刚刚完成了基于YOLOv11火灾检测的实验,仅以此记录下来给需要帮助的小伙伴提供参考。火灾检测在安全监控、工业生产和森林保护等领域至关重要,而随着计算机视觉技术的进步,像YOLOv11这样的实时目标检测模型为我们提供了高效、精准的解决方案。在这篇博客中,我将详细介绍如何基于预训练权重,利用公共数据集完成火灾检测的全流程,包括数据集划分、模型训练、验证、推理、可视化,以及超参数调节。同时,我还会展示如何支持图片、视频和外置相机的识别,探讨学术界与工业界的常见方法,并分享一些实用经验。希望这篇内容逻辑清晰、干货满满且易于理解!
一、引言
火灾是一种突发性强、危害极大的灾害,传统的烟雾传感器或热成像仪在开放环境或复杂场景下往往效果有限。而基于视觉的火灾检测因其覆盖范围广、响应速度快而备受关注。YOLOv11,作为Ultralytics推出的最新一代实时目标检测模型,以其高效性和准确性在计算机视觉领域脱颖而出。特别是其轻量级版本yolo11n.pt(nano版),非常适合资源受限的边缘设备,这对于实时火灾检测来说尤为重要。以下是yolo11在coco数据集上的性能表现
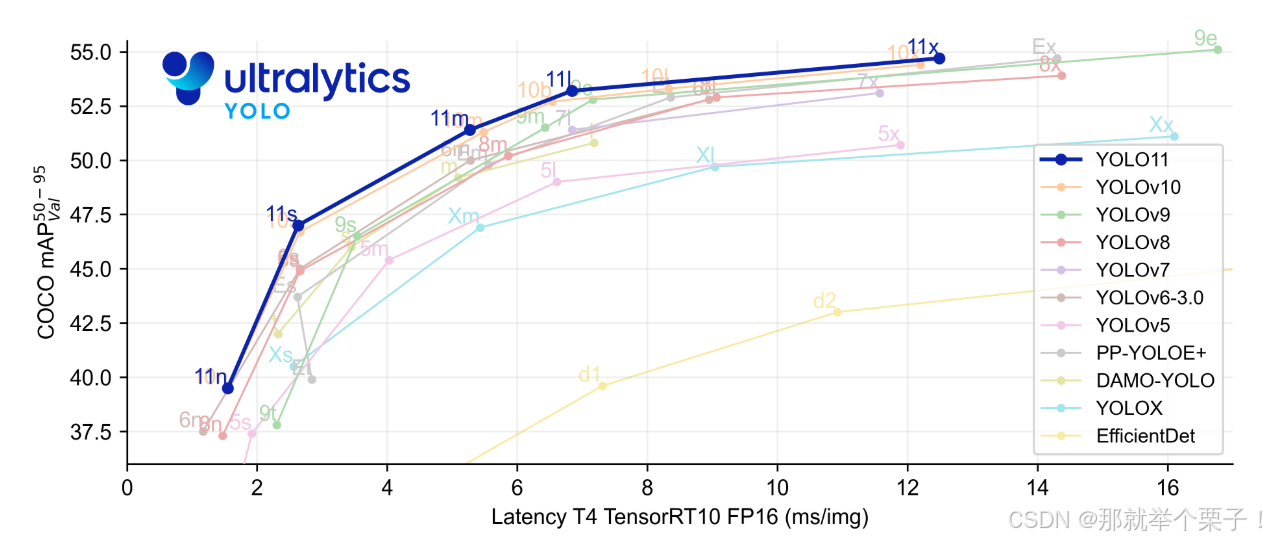
在这次实验中,我的目标是利用YOLOv11的预训练权重,结合公共火灾数据集,完成一个完整的火灾检测系统。我不仅实现了训练和推理,还支持了多种输入形式(图片、视频、外置相机),并对超参数进行了优化。接下来,我将逐一展开实验过程,并分享一些关键经验。
二、数据集准备
数据是深度学习模型的基石。对于火灾检测,我选择了一个公共数据集—— 是一个火灾和烟雾事件图像数据集,它包含了多种场景下的火灾图像,包括不同光照条件、背景和火势大小,专为机器学习和物体检测算法而设计,包含超过 21,000 张图像。
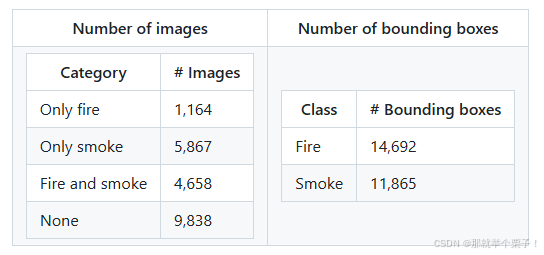
1、数据集划分
为了让模型更好地泛化,我将数据集划分为三个部分:
- 训练集(70%):用于模型的学习。
- 验证集(15%):用于监控训练过程中的性能,防止过拟合。
- 测试集(15%):用于最终评估模型的泛化能力。
划分时,我确保了各类场景的分布均匀,避免某一类火情(如夜间火灾)只出现在某个子集中
整个数据集比较友好,已经进行了标注并支持yolo格式,因此我们无需进行标注
如果你需要自己标注数据,在这里推荐两个标注软件,一个是labellimg,一个是labelme,可以在python环境中使用,使用pip install labelimg 或者 pip install llabelme 进行安装
安装完成之后在终端输入命令启动标注软件即可:
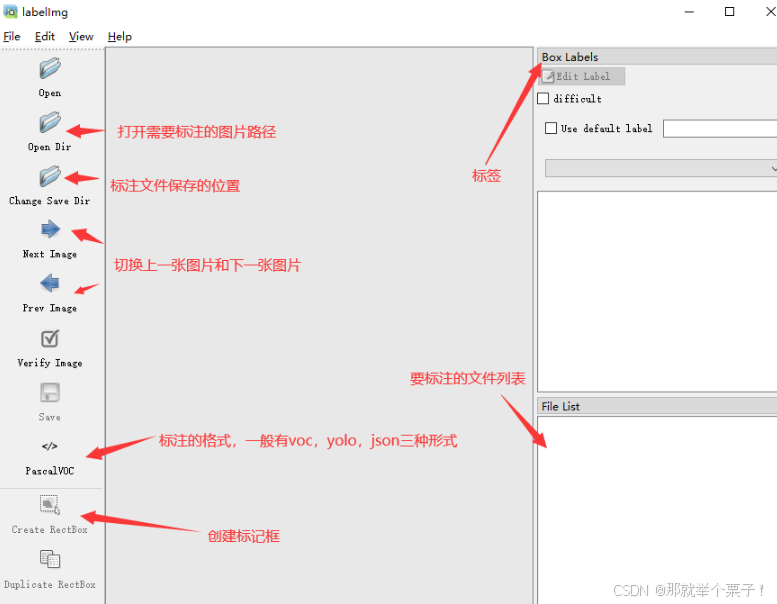
注意要设置自动保存生成的标注文件!!此外,标注的时候要选择yolo格式,如果选择了voc格式还需要进行转换。
TIPS:如果数据集较小,可以尝试数据增强(如翻转、旋转、调整亮度)来增加多样性。我在实验中使用了这些技巧,效果显著。
2、编写数据集配置文件data.yaml
YOLO通过一个data.yaml配置文件加载数据集,指定训练、验证、测试数据的路径和类别信息,因此data.yaml这个非常重要!!
以下是标准格式:
train: /path/to/train/images
val: /path/to/val/images
test: /path/to/test/images # 可选
nc: 类别数量
names: ['类别0', '类别1', ...]
字段说明:
- train/val/test:训练、验证、测试集的图像文件夹路径,或包含图像路径的txt文件。
- nc:类别总数。
- names:类别名称列表,与标注中的class_id对应。
关于本项目的data.yaml文件内容如下:

TIPS:类别名称要和class_id一一对应,尽量不要写中文,避免有乱码!!
