在mysql数据中
一般经常看到有人写统计是这样
select count(*) from table 、 select count(1) from table ,select count(字段) from table
那这三者到底有什么区别呢,,我们看下面一个千万级别数据表查询
select count(1) from table
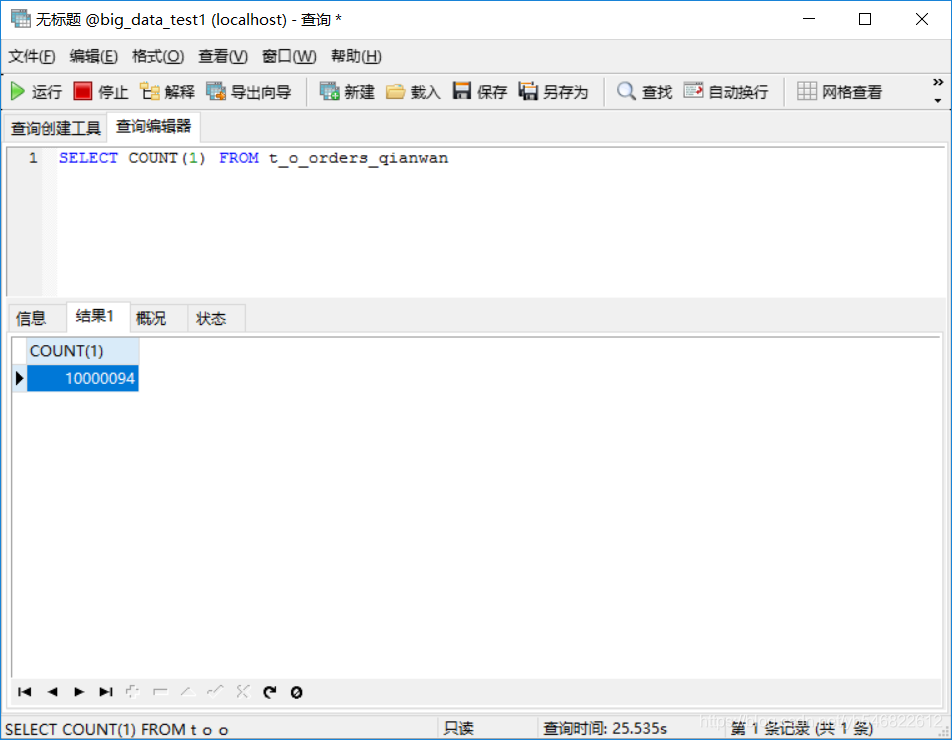
select count(*) from table

select coun(主键) from table

从上面可以看出,对于千万级别表而言,它们的效率相差不大,count(*) 稍差些,其它两个都差不多
下面我们说 count(*)、count(1)、count(列名)三者的区别:
- count(*)包括了所有的列,相当于行数,在统计结果的时候,不会忽略列值为NULL
- count(1)包括了忽略所有列,用1代表代码行,在统计结果的时候,不会忽略列值为NULL
- count(列名)只包括列名那一列,在统计结果的时候,会忽略列值为空(这里的空不是只空字符串或者0,而是表示null)的计数,即某个字段值为NULL时,不统计。
对于 InnoDB 来说,当列名为主键,count(列名) 会比 count(1) 快;当列名不为主键,count(1) 会比 count(列名) 快;如果表多个列并且没有主键,则 count(1)的执行效率优于 count(*);如果有主键,则 select count(主键)的执行效率是最优的;如果表只有一个字段,则 select count(*)最优。
