目标:公司内部通过DeepSeek+RAG本地化部署搭建知识库。
一、硬件配置
CPU:Intel(R) Xeon(R) Gold 6138 CPU @ 2.00GHz 2.00 GHz (2 个处理器)48核
GPU:英伟达4070Ti Super 16GB,两块,共32GB显存
RAM:128GB
硬盘:4TB M2;RAID5磁盘阵列,30TB;
二、安装步骤
1.基础环境安装
因服务器上有其它使用python环境的应用,故使用conda来管理python环境。
(1)安装conda管理器
下载地址:https://docs.conda.io/en/latest/miniconda.html
安装好后打开它,最好使用管理员模式打开。
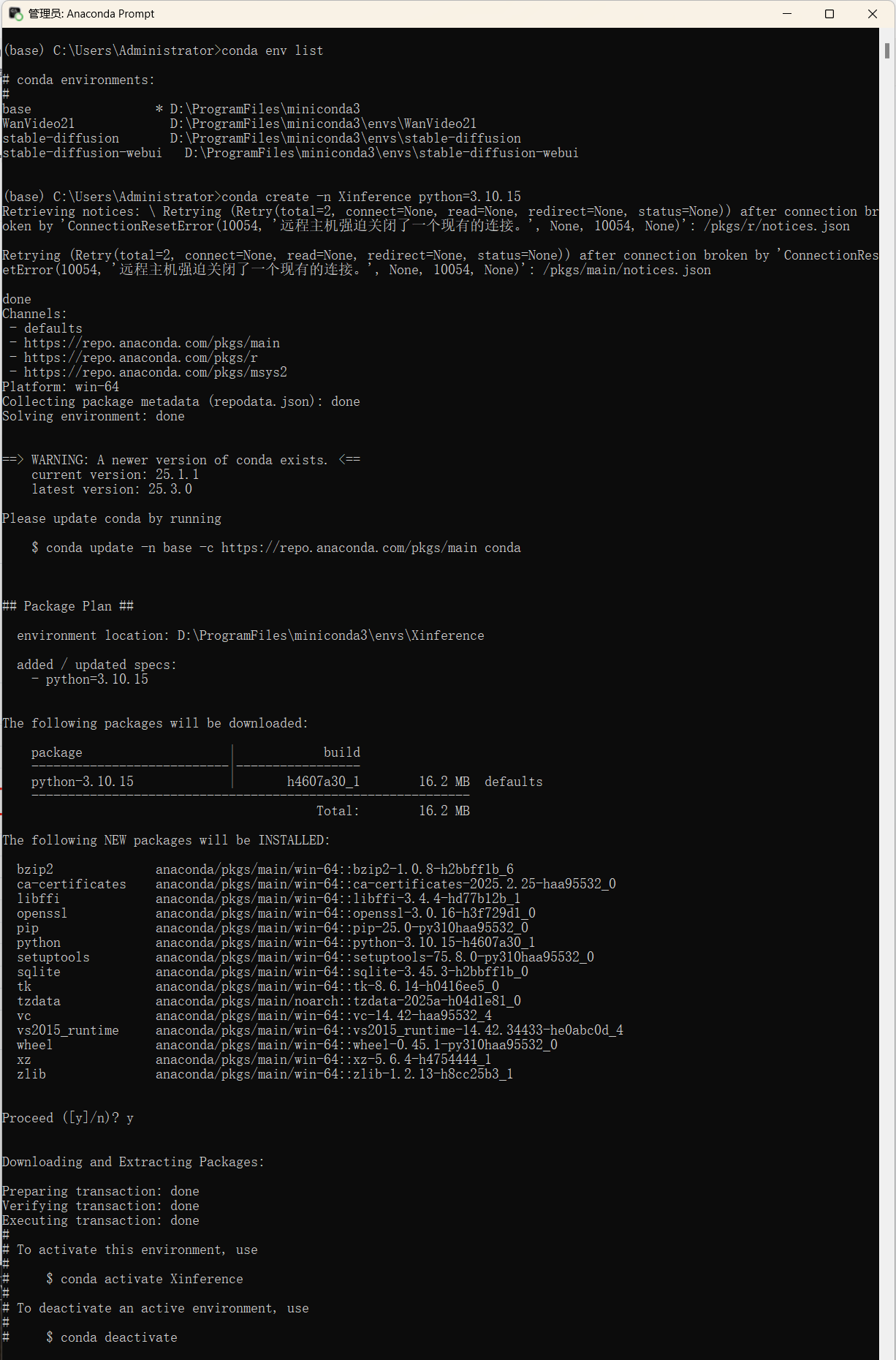
(2)创建虚拟环境Xinference并激活它
依次敲入指令,创建并激活项目所需的虚拟环境。
conda create -n Xinference python=3.10.15
conda activate Xinference

(3)安装chatglm-cpp
https://github.com/li-plus/chatglm.cpp/releases
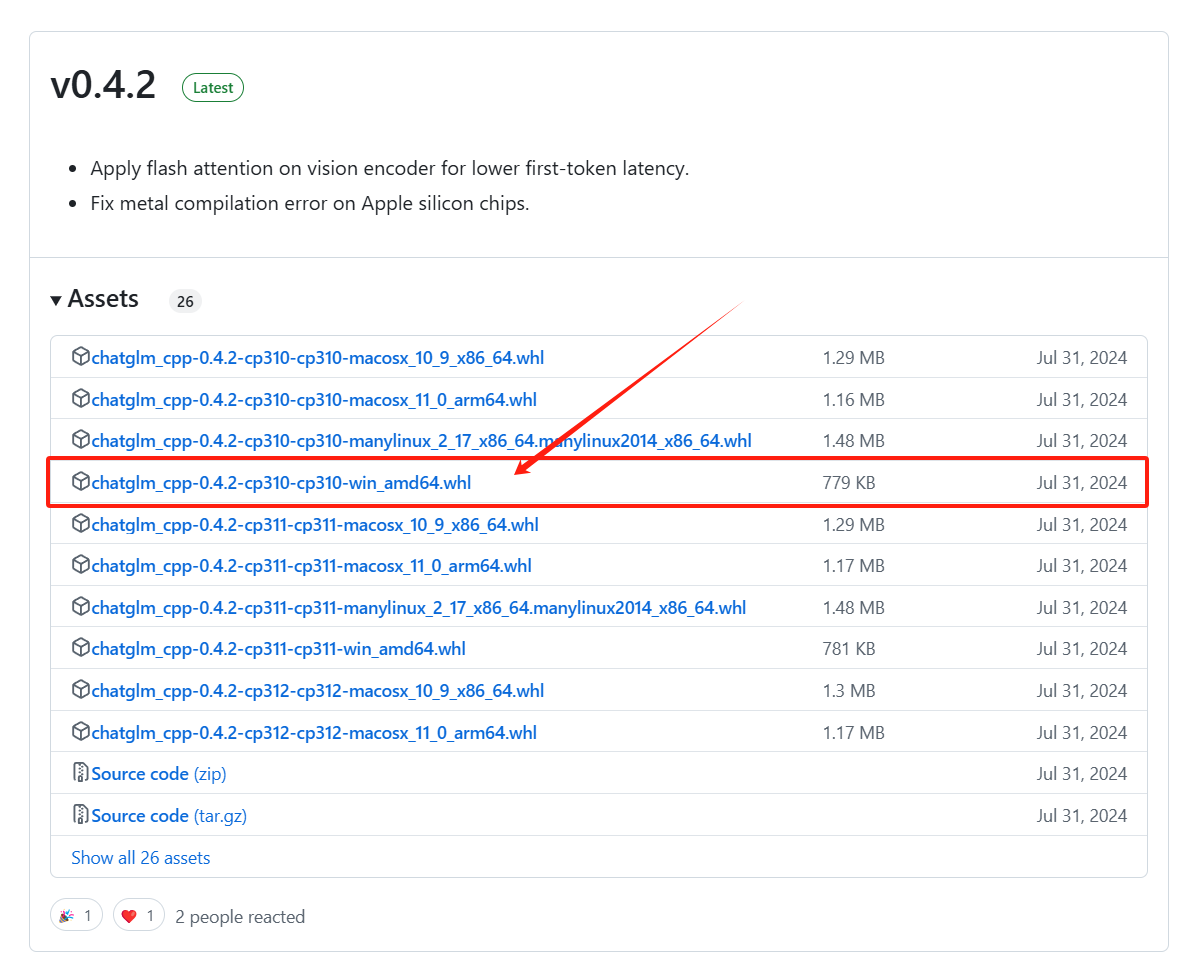
切换到刚下载的文件所在目录,运行指令:
pip install chatglm_cpp-0.4.2-cp310-cp310-win_amd64.whl

(4)安装c、c++编译工具(为安装llama-cpp-python做准备,防止编译出错)
https://visualstudio.microsoft.com/zh-hans/visual-cpp-build-tools/
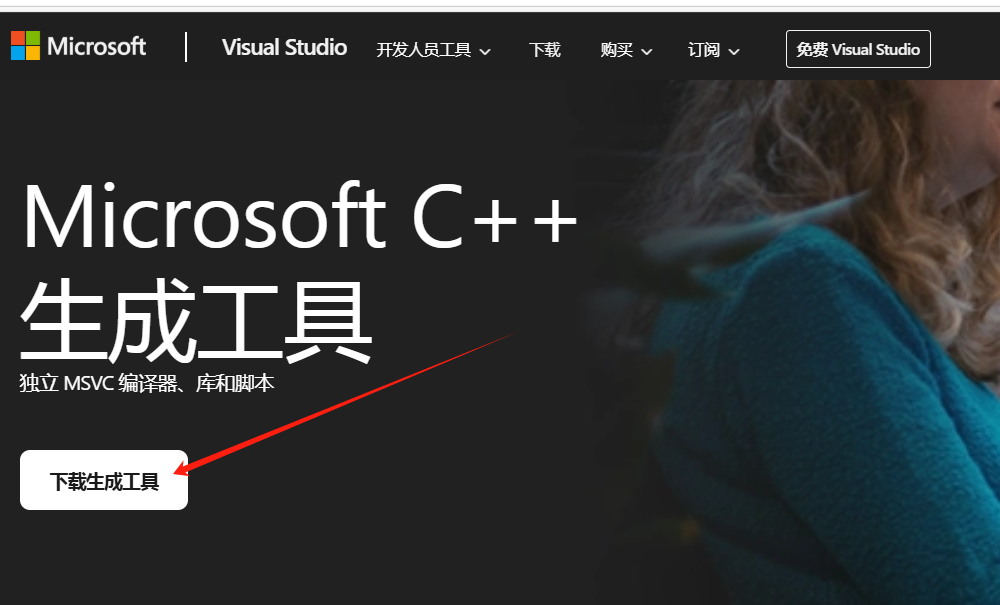
选择“使用C++的桌面开发”安装,如下图:

安装后,从Visual Studio 2022安装的入口打开命令行,再进入conda虚拟环境。