训练集用于模型学习,验证集用于调参和监控训练过程,测试集用于最终评估性能。三者是一般是从同一批原始数据中划分出的互不重叠的子集。
三、基于yolo11的环境搭建
1、创建虚拟环境
首先,我们选择anaconda创建conda虚拟环境
 因为yolo官方要求python>=3.8 因此我们使用以下命令创建虚拟环境
因为yolo官方要求python>=3.8 因此我们使用以下命令创建虚拟环境
conda create -n yolo11 python=3.9
接下来,我们可以通过以下命令去查看我们创建的虚拟环境:
conda env list
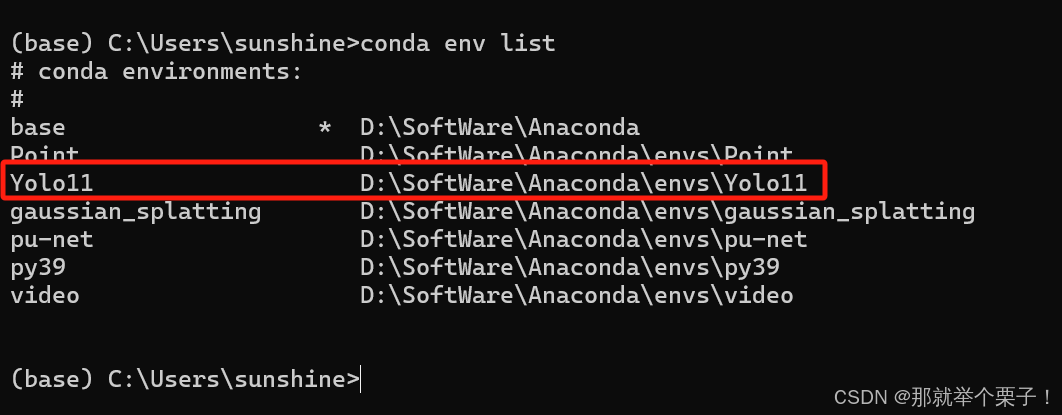
如果可以显示出创建的虚拟环境就表示已经创建好了
2、安装Pytorch
接下来我们使用以下命令激活刚刚安装好的虚拟环境
conda activate yolo11 #你如果虚拟环境是其他名字进行替换就好了
然后,我们使用以下命令安装Pytorch:
pip install torch==2.1.0 torchvision==0.16.0 torchaudio==2.1.0 --index-url https://download.pytorch.org/whl/cu118
我们安装的Pytorch版本是2.1.0 cuda11.8 ,如果你想使用其他的版本也可也去Pytorch官网找对应的命令进行安装
可能很多时候这个命令比较慢,因为访问外部链接的原因,我们可以使用国内的源进行加速,比如清华源,中科大源都可以,亲测有效!
3、配置yolo环境
yolo5-11环境都是通用的,只需要安装一次就可以,执行以下一行命令即可:
pip install ultralytics
等待执行完成即可,是不是非常简单!!!
四、训练
我们使用Pycharm作为IDE导入创建好的yolo环境,编写训练代码,YOLOv11的强大之处在于其预训练权重,我们无需从零开始训练。yolo11n.pt是一个轻量级模型,适合实时应用,我以此为基础进行微调。
1、加载预训练权重:
from ultralytics import YOLO
model = YOLO("yolo11n.pt")
2、微调模型
results = model.train(
data="D-Fire/data.yaml", # 数据集配置文件
epochs=50, # 训练轮次,根据数据集大小调整
imgsz=640, # 输入图像尺寸,表示640x640
batch=16 # 批次大小,取决于现存大小
)
训练完成后,结果保存在runs/detect目录下,包括最佳模型权重和性能指标。
必须设置data、model、imgsz、batch、epochs,其他参数可根据需要调整
训练过程中,模型会根据损失函数(如分类损失和边界框回归损失)调整权重,逐步学会识别火灾特征
五、模型验证:
训练完成后,我用验证集评估模型的表现。YOLOv11支持多种指标,包括精度(Precision)、召回率(Recall)和mAP(mean Average Precision),后者是目标检测的标准指标
验证代码如下:
val_results = model.val()
我们也可也通过命令行进行模型验证,结果如下

经验分享:如果召回率不足,可以调整检测的置信度阈值(confidence threshold);如果假阳性较多,可以增加负样本(如无火场景)来改进模型。
五、推理与可视化:让模型“看到”火灾
训练好的模型可以用于推理,即在新的数据上检测火灾。我测试了三种输入形式:图片、视频和外置相机。
1、图片推理:
对于单张图片,推理和可视化非常直观:
from ultralytics import YOLO
# Load a pretrained YOLO11n model
model = YOLO("yolo11n.pt")
