right->keys[keyNum] = right->keys[keyNum - 1]; keyNum--; } right->keys[0] = parent->keys[leftPoint]; right->keyNum++; keyNum = parent->keyNum - 1; int index = 0; while (index < keyNum) { parent->keys[index] = parent->keys[index + 1]; index++; } parent->keyNum--; int poNum = parent->poNum - 1; index = leftPoint; while (index < poNum) { parent->pointers[index] = parent->pointers[index + 1]; index++; } parent->poNum--; if (parent->keyNum <= 0 && parent->poNum <= 0) { free(right->parent); right->parent = NULL; parent = NULL; return right; } } else { parent = left->parent; left->keys[left->keyNum++] = parent->keys[leftPoint]; if (right->keyNum > 0 && right->keys[right->keyNum - 1] != NULL) { left->keys[left->keyNum++] = right->keys[right->keyNum - 1]; } free(right); right = NULL; for (int i = leftPoint; i < parent->keyNum; i++, rightPoint++) { parent->keys[i] = parent->keys[i + 1]; parent->pointers[rightPoint] = parent->pointers[rightPoint + 1]; } parent->keys[--parent->keyNum] = NULL; parent->pointers[--parent->poNum] = NULL; if (parent->keyNum <= 0) { free(left->parent); left->parent = NULL; parent = NULL; return left; } } return parent; } enum MoveBalanceFlag moveRightBalanceValue(struct BalanceNode* parent, struct BalanceNode* removeNode, struct SequenceQueue* queue, int minSize, struct BalanceNode** root) { enum MoveBalanceFlag moveFlag = success; int removePointer = findCurrentPointer(parent, removeNode); queue->push(&parent->keys[removePointer - 1], queue); struct BalanceNode* left = parent->pointers[removePointer - 1]; if (left->keyNum > minSize || left->pointers[left->keyNum] != NULL) { if (left->pointers[left->keyNum] == NULL) { queue->push(&left->keys[--left->keyNum], queue); } else { struct BalanceNode* right = left->pointers[left->keyNum]; struct BalanceNode* front = NULL; while (right != NULL) { front = right; right = right->pointers[right->keyNum]; } queue->push(&front->keys[front->keyNum - 1], queue); if (front->keyNum <= minSize) { return moveRightBalanceValue(front->parent, front, queue, minSize, root); } else { front->keyNum--; } } } else { int leftPointer = removePointer - 1; queue->push(&left->keys[left->keyNum - 1], queue); if (leftPointer == 0 && parent->parent != NULL) { if (stringCompare(parent->parent->keys[parent->parent->keyNum - 1], left->keys[left->keyNum - 1]) > 0) { if (parent->keyNum > minSize) { combineBrotherNode(left, leftPointer, removeNode, removePointer); queue->clear(queue); return moveFlag = combineNode; } else { return moveFlag = combineLeftParent; } } else { return moveRightBalanceValue(parent->parent, parent, queue, minSize, root); } } else if (leftPointer == 0 && parent->parent == NULL) { struct BalanceNode* result = combineBrotherNode(left, leftPointer, removeNode, removePointer); if (result != parent) { *root = result; parent = NULL; return moveFlag = combineRoot; } queue->clear(queue); return moveFlag = combineNode; } else { return moveRightBalanceValue(parent, left, queue, minSize, root); } } return moveFlag; } enum MoveBalanceFlag