(这个地方折腾了好一两个小时,一直出现llama-cpp-python编译错误,最终用此方法解决)还有要注意登录用户需有administrator权限,最好直接使用administrator用户。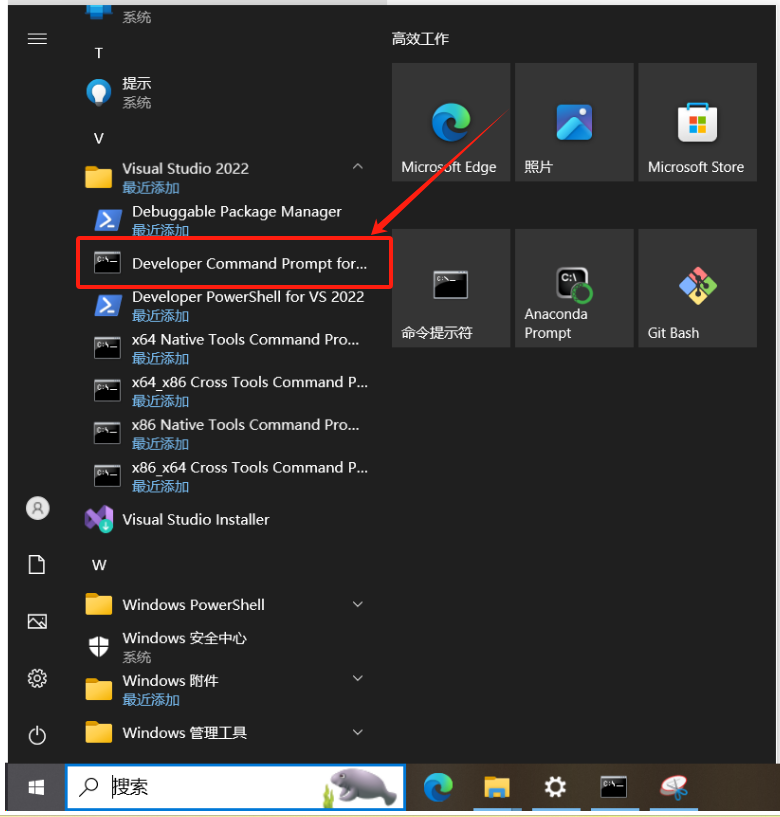
在打开的窗口中敲入指令:(具体根据自己conda的安装路径来改)
%WINDIR%\System32\cmd.exe "/K" D:\ProgramFiles\miniconda3\Scripts\activate.bat D:\ProgramFiles\miniconda3
可以单独先安装pip install llama-cpp-python看看能不能成功,再进行下一步。