# Define path to the image file
source = "path/to/image.jpg"
# Run inference on the source
results = model(source) # list of Results objects



模型会输出火灾的边界框和置信度,结果一目了然。
2、视频推理
使用opencv配合即可完成视频推理
import cv2
from ultralytics import YOLO
# Load the YOLO model
model = YOLO("yolo11n.pt")
# Open the video file
video_path = "path/to/your/video/file.mp4"
cap = cv2.VideoCapture(video_path)
# Loop through the video frames
while cap.isOpened():
# Read a frame from the video
success, frame = cap.read()
if success:
# Run YOLO inference on the frame
results = model(frame)
# Visualize the results on the frame
annotated_frame = results[0].plot()
# Display the annotated frame
cv2.imshow("YOLO Inference", annotated_frame)
# Break the loop if 'q' is pressed
if cv2.waitKey(1) & 0xFF == ord("q"):
break
else:
# Break the loop if the end of the video is reached
break
# Release the video capture object and close the display window
cap.release()
cv2.destroyAllWindows()
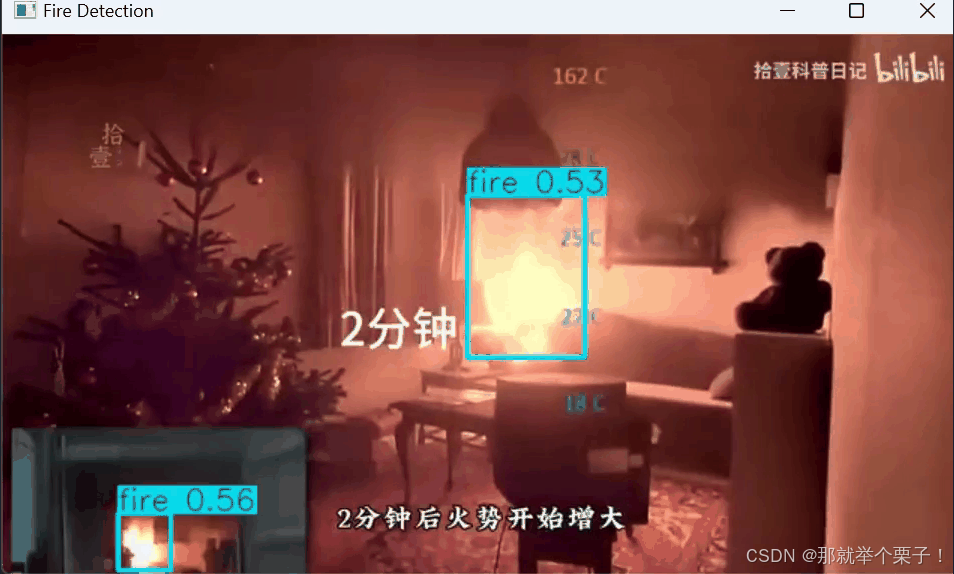


YOLOv11的实时性让我印象深刻,即使在普通GPU上也能保持较高的帧率。
3、外置相机实时推理
我还接入了笔记本的外置摄像头,实现了实时检测:
import cv2
cap = cv2.VideoCapture(0) # 默认摄像头
while True:
ret, frame = cap.read()
if not ret:
break
results = model(frame)
results.show()
if cv2.waitKey(1) & 0xFF == ord('q'): # 按q退出
break
cap.release()
cv2.destroyAllWindows()
这段代码将摄像头捕捉的画面实时输入模型,检测结果直接显示在窗口中,非常适合监控场景。
六、超参数调节
YOLO(如YOLOv8)内置了许多默认参数,可以不手动设置,但根据任务需求调整会更好。常见可选参数包括:
optimizer:优化器,默认SGD,可选Adamw。
lr0:初始学习率,默认0.01。如果选了adamw作为优化器 学习率建议设置0.001
lrf:最终学习率,用于学习率调度。
workers:数据加载线程数,默认8。
device:训练设备,如0(GPU)或cpu。
project和name:训练结果保存目录和名称。
建议:初次训练可使用默认值,观察效果后再调整。
此外还有一些别的超参数设置