moveLeftBalanceValue(struct BalanceNode* parent, struct BalanceNode* removeNode, struct SequenceQueue* queue, int minSize, struct BalanceNode** root) { enum MoveBalanceFlag moveFlag = success; int removePointer = findCurrentPointer(parent, removeNode); queue->push(&parent->keys[removePointer], queue); struct BalanceNode* right = parent->pointers[removePointer + 1]; if (right->keyNum > minSize || right->pointers[0] != NULL) { if (right->pointers[0] == NULL) { char* temp = right->keys[0]; int keyNum = right->keyNum - 1; int index = 0; while (index < keyNum) { right->keys[index] = right->keys[index + 1]; index++; } right->keys[keyNum] = temp; queue->push(&right->keys[keyNum], queue); right->keyNum--; } else { struct BalanceNode* left = right->pointers[0]; struct BalanceNode* front = NULL; while (left != NULL) { front = left; left = left->pointers[0]; } int keyNum = 0, size = front->keyNum - 1; char* temp = front->keys[0]; while (keyNum < size) { front->keys[keyNum] = front->keys[keyNum + 1]; keyNum++; } front->keys[front->keyNum - 1] = temp; queue->push(&front->keys[front->keyNum - 1], queue); if (front->keyNum <= minSize) { return moveLeftBalanceValue(front->parent, front, queue, minSize, root); } else { front->keyNum--; } } } else { int rightPointer = removePointer + 1; queue->push(&right->keys[right->keyNum - 1], queue); if (rightPointer == parent->keyNum && parent->parent != NULL) { if (stringCompare(parent->parent->keys[0], right->keys[right->keyNum - 1]) < 0) { if (parent->keyNum > minSize) { combineBrotherNode(removeNode, removePointer, right, rightPointer); queue->clear(queue); return moveFlag = combineNode; } else { return moveFlag = combineRightParent; } } else { return moveLeftBalanceValue(parent->parent, parent, queue, minSize, root); } } else if (rightPointer == 1 && parent->parent == NULL) { struct BalanceNode* result = combineBrotherNode( removeNode, removePointer, right, rightPointer); if (result != parent) { *root = result; parent = NULL; return moveFlag = combineRoot; } queue->clear(queue); return moveFlag = combineNode; } else { return moveLeftBalanceValue(parent, right, queue, minSize, root); } } return moveFlag; } void combineLeftParentValue(struct BalanceNode* parent); void combineRightParentValue(struct BalanceNode* parent); void combineLeftParentNode(struct BalanceNode* parent, int isLeft, struct BalanceNode** root) { if (isLeft)combineLeftParentValue(parent); else combineRightParentValue(parent);
parent = parent->parent; struct BalanceNode* left = parent->pointers[parent->keyNum - 1]; left->parent = parent->parent; left->keys[left->keyNum++] = parent->keys[--parent->keyNum]; left->pointers[left->poNum++] = parent->pointers[parent->poNum - 1]; parent->pointers[parent->poNum - 1]->parent = left; if (*root == parent) { *root = left; } free(parent); parent = NULL; } void combineLeftParentValue(struct BalanceNode* parent) { struct BalanceNode* left = parent->pointers[parent->keyNum - 1]; char* leftValue = left->keys[left->keyNum - 1]; parent->keys[parent->keyNum] = parent->keys[parent->keyNum - 1]; parent->keys[parent->keyNum - 1] = leftValue; parent->keyNum++; free(parent->pointers[parent->poNum - 1]); free(parent->pointers[parent->poNum - 2]); parent->pointers[--parent->poNum] = NULL; parent->pointers[--parent->poNum] = NULL; } void combineRightParentNode(struct BalanceNode* parent, int isLeft, struct BalanceNode** root) { if (isLeft)combineLeftParentValue(parent); else combineRightParentValue(parent);