2.安装Xinfernece
pip install xinference[all]
xinference有好几种支持的模型种类,用all参数代表全部安装,这样以后不管接入哪种大模型都不需要再次安装了。
3.检验环境是否安装成功
检验pytorch是否支持gpu,运行python指令
import torch
print(torch.__version__)
print(torch.cuda.is_available())
如果报错,运行下面指令安装支持gpu的依赖包。(根据自己显卡配置确定cuda版本号)
pip install torch==2.6.0+cu124 torchvision==0.21.0+cu124 torchaudio==2.6.0+cu124 --index-url https://download.pytorch.org/whl/cu124
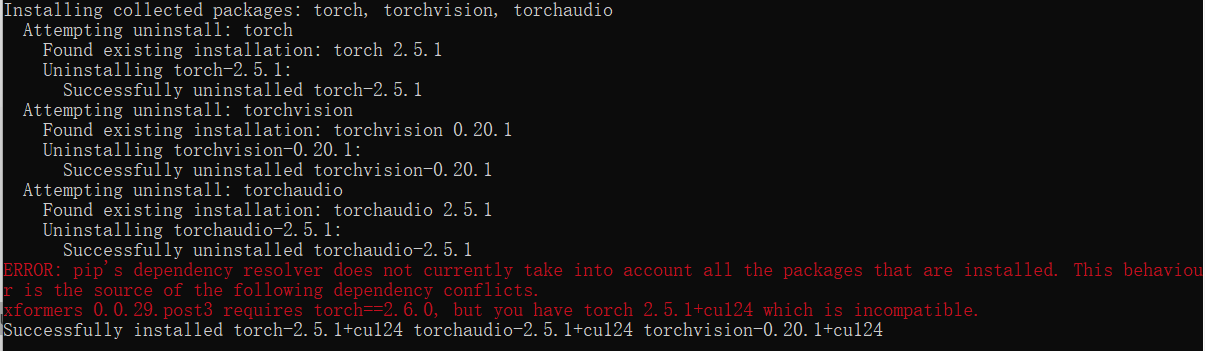
上面安装时报xformer不兼容,可以到面查找对应的版本进行安装https://github.com/facebookresearch/xformers#installing-xformers
命令:
pip3 install -U xformers --index-url https://download.pytorch.org/whl/cu124
安装后验证是否成功:

三、启动Xinference
xinference-local --host 127.0.0.1 --port 9999
ip地址可以改成局域网的地址,这样就可以在企业内共享了。

运行成功后界面如下
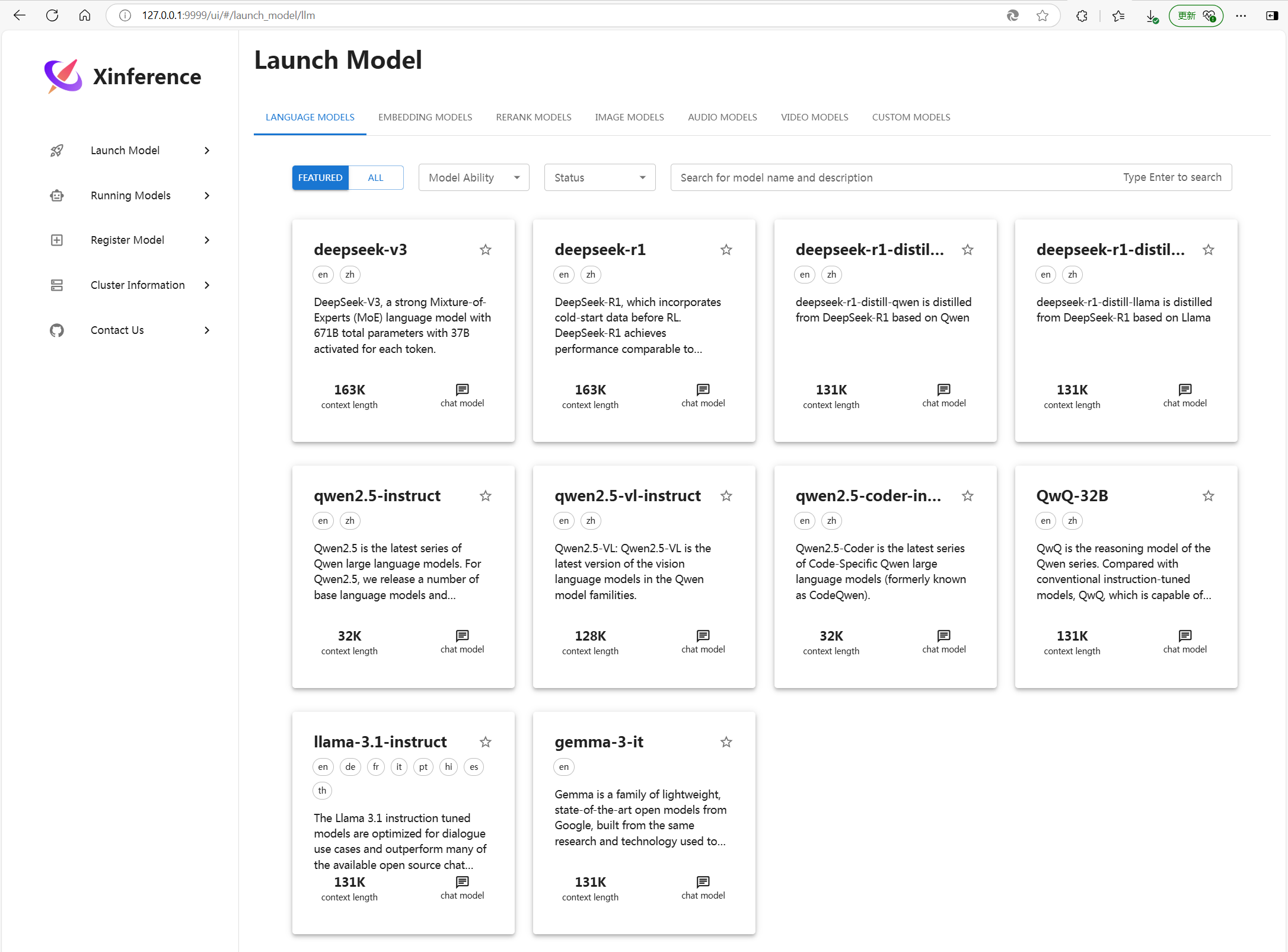
四、配置注册模型文件
1.下载模型文件
到https://huggingface.co/deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B
上下载deepseek模型,除了模型文件,标红框的配置文件也要下载,存放在模型的同一目录中。