cos_lr=True:启用余弦退火学习率调度策略(Cosine Annealing Learning Rate Scheduler)。这种策略会在训练过程中逐渐降低学习率,有助于模型在训练后期更精细地调整参数
plots=True:训练过程中生成可视化图表,如损失曲线、mAP(mean Average Precision)曲线等,方便用户直观地了解训练过程和模型性能
mixup=0.1:启用 MixUp 数据增强方法,混合系数为 0.1。MixUp 是一种将不同样本按一定比例混合的增强方法,可以提高模型的鲁棒性
patience=10:早停(early stopping)的轮数。如果在连续 10 轮的训练中,验证集的 mAP 没有提升,则停止训练,避免不必要的计算资源浪费
amp=True:启用自动混合精度训练(Automatic Mixed Precision)。这种技术可以在不显著损失模型精度的情况下,减少训练过程中的内存使用和计算时间,加快训练速度。
主流训练策略(以YOLO11为例)
预训练微调:
使用预训练权重(如yolo11n.pt或yolo11m.pt)初始化模型,加速收敛。
- 数据增强:
YOLO11内置mosaic、mixup等增强技术,提升模型鲁棒性。 - 学习率调度:
使用Cosine Annealing等策略动态调整学习率。 - 性能监控:
通过验证集上的mAP(平均精度均值)选择最佳模型。 - 优化建议
调整anchor boxes:根据数据集的目标尺寸优化锚框。
早停(Early Stopping):如果验证集性能长时间不提升,提前停止训练。
自动混合精度(AMP):YOLO11默认支持,加速训练并减少显存占用。
梯度累积:若显存不足,可设置较小batch size并累积梯度。
调节时,我采用了手动尝试+观察的策略:先用默认参数训练几轮,记录验证集表现,然后逐步调整。例如,当我发现模型收敛较慢时,略微提高了学习率;当损失开始波动时,又降低了它。
进阶建议:如果时间充裕,可以尝试网格搜索(grid search)或随机搜索(random search)来系统性地优化超参数。
七、总结与思考
1、火灾检测技术经历了从传统到现代的演变,以下是几种常见方法:
- 传统方法:如烟雾传感器和热成像仪,依赖物理特性,成本高且覆盖范围有限。
- 基于颜色:利用火焰的红黄色特征,但对光照变化敏感。
- 深度学习:如CNN和YOLO,通过大规模数据学习特征,已成为主流。
YOLOv11属于深度学习方法中的佼佼者,其单阶段检测(one-stage detection)设计兼顾了速度和精度,远超传统的多阶段方法(如Faster R-CNN)。
2、学术界与工业界的不同视角
在实验过程中,我也在思考学术界和工业界如何处理火灾检测问题:
学术界
- 目标:追求更高的准确度和鲁棒性。
- 数据集:倾向于使用多样化的数据集(如不同天气、火势),常通过数据增强扩充样本。
- 模型选择:可能尝试多种架构(如YOLOv11的不同变体或Transformer模型),以探索性能极限。
- 超参数调节:更系统化,常使用自动化工具(如Optuna)优化。
工业界
- 目标:注重实时性和部署便捷性。
- 数据集:偏向特定场景(如工厂、城市监控),数据量可能较小但更聚焦。
- 模型选择:倾向轻量级模型(如YOLOv11n),以适配边缘设备。
- 超参数调节:多从默认值出发,快速迭代,强调实用性而非极致性能。
通过这次实验,我成功利用YOLOv11构建了一个高效的火灾检测系统。从数据集准备到模型训练,再到推理和超参数优化,每一步都让我深刻体会到深度学习的强大和细节的重要性。以下是几个关键收获:
- 预训练权重加速了开发进程,yolo11n.pt特别适合实时任务。
- 数据集划分和增强是模型泛化的关键。
- 推理支持多样化输入让应用场景更广。
- 超参数调节需要耐心和经验,但回报显著。