parent = parent->parent; struct BalanceNode* right = parent->pointers[parent->keyNum]; right->parent = parent->parent; int keyNum = right->keyNum; while (keyNum > 0) { right->keys[keyNum] = right->keys[keyNum - 1]; keyNum--; } int poNum = right->poNum; while (poNum > 0) { right->pointers[poNum] = right->pointers[poNum - 1]; poNum--; } right->keys[0] = parent->keys[--parent->keyNum]; right->keyNum++; right->pointers[0] = parent->pointers[0]; right->poNum++; parent->pointers[0]->parent = right; if (*root == parent) { *root = right; } free(parent); parent = NULL; } void combineRightParentValue(struct BalanceNode* parent) { struct BalanceNode* right = parent->pointers[parent->keyNum]; char* rightValue = right->keys[right->keyNum - 1]; parent->keys[parent->keyNum++] = rightValue; free(parent->pointers[parent->poNum - 1]); free(parent->pointers[parent->poNum - 2]); parent->pointers[--parent->poNum] = NULL; parent->pointers[--parent->poNum] = NULL; } void moveBalanceValue(struct SequenceQueue* queue) { char** front = queue->front(queue); queue->pop(queue); char** next = front; while (queue->isNotEmpty(queue)) { next = queue->front(queue); queue->pop(queue); *front = *next; front = next; } *next = NULL; } |
测试:
| #define _CRT_SECURE_NO_WARNINGS //规避C4996告警 #include <stdio.h> #include <stdlib.h> #include "balanceTree.h" int main() { struct BalanceTree* tree = initBalanceTree(4); //24, 45, 53, 90, 3, 50, 30, 61, 12, 70, 100 tree->insert("24", tree); tree->insert("45", tree); tree->insert("53", tree); tree->insert("90", tree); tree->insert("3", tree); tree->insert("50", tree); tree->insert("30", tree); tree->insert("61", tree); tree->insert("12", tree); tree->insert("70", tree); tree->insert("100", tree); tree->draw(tree); printf("==================================================================\n"); tree->remove("45",tree); tree->remove("24", tree); tree->remove("30", tree); tree->remove("50", tree); tree->remove("53", tree); tree->remove("61", tree); tree->remove("70", tree); tree->draw(tree); struct ResultBalanceInfo* info = tree->find("100", tree); return 0; } |
测试中可以看到B树删除了一个节点导致了B树的高度降低了一级,测试结果:

3.B树上的查找
根据B树的定义,在B树上进行查找的过程与二叉排序树上类似,都是经过一条从树根结点到待查关键字所在结点的查找路径,不过对路径中每个结点的比较过程比在二叉排序树的情况下要复杂一些,通常需要经过与多个关键字比较后才能处理完一个结点。因此,又称B树为多路查找树。在B树进行查找包括两种基本操作:在B树中查找结点、在结点中查找关键字。
在B树中查找一个关键字等于给定值data的具体过程可描述为:
若B树为非空,则首先取出树根结点,将给定值data依次与关键字向量中从低下标端(keys[keynum])开始的每个关键字进行比较,直到data<keysi (o≤i≤n=keynum),此时,若data=keysi-1 且i>0,则表明查找成功,返回具有该关键字的结点的存储位置及data在keys [1..keynum]中的位置;否则,其值为data的关键字只可能落在当前结点的pointeri所指向的子树上,接着只要在该子树上继续进行查找即可。这样,每取出一个结点比较后就下移一层,直到查找成功,或被查找的子树为空(即查找失败)为止。