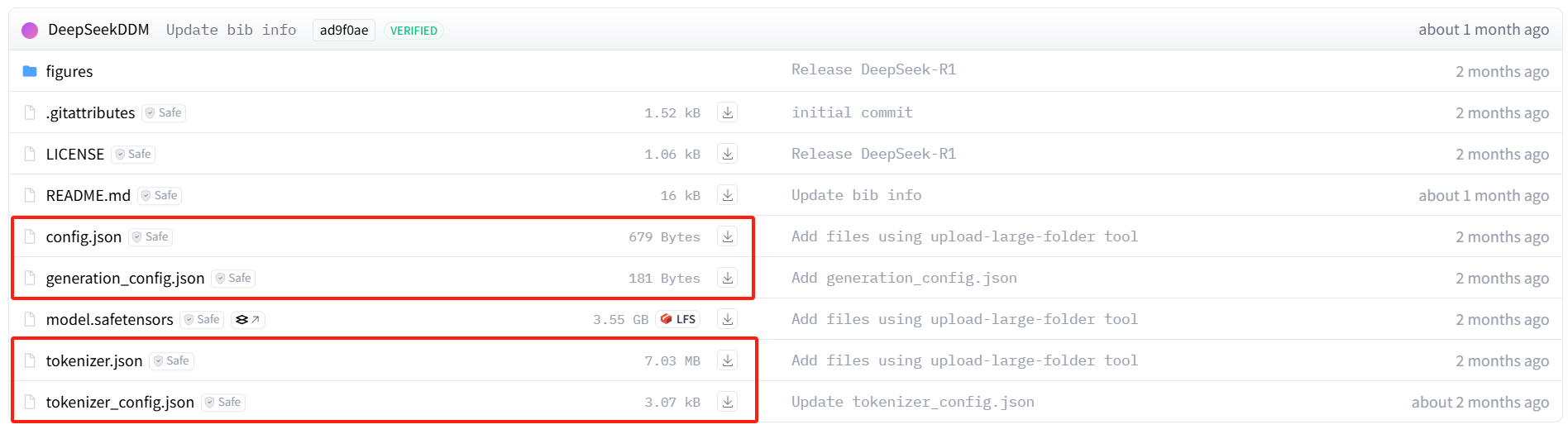
2.注册模型文件
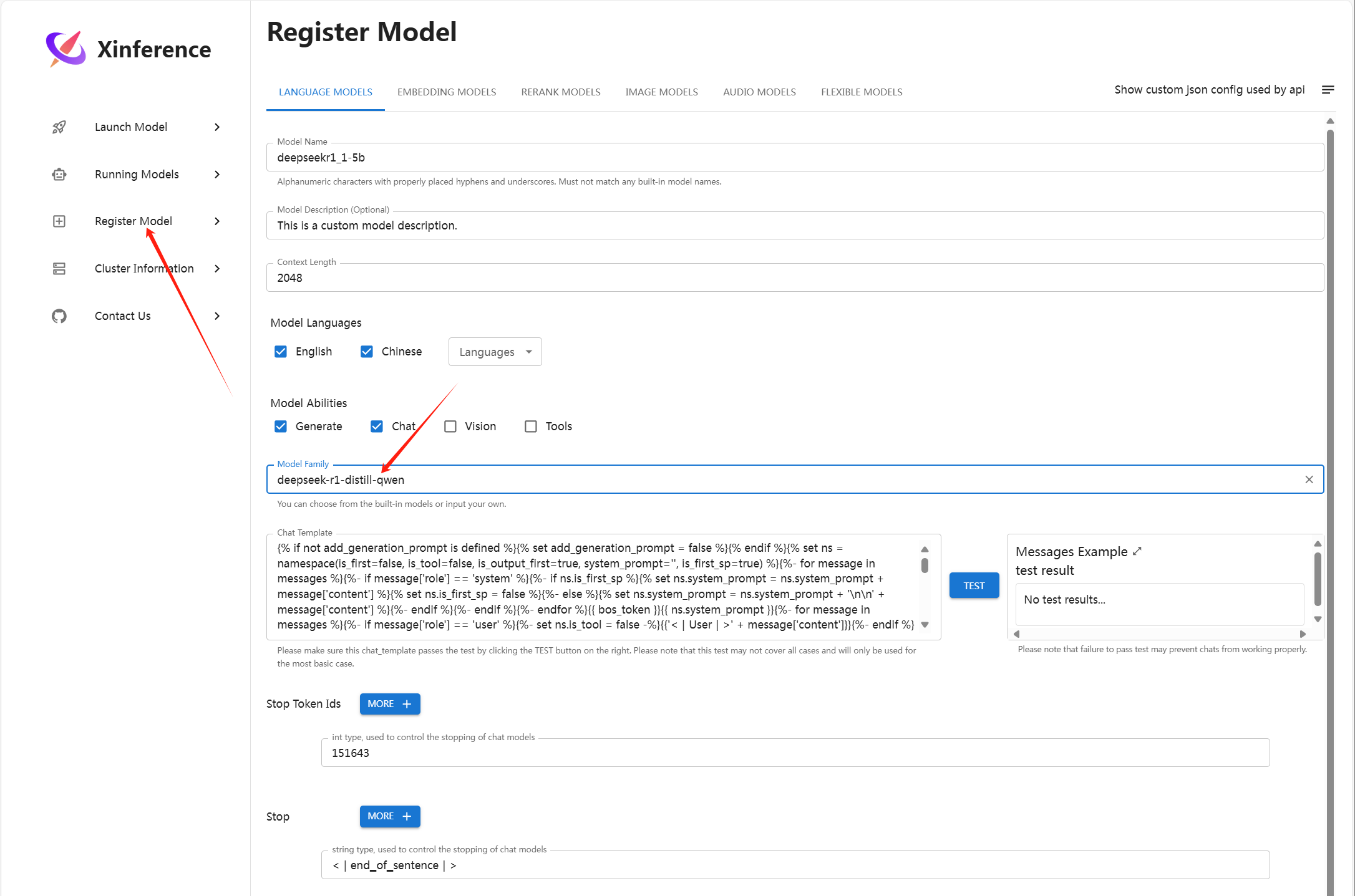
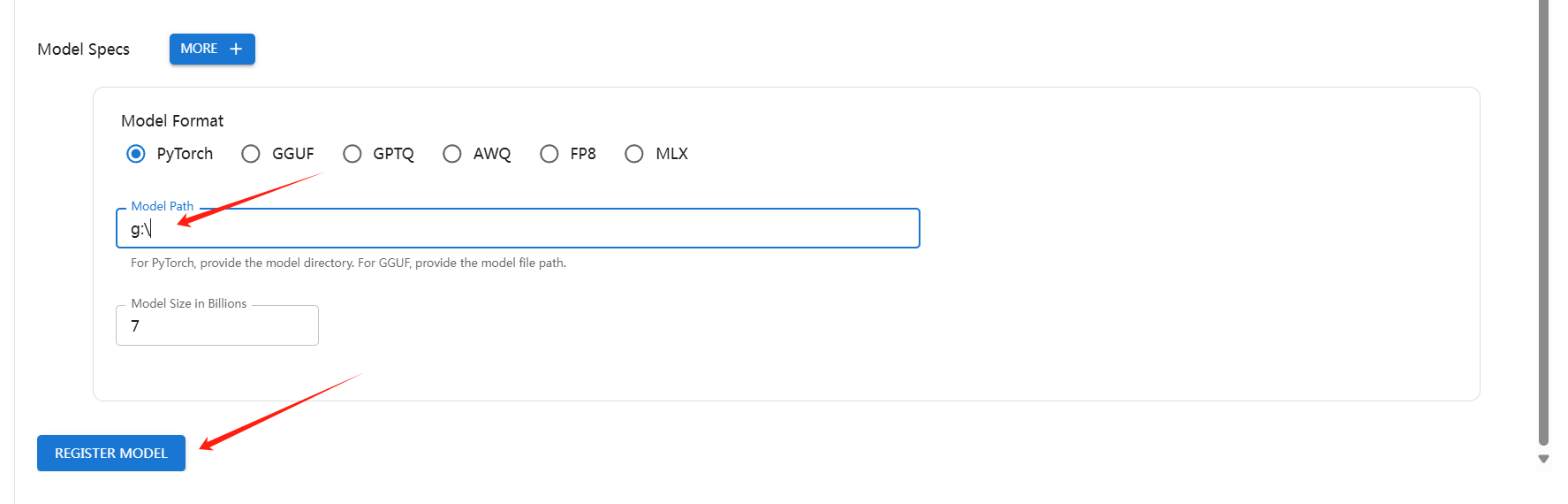
3.启动模型文件


五、体验与模型对话
点击下图箭头处,可以启动与大模型的聊天
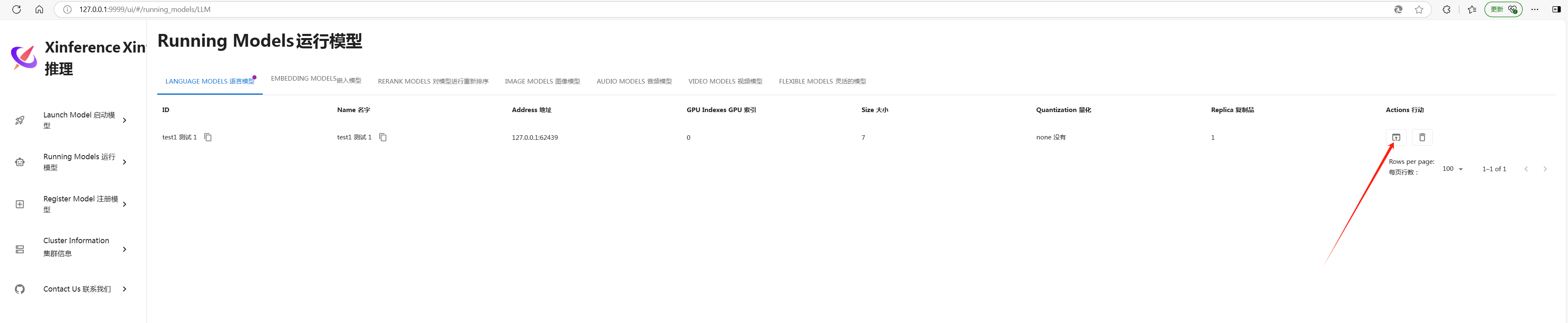
聊天展示如下
使用conda创建的虚拟环境和安装的依赖包,往同类操作系统复制时,只要直接拷贝过去即可,基本可以与docker的跨系统部署相媲美了。我就是在自己机器上安装好了直接拷贝到服务器上的,正常运行。