| struct ResultBalanceInfo { struct BalanceNode* balanceNode; int index; int tag; }; int searchBalanceIndex(struct BalanceNode* balanceNode, char* data); struct ResultBalanceInfo* findBalanceNode(char* data, struct BalanceTree* balanceTree) { struct BalanceNode* balanceNode = balanceTree->root; struct BalanceNode* parent = NULL; int found = 0, index = 0; while (balanceNode != NULL && found == 0) { index = searchBalanceIndex(balanceNode, data); if (index > 0 && index <= balanceNode->keyNum && stringCompare(balanceNode->keys[index - 1], data) == 0) { index = index - 1; found = 1; } else { parent = balanceNode; balanceNode = balanceNode->pointers[index]; } } struct ResultBalanceInfo* result = malloc(sizeof(struct ResultBalanceInfo)); if (result == NULL) { #ifdef PRINT printf("搜索节点创建返回值对象,开辟内存失败!\n"); #endif return NULL; } result->index = index; if (found == 1) { result->balanceNode = balanceNode; result->tag = 1; } else { result->balanceNode = parent; result->tag = 0; } return result; } int searchBalanceIndex(struct BalanceNode* balanceNode, char* data) { int i = 0; for (i = 0; i < balanceNode->keyNum && (stringCompare(balanceNode->keys[i], data) < 0 || stringCompare(balanceNode->keys[i], data) == 0); i++); return i; } |
上述算法的查找只是在内存中进行的,而B树通常是作为外存文件的索引结构保存在外存上。对外存上的B树进行查找、插入和删除时,会涉及文件操作和其他相关内容。
例如,在如图8.17所示的B树上查找关键字值等于18的结点及其位置时,首先取出根结点a,因为该结点的keynum=1,所以用18与keys0比较, 18小于keys0的值48,接着取出a结点的pointer0指向的结点b, 用18与b结点中的keys1值进行比较18<32, 再取出b结点的pointer1所指向的结点e查找成功,返回e结点的存储地址以及keys0的位置。

4.B树算法完整代码
https://blog.csdn.net/qq_43460743/article/details/130693608
8.3.3.B+树
B+树是一种常用于文件组织的B树的变形树。一棵m阶的B+树和m阶的B树的差异在于:
(1)有k个孩子的结点必含有k个关键字。
(2)所有的叶结点中包含了关键字的信息及指向相应结点的指针,且叶子结点本身依照关键字的大小自小到大顺序链接。
(3)所有非终端结点可看成是索引部分,结点中仅含有其子树(根结点)中的最大(或最小)关键字。
例如,图8.18所示是一棵3阶的B+树。通常在B+树上有两个头指针root和sqt,前者指向根结点,后者指向关键字最小的叶子结点。因此,可以对B+树进行两种查找运算:一种是从最小关键字起进行顺序查找,另一种是从根结点开始进行随机查找。

在B+树上进行随机查找、插入和删除的过程,基本上与B树类似。只是在查找时,若非叶结点上的关键字等于给定值,并不终止,而是继续向下直到叶子结点。因此,在B+树中,不管查找成功与否,每次查找都是走了一条从根到叶子结点的路径。B+树上查找的分析类似于B树; B+树的插入仅在叶子结点进行,当结点中的关键字个数大于m时要分裂成两个结点,它们所含关键字的个数分别为

并且它们的双亲结点中应同时包含这两个结点中的最大关键字。B+树的删除也仅在叶子结点进行,当叶子结点中的最大关键字被删除时,其在非终端结点中的值可以作为一个“分界关键字”存在。若因删除而使结点中关键字的个数少于时,则可能要和该节点的兄弟结点合并,其合并过程也与B树也类似。
8.4.散列表查找
8.4.1.散列表的概念
散列表查找不同于前面的几种查找方法,它是通过对记录的关键字值进行某种运算直接求出记录的地址,是一种由关键字到地址的直接转换方法,不需要反复比较。
散列(Hash)同顺序、链式和索引存储结构一样,是存储线性表的又一种方法。散列存储的基本思想是:以线性表中的每个元素的关键字key为自变量,通过一种函数H(key)计算出函数值,把这个函数值解释为一块连续存储空间的单元地址(即下标),将该元素存储到这个单元中。散列存储中使用的函数H(key)称为散列函数或哈希函数,它实现关键字到存储地址的映射(或称转换)。H (key)的值称为散列地址或哈希地址,使用的数组空间是线性表进行散列存储的地址空间,所以被称之为散列表或哈希表。当在散列表上进行查找时,首先根据给定的关键字key,用与散列存储时使用的同一散列函数H(key)计算出散列地址,然后按此地址从散列表中取对应的元素。
例如,有个线性表A=(31, 62, 74, 36, 49, 77),其中每个整数可以是元素本身,也可以仅是元素的关键字。为了散列存储该线性表,假设选取的散列函数为:
H(kye)=key%m
即用元素的关键字key整除m,取其余数作为存储该元素的散列地址, m一般取小于或等于散列表长的最大素数,在这里取m=11,表长也为11,因此可得到每个元素的散列地址:
H(31)=31%11=9; H(62)=62%11=7; H(74)=74%11=8;
H(36)=36%11=3; H(49)=49%11=5; H(77)=77%11=0;
如果根据散列地址把上述元素存储到散列表HT[m]中,则存储结构为:

从散列表中查找元素与插入元素一样简单,如从HT中查找关键字为36的元素时,只要利用上述散列函数H (key)计算出key=36时的散列地址3,则从下标为3的单元中取出该元素即可。
在上面的散列表上插入时,根据元素的关键字计算出的散列地址所对应的存储单元都是空闲的,没有出现该单元已被其他元素占用的情况。在实际应用中这种理想的情况是很少见的,例如要在上面的散列表中插入一个关键字为19的元素时,计算出其散列地址为8,而8号单元已被关键字为74的元素所占用,通常把这种现象称为冲突。具有相同散列地址的关键字称为同义词。因此,在设计散列函数时,要考虑避免或尽量减少冲突。但少量的冲突往往是不可避免的,这样就存在如何解决冲突的问题。冲突的频度除了与散列函数H相关外,还与散列表的填满程度相关。设m为散列表表长, n为表中填入的结点数,将α=n/m定义为散列表的装填因子,那么, α越大,表装得越满,冲突的机会就越大。因此,如何尽量避免冲突和冲突发生后如何解决冲突,就成了散列存储的两个关键问题。
8.4.2.散列函数的构造方法
构造散列函数的目标是使散列地址尽可能均匀地分布在散列空间上,同时使计算尽可能简单。构造散列函数的方法很多,常用的构造散列函数的方法有如下几种。
1.直接地址法
直接地址法是以关键字key本身或关键字加上某个常量C作为散列地址的方法。对应的散列函数H (key)为
H (key) =key+C
在使用时,为了使散列地址与存储空间吻合,可以调整C。这种方法计算简单,并且没有冲突。它适合于关键字的分布基本连续的情况,若关键字分布不连续,空号较多,将会造成较大的空间浪费。
2.数字分析法
数字分析法是假设有一组关键字,每个关键字由n位数字组成,如k1,k2,···kn。数字分析法是从中提取数字分布比较均匀的若干位作为散列地址。
例如,有一组有6位数字组成的关键字,如下表左边一列所示。
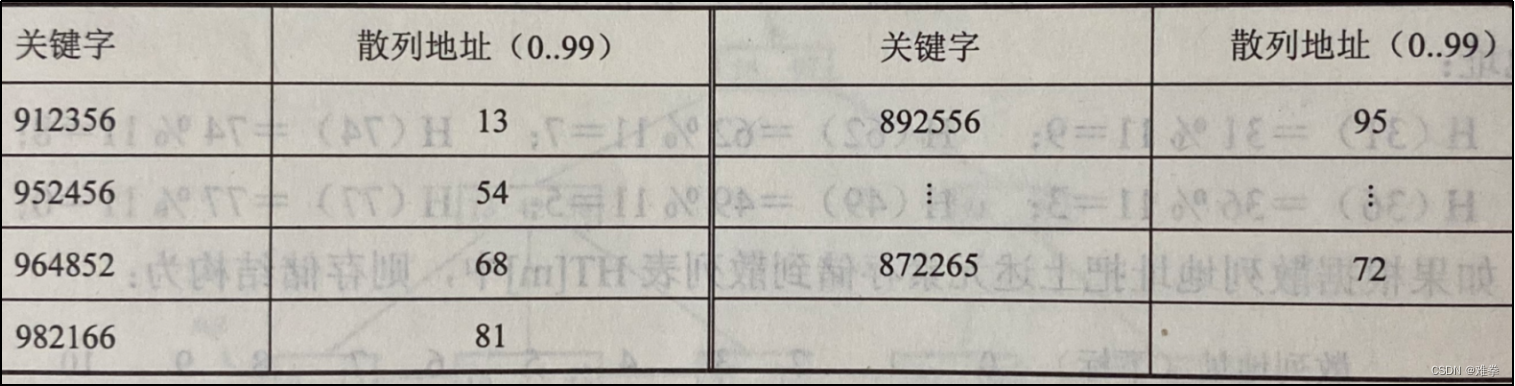
分析这一组关键字会发现,第1、3、5和6位数字分布不均匀,第1位数字全是9或8,第3位基本上都是2,第5、6两位上也都基本上是5和6,故这4位不可取。而第2、4两位数字分布比较均匀,因此可取关键字中第2、4两位的组合作为散列地址,如表8.1的右边一列所示。
3.除余数法
除余数法是选择一个适当的p (p≤散列表长m)去除关键字k,所得余数作为散列地址的方法。对应的散列函数H(k)为
H (k) =k%p
其中, p最好选取小于或等于表长m的最大素数。如表长为20,那么p选19;若表长为25,则p可选23,······。表长m与模p的关系可按下表对应:
m=8, 16, 32, 64, 128, 256, 512, 4024, ···
p =7, 13, 31, 61, 127, 251, 503, 1019, ···
这是一种最简单也是最常用的一种散列函数构造方法,在第8.4.1节已经使用过了。
4.平方取中法
平方取中法是取关键字平方的中间几位作为散列地址的方法,因为一个乘积的中间几位和乘数的每一位都相关,故由此产生的散列地址较为均匀,具体取多少位视实际情况而定。例如有一组关键字集合(0100, 0110, 0111, 1001, 1010, 1110),平方之后得到新的数据合(0010000, 0012100, 0012321, 1002001, 1020100, 123210),那么,若表长为1000,则可取其中第3、4和5位作为对应的散列地址(100, 121, 123, 020,201, 321)。
5.折叠法
折叠法是首先把关键字分割成位数相同的几段(最后一段的位数可少一些),段的位数取决于散列地址的位数, 由实际情况而定,然后将它们的叠加和(舍去最高进位)作为散列地址的方法。
折叠法又分移位叠加和边界叠加。移位叠加是将各段的最低位对齐,然后相加;边界叠加则是将两个相邻的段沿边界来回折叠,然后对齐相加。
例如,关键字k=98 123 658,散列地址为3位,则将关键字从左到右每三位一段进行划分,得到的三个段为981, 236和58,叠加后值为1275,取低3位275作为关键字98 123 658的元素的散列地址;如若用边界叠加,即为981、632和58叠加后其值为1671,取低3位得671作为散列地址。
8.4.3.处理冲突的方法
散列法构造表可通过散列函数的选取来减少冲突,但冲突一般不可避免,为此,需要有解决冲突的方法。常用的解决冲突的方法有两大类,即开放定址法和拉链法。
1.开放定址法
开放定址法又分为线性探插法、二次探查法和双重散列法。开放定址法解决冲突的基本思想是:使用某种方法在散列表中形成一个探查序列,沿着此序列逐个单元进行查找,直到找到一个空闲的单元时将新结点存入其中。假设散列表空间为T[0..m-1],散列函数为H(key),开放定址法的一般形式为:
hi=(H(key)+di)%m 0≤i≤m-1
其中di为增量序列, m为散列表长。h0=H (key)为初始探查地址(假设d0=0),后续的探查地址依次是h1, h2, ···, hm-1。
(1)线性探查法,di增量序列为自然数。
线性探查法的基本思想是:将散列表T[0..m-1]看成一个循环同量,若初始探查的地址为d(即H(key)=d),则后续探查地址的序列为: d+1, d+2, ···,m-1, 0, 1, ···, d-1。也就是说,探查时从地址d开始,首先探查T[d],然后依次探查T[d+1],···, T[m-1] ,此后又循环到T[0], T[1],···, T[d-1]。分两种情况分析:一种运算是插入,若当前探查单元为空,则将关键字key写入空单元,若不空则继续后序地址探查,直到遇到空单元插入关键字,若探查到T[d-1]时仍未发现空单元,则插入失败(表满);另一种运算是查找,若当前探查单元中的关键字值等于key,则表示查找成功,若不等,则继续后续地址探查,若遇到单元中的关键字值等于key时,查找成功,若再探查T[d-1]单元时,仍未发现关键字值等于key,则查找失败。
(2)二次探查法,di增量序列为i2。
二次探查法的探查序列是:

即探查序列为: d=H (key), d+12, d-12, d+22, d-22, ···等。也就是说,探查从地址d开始,先探查T[d],然后再依次探查T[d+12],T[d-12], T[d+22], T[d-22], ···。
(3)双重散列法,di增量序列为i*H (key)。
双重散列法是几种方法中最好的方法,它的探查序列为:
hi= (H (key) +i*H (key)) %m (0≤i≤m-1)
即探查序列为: d=H (key), (d+1*H1 (key)) %m, (d+2*H1 (key)) %m,···等。
【例8.6】设散列函数为h (key) =key % 11;散列地址表空间为0~10,对关键字序列{127, 13, 55, 32, 18, 49, 24, 38, 43},利用线性探测法解决冲突,构造散列表。
解:首先根据散列函数计算散列地址
h(27)=5; h(13)=2;
h(55)=0; h(32)=10;
h(18)=7; h(49)=5;
h(24)=2; h(38)=5;
h(43)=10; (散列表各元素查找比较次数标注在结点的上方或下方)
根据散列函数计算得到的散列地址可知,关键字27、13、55、32、18插入的地址均为开放地址,将它们直接插入到T[5], T[2], T[0], T[10], T[7]中。当插入关键字49时,散列地址5已被同义词27占用,因此探查h1=(5+1) %11=6,此地址为开放地址,因此可将49插入到T[6]中。当插入关键字24时,其散列地址2已被同义词13占用,故探测地址h1=(2+1) %11=3,此地址为开放地址,因此可将24插入到T[3]中。当关键字38插入时,散列地址5已被同义词27占用,探查h1=(5+1) % 11=6,也被同义词49占用,再探查h2=(5+2) %11=7,地址7已被非同义词占用,因此需要再探查h2= (5+3) % 11=8,此地址为开放地址,因此可将38插入到T[8]中。当插入关键字43时,计算得到散列地址10已被关键字32占用,需要探查h1=(10+1) % 11=0,此地址已被占用,探查h2=(10+1) % 11=1为开放地址,因此可将43插入到T[1]中。由此构造的散列表如图8.19所示。

(4)伪随机探测法,di增量序列为随机数。
伪随机探测法探查序列为:
hi= (H (key) +di) %m (0≤i≤m-1)
其中:m为散列表长度
di为伪随机数
2.拉链法(链地址法)
当存储结构是链表时,多采用拉链法。用拉链法处理冲突的办法是:把具有相同散列地址的关键字(同义词)值放在同一个单链表中,称为同义词链表。有m个散列地址就有m个链表,同时用指针数组T[0..m-1]存放各个链表的头指针,凡是散列地址为i的记录都以结点方式插入到以T[i]为指针的单链表中。T中各分量的初值应为空指针。
例如,按例8.6所给的关键字序列,用拉链法构造散列表如图8.20所示。
 用拉链法处理冲突,虽然比开放定址法多占用一些存储空间用作链接指针,但它可以减少在插入和查找过程中关键字的平均比较次数(平均查找长度)。这是因为,在拉链法中待比较的结点都是同义词结点,而在开放定址法中,待比较的结点不仅包含有同义词结点,而且包含有非同义词结点,往往非同义词结点比同义词结点还要多。
用拉链法处理冲突,虽然比开放定址法多占用一些存储空间用作链接指针,但它可以减少在插入和查找过程中关键字的平均比较次数(平均查找长度)。这是因为,在拉链法中待比较的结点都是同义词结点,而在开放定址法中,待比较的结点不仅包含有同义词结点,而且包含有非同义词结点,往往非同义词结点比同义词结点还要多。
例8.6中用线性探测法构造散列表的过程,对前5个关键字的查找,每一个仅需要比较一次,对关键字49和24的查找需要比较2次,对关键字38的查找则需要比较4次,而对43的查找则需要比较3次。因此,对用线性探测法构造的散列表的平均查找长度为:
ASL= (1×5+2×2+3×1+4×1) /9≈1.78
而用拉链法构造的散列表查找成功的平均查找长度为:
ASL=(1×5+2×3+3×1) /9≈1.55
显然,开放定址法处理冲突的平均查找长度要高于拉链法处理冲突的平均查找长度。但它们都比前面介绍的其他查找方法的平均查找长度要小。
8.4.4.散列表的查找
散列表的查找过程与建表的过程基本一致。给定一个关键字值K,根据建表时设定的散列函数求得散列地址,若表中该地址对应的空间是空的,则说明查找不成功;否则将该地址单元的关键字值与K比较。若相等则表明查找成功,否则再根据建表时解决冲突的方法寻找下一个地址,反复进行,直到查找成功或找到某个存储单元为空(查找不成功)为止。

在线性表的散列存储中,处理冲突的方法不同,其散列表的类型定义也不同。
【例】已知一组关键字(19,14,23,1,68,20,84,27,5,11,10,79)散列函数为: H(key)=key%13,散列表长为m=16,设每个记录的查找概率相等
用线性探测在散列处理冲突,即Hi=(H(key)+di)%m
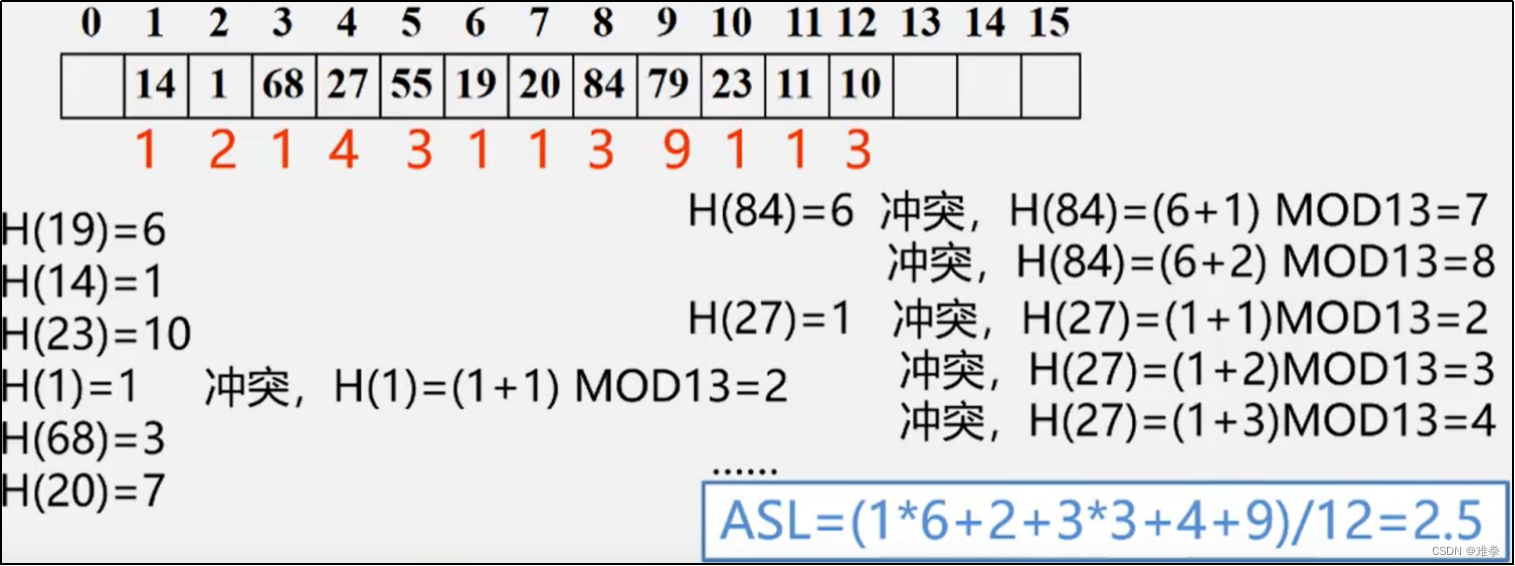
【例】已知一组关键字(19,14,23,1,68,20,84,27,5,11,10,79)散列函数为: H(key)=key%13,散列表长为m=16,设每个记录的查找概率相等
用链地址法在散列表处理冲突,
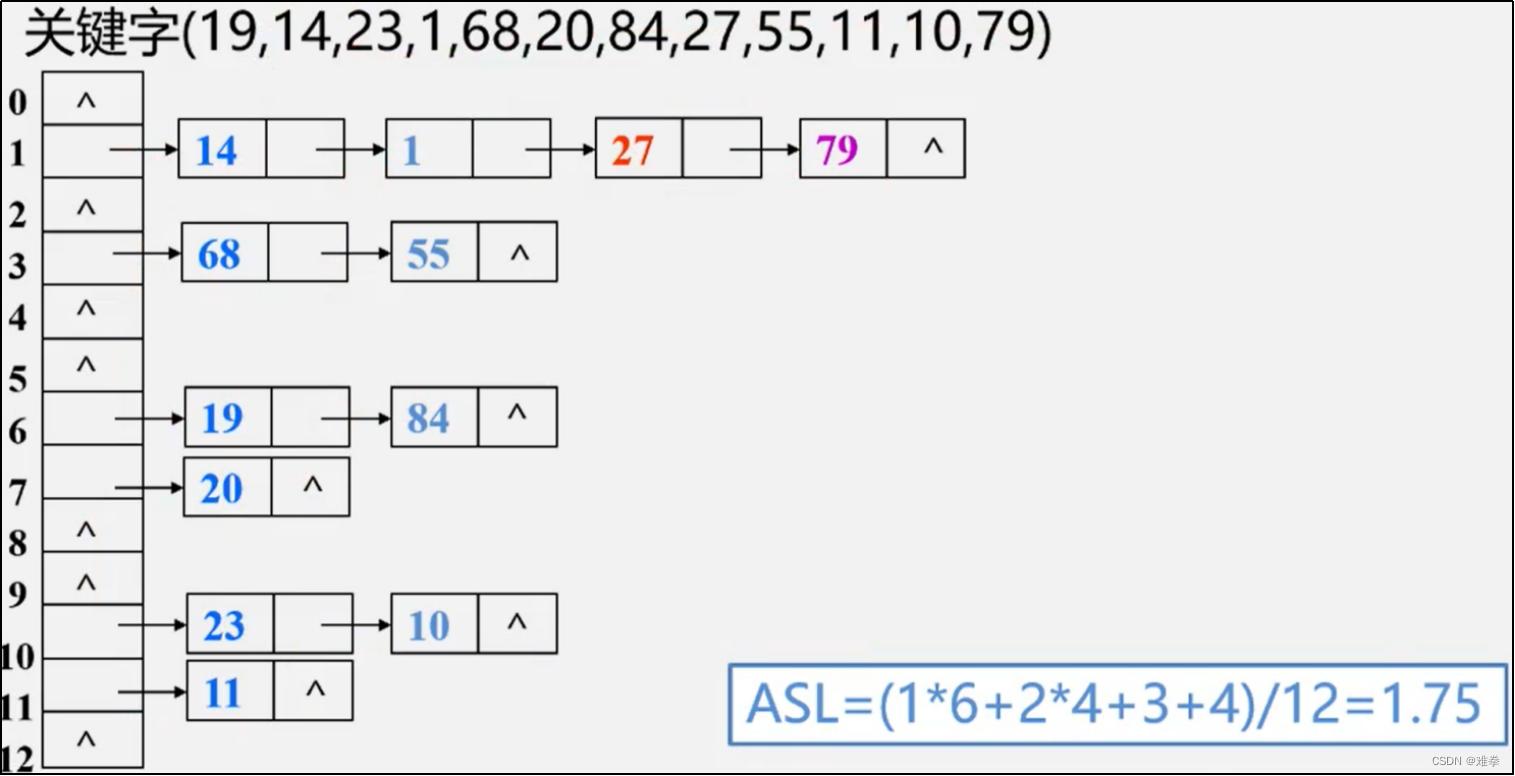
从上述查找过程可知,虽然散列表是在关键字和存储位置之间直接建立了对应天系,但是由于产生了冲突,散列表的查找过程仍然有一个与关键字比较的过程,不过散列表的平均查找长度要比顺序查找小得多,比二分查找也小。
【例8.7】 设散列函数f(k) =k%13,散列表地址空间为0~12,对给定的关键字序列(19, 14, 01, 68, 20, 84, 27, 26, 50, 36)分别以拉链法和线性探查法解决冲突构造散列表,画出所构造的散列表,指出在这两个散列表中查找每一个关键字时进行比较的次数,并分析在等概率情况下查找成功和不成功时的平均查找长度以及当结点数为n=10时的顺序查找和二分查找成功与不成功的情况。
分析:
(1)用线性探测法解决冲突,其散列表如图8.21所示。

因此,在该表上的平均查找长度为:
ASL=(1+1+2+1+4+1+1+3+1+1)/10=1.6
(2)用拉链法解决冲突,构造的散列表如图8.22所示。

在该散列表上的平均查找长度为:
ASL= (1X7+2×2+3×1) /10=1.4
而当n=10时,顺序查找和二分查找的平均长度分别为:
ASLseq= ( 10+1) /2=5.5
ASLbin=(1×1+2×2+3×4+4×3) /10≈3
对于查找不成功的情况,顺序查找和二分查找所需要进行的关键字仅取决于表长,而散列表查找所需要进行的比较次数和待查结点有关。因此,在等概率情况下,也可以将散列表在查找不成功时对关键字需要执行的平均比较次数,定义为查找不成功时的平均查找长度。
在图8.21所示的线性探查法中,假设所查的关键字K不在散列表中,若h (K) =0,则必须依次在表T[0..5]中的关键字K或空值进行比较之后才遇到T[5]为空,即比较次数为6;若h (K) =1,则需要比较5次才能确定查找不成功。类似地,对h(K) =2,3,4,5进行分析,其比较次数分别为: 4, 3, 2, 1,若h (K) =6,7,8,9时,则类似的需要比较次数分别为: 4, 3, 2, 1;而h (K) =10, 11, 12时,需要比较次数分别为3, 2, 1次才能确定查找不成功,所以查找不成功时的平均查找长度为:
ASL=(6+5+4+3+2+1+4+3+2+1+3+2+1) /13≈2.85
请注意,在计算查找成功的平均查找长度时,除数是结点的个数,而在计算查找不成功的平均查找长度时,除数却是表长。因此,同样的一组关键字对应的散列表,因表长不同,其查找成功和查找不成功时的平均查找长度都是不同的。
另外,在拉链法建立的散列表中,若待查关键字K的散列地址为d=h (K),且第d个链表上具有i个结点,则当K不在链表上时,就需要做K次关键字比较(不包括空指针比较),因此查找不成功时的平均查找长度为:
ASL=(1+3+0+1+0+0+2+1+0+0+1+1+0) /13~0.7
从上面的讨论中可以看出,同一个散列函数用不同的解决冲突方法所构造的的散列表,其查找成功时的平均查找长度或查找不成功时的平均查找长度都是不同的。
散列表的查找效率分析:

ASL与装填因子ɑ有关!既不是严格O(1),也不是O(n),下面给出在等概率情况下,采用五种不同方法处理冲突时得出的散列表的平均查找长度。
线性探查法: 查找成功为:≈(1+1/ (1-ɑ)) /2, 不成功时为:(1+1/ (1-ɑ) 2) /2
二次探查法: ≈-In (1-ɑ)/ɑ 1/ (1-ɑ)
双重散列法: ≈-In (1-ɑ) /ɑ 1/ (1-ɑ)
随机探测法 ≈-In (1-ɑ) /ɑ 1/ (1-ɑ)
拉链法: ≈1+ɑ/2 ɑ+e-ɑ
由此可见,散列表的平均查找长度不是结点个数n的函数,而是装填因子ɑ的函数,即散列表的平均查找长度与结点个数n无关。因此在设计散列表时可通过选择装填因子ɑ来控制散列表的平均查找长度。开放定址法要求散列表的装填因子ɑ≤1,实用中一般取0.65~0.9之间的某个值为宜。在拉链法中,其装填因子ɑ可以大于1,但一般均取ɑ≤1,只要ɑ选择合适,散列表表上的平均查找长度就是一个常数。例如,当ɑ=0.9时,对于成功的查找,线性探查法的平均查找长度是5.5;二次探查法、双重散列法的平均查找长度是2.56;拉链法的平均查找长度是1.45。但一般在实际计算平均查找长度时,不能简单地用以上公式来计算,因为这样得到的值是不精确的。
| 结论: · 散列表技术具有很好的平均性能,优于一些传统的查找技术 · 链地址法优于开放定地址法 · 除留余数法作散列函数优于其它类型函数 |
8.4.5.散列表的实现
散列表的实现比较简单,不同的散列函数与不同的冲突处理方法会组合出多种不同的散列表。这里对散列函数选择除余数法,对处理冲突选择拉链法做实现,其他算法类似。
hashTable.h
| #pragma once #ifndef HASH_H #define HASH_H #include "string.h" struct HashNode { char* data; struct HashNode* next; }; // rɪˈmeɪndə(r) skweə(r) fəʊld // direct:直接地址, number:数字分析, remainder:除余数, square:平方取中, fold:折叠 enum HashFunc { direct = 1, number = 2, remainder = 3, square = 4, fold = 5 }; // linear:线性探查, twice:二次探查, doubleHash:双重散列, random:伪随机, list:拉链 enum ClashFunc { linear = 1, twice = 2, doubleHash = 3, random = 4, list = 5 }; struct HashTable { enum HashFunc hashFunc; enum ClashFunc clashFunc; int capacity; struct HashNode** table; int (*insert)(char* data, struct HashTable* hashTable); int (*find)(char* data, struct HashTable* hashTable); void (*draw)(struct HashTable* hashTable); }; struct HashTable* initHashTable(enum HashFunc hashFunc, enum ClashFunc clashFunc,int capacity); #endif |
hashTable.c
| #define _CRT_SECURE_NO_WARNINGS //规避C4996告警 #include <stdio.h> #include <stdlib.h> #include "hashTable.h" #define PRINT 1 /* * int hashFuncRemainder(char* data, char** table) * int clashFuncList(char* data, char** table) */ int insertHashTable(char* data, struct HashTable* hashTable); int findHashTable(char* data, struct HashTable* hashTable); void drawHashTable(struct HashTable* hashTable); struct HashTable* initHashTable(enum HashFunc hashFunc, enum ClashFunc clashFunc, int capacity) { struct HashTable* hashTable = malloc(sizeof(struct HashTable)); struct HashNode** table = calloc(capacity, sizeof(struct HashNode*)); if (hashTable == NULL || table == NULL) { #ifdef PRINT printf("构建散列表,开辟空间失败!\n"); #endif return NULL; } hashTable->table = table; hashTable->hashFunc = hashFunc; hashTable->clashFunc = clashFunc; hashTable->capacity = capacity; hashTable->insert = insertHashTable; hashTable->find = findHashTable; hashTable->draw = drawHashTable; return hashTable; } int chosseHashFunc(char* data, struct HashTable* hashTable); void chosseClashFunc(struct HashNode* hashNode, int index, struct HashTable* hashTable); int insertHashTable(char* data, struct HashTable* hashTable) { if (hashTable == NULL || hashTable->table == NULL) { #ifdef PRINT printf("散列表为空或不存在!\n"); #endif return -1; } struct HashNode* hashNode = calloc(1, sizeof(struct HashNode)); if (hashNode == NULL) { #ifdef PRINT printf("散列表构建节点,开辟空间失败!\n"); #endif return 0; } hashNode->data = data; hashNode->next = NULL; int index = chosseHashFunc(data, hashTable); struct HashNode** table = hashTable->table; if (table[index] == NULL) { table[index] = hashNode; } else { chosseClashFunc(hashNode, index, hashTable); } } int hashFuncRemainder(char* data, struct HashTable* hashTable); int chosseHashFunc(char* data, struct HashTable* hashTable) { int index = -1; switch (hashTable->hashFunc) { case remainder: index = hashFuncRemainder(data, hashTable); break; defauklt: printf("未匹配到散列函数!\n"); } return index; } int hashFuncRemainder(char* data, struct HashTable* hashTable) { int num = atoi(data); return num % hashTable->capacity; } void clashFuncList(struct HashNode* hashNode, int index, struct HashTable* hashTable); void chosseClashFunc(struct HashNode* hashNode, int index, struct HashTable* hashTable) { switch (hashTable->clashFunc) { case list: clashFuncList(hashNode, index, hashTable); break; defauklt: printf("未匹配到冲突处理函数!\n"); } } void clashFuncList(struct HashNode* hashNode, int index, struct HashTable* hashTable) { struct HashNode** table = hashTable->table; struct HashNode* node = table[index]; struct HashNode* front = node; while (node != NULL) { front = node; node = node->next; } front->next = hashNode; } int findHashTable(char* data, struct HashTable* hashTable) { if (hashTable == NULL || hashTable->table == NULL) { #ifdef PRINT printf("散列表为空或不存在!\n"); #endif return -1; } return chosseHashFunc(data, hashTable); } void drawHashTable(struct HashTable* hashTable) { if (hashTable == NULL || hashTable->table == NULL) { #ifdef PRINT printf("散列表为空或不存在!\n"); #endif return; } struct HashNode** table = hashTable->table; int capacity = hashTable->capacity; for (int i = 0; i < capacity; i++) { if (table[i] != NULL) { struct HashNode* node = table[i]; printf("Head:"); while (node != NULL) { printf("%s-->", node->data); node = node->next; } printf("NULL"); } else { printf("NULL:"); } printf("\n"); } } |
测试:
| #define _CRT_SECURE_NO_WARNINGS //规避C4996告警 #include <stdio.h> #include <stdlib.h> #include "hashTable.h" int main() { enum HashFunc hashFunc = remainder; enum ClashFunc clashFunc = list; struct HashTable* table = initHashTable(hashFunc, clashFunc, 4); table->insert("1", table); table->insert("2", table); table->insert("3", table); table->insert("4", table); table->insert("5", table); table->insert("6", table); table->insert("7", table); table->insert("8", table); table->insert("9", table); table->draw(table); printf("数值7在%d位置。", table->find("7", table)); return 0; } |
测试结果:
| Head:4-->8-->NULL Head:1-->5-->9-->NULL Head:2-->6-->NULL Head:3-->7-->NULL 数值7在3位置。 |
小结
查找是数据处理中经常使用的一种重要运算。由于查找运算频率很高,在任何一个计算机应用软件和系统软件中都会涉及,所以当问题所涉及的数据相当大时,查找方法的效率就显得格外重要。对各种查找方法的效率进行分析比较是本章的主要内容。
本章讨论了顺序表的查找、树表的查找以及散列查找。重点讨论了二分查找、二叉排序树及散列表查找,这也是本章需要学习掌握的重点。不仅要理解这些查找算法的基本思想,还要能够写出各种算法记录的查找和插入过程,以及分析比较计算这些算法在等概率情况下查找成功时的平均查找长度等。
散列方法的基本思想就是用某个函数将关键字值转换成整数(称为地址),这一思想是构造一类非常有效的数据结构的基础。一个好的散列函数应将元素比较均匀地插入到散列表中,因此选择散列函数是实现散列法的关键。
本章的难点是B树和B+树的概念,特别是在B树上的插入和删除操作,需要认真对待。