此前篇章:
引言:在时间序列分析中,平稳序列建模是核心环节之一。通过合理的建模,我们可以深入理解数据的内在规律,并对未来趋势进行预测。本文将根据平稳序列建模的步骤,详细讲解每个环节的操作方法和注意事项,帮助读者掌握平稳序列建模的全流程。
注:本文默认序列是平稳的,非平稳序列的处理和建模后续文章再深入讲解。
一、确定序列是平稳非白噪声序列
1、平稳性检验
平稳性是时间序列建模的前提条件。一个平稳序列的均值、方差和自协方差在时间上保持不变。常用的平稳性检验方法有:
-
单位根检验:如ADF检验和PP检验。这些检验的原假设是序列存在单位根(即非平稳),如果检验结果拒绝原假设,则序列是平稳的。
-
KPSS检验:KPSS检验的原假设是序列是平稳的,如果检验结果拒绝原假设,则序列是非平稳的。
2、白噪声检验
白噪声序列是指均值为零、方差恒定且各观测值之间相互独立的序列。如果一个序列是白噪声,那么它没有任何有用的信息,建模也就失去了意义。常用的白噪声检验方法有:
-
Ljung-Box检验:检验序列的自相关性,如果序列是白噪声,则其自相关系数在所有滞后阶数上都应接近于零。Ljung-Box检验的原假设是序列的自相关系数为零,如果检验结果拒绝原假设,则序列不是白噪声。
二、计算ACF和PACF
自相关函数(ACF)衡量的是序列与其滞后值之间的相关性。通过计算不同滞后阶数的自相关系数,可以了解序列的自相关结构。
1、自相关函数(ACF)
自相关函数(ACF)衡量的是序列与其滞后值之间的相关性。通过计算不同滞后阶数的自相关系数,可以了解序列的自相关结构。
2、偏自相关函数(PACF)
偏自相关函数(PACF)衡量的是序列与其滞后值之间的相关性,排除了中间滞后值的影响。通过计算不同滞后阶数的偏自相关系数,可以了解序列的偏自相关结构。
3、计算方法与图形解读
-
使用统计软件:如Python的
statsmodels库或R语言的forecast包,可以方便地计算序列的ACF和PACF,并绘制相应的图形。 -
图形解读:通过观察ACF和PACF图,可以初步判断序列的自相关和偏自相关特征,为后续的模型识别提供依据(通常用于识别模型的阶数)。
三、模型识别
模型阶数的初步识别:根据ACF和PACF的图形特征,可以初步确定模型的阶数
-
AR(p)模型:ACF呈拖尾,PACF在滞后p阶后截尾。
-
MA(q)模型:ACF在滞后q阶后截尾,PACF呈拖尾。
-
ARMA(p, q)模型:ACF和PACF都呈拖尾,但衰减速度不同。
很多时候,图形不是理论上那么完美的拖尾或截尾,我们只是做初步判断模型阶数,最好结合两倍误差原则,以提高定阶准确率,后续还要进行模型检验,检验不通过可能这里的模型定阶错误,需要重新定阶。
四、估计模型中未知参数的值——参数估计
平稳序列的待估计参数:以非中心化的ARMA(p, q)模型为例,
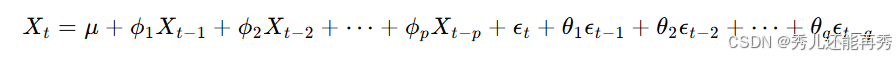
待估计参数有,,共p+q+2个待估计参数,对于中心化后的模型,少了一个μ参数。
对于 μ 参数,通常用矩估计方法,用样本均值估计总体均值:
参数估计方法
1、矩估计:在时间序列分析中,矩估计是一种通过匹配样本矩(如均值、自协方差等)与理论矩来估计模型参数的方法。其核心思想是:通过样本计算的统计量(矩)与模型理论推导的矩相等,构建方程组求解参数。
2、最大似然估计(MLE):极大似然估计通过最大化模型的似然函数来估计参数。它假设数据服从某种分布(如正态分布),并寻找使观测数据出现概率最大的参数。
-
优点:
-
在大样本条件下,估计结果具有一致性、渐近正态性和渐近有效性。
-
适用于多种类型的模型,包括ARIMA、GARCH等。
-
-
缺点:
-
计算复杂度较高,尤其是对于复杂的模型。
-
对模型假设(如分布假设)较为敏感。
-
3、最小二乘法(OLS):通过最小化观测值与模型预测值之间的平方差来估计模型参数。适用于线性模型,这种方法在AR模型中特别有用。
-
优点:
-
计算简单,易于实现。
-
在样本量较大时,估计结果具有良好的渐近性质。
-
-
缺点:
-
对异常值敏感,因为平方误差会放大较大的误差。
-
仅适用于线性模型,对于非线性模型效果不佳。
-
4、Yule-Walker估计:Yule-Walker估计是专门用于AR模型的参数估计方法,通过样本自协方差函数来估计模型参数。
-
优点:
-
计算效率高,适合小样本数据。
-
在样本量较小时,估计结果通常比最小二乘法更稳定。
-
-
缺点:
-
仅适用于AR模型,不适用于其他类型的时序模型。
-
对于高阶AR模型,估计精度可能不如最小二乘法。
-
| 方法 | 适用模型 | 优点 | 缺点 |
|---|---|---|---|
| 最小二乘法 | 线性模型(如AR) | 计算简单,渐近性质良好 | 对异常值敏感,仅适用于线性模型 |
| 极大似然估计 | 通用,需明确似然函数 | 渐近性质优良,适用范围广 | 计算复杂,对模型假设敏感 |
| 矩估计 | 通用,适用于复杂矩条件 | 计算简单,不依赖分布假设 | 估计精度低,适用范围有限 |
| Yule-Walker估计 | AR模型 | 计算效率高,适合小样本 | 仅适用于AR模型,高阶模型精度较低 |
关键总结:
-
矩估计:灵活但可能低效,通过矩匹配无需分布假设。
-
MLE:依赖分布假设,但模型正确时最优。
-
OLS:线性回归专用,最小化残差平方和。
五、模型检验
(一)模型的显著性检验(核心)
一个好的拟合模型应该能够提取序列中绝大部分的样本相关信息,换句话来说。拟合残差项不再包含任何相关信息,即残差序列应该为白噪声序列,否则说明拟合的模型不够有效,通常需要选择其他模型来重新拟合。
因此,模型的显著性检验即为残差序列的白噪声检验。白噪声检验之前的文章讲过,不在多讲。
(二)参数的显著性检验
这部分任务就是要检验每一个未知参数是否显著不为零。目的是使模型最精简。如果某个参数不显著,即表示该参数所对应的那个自变量对因变量的影响不明显,可以选择拟合模型中剔除该自变量。最终模型由一系列显著非零的自变量表示。
使用一些数据分析工具,主要有以下检验方法:
- t检验:通过计算参数估计值与其标准误差的比值(t统计量),判断参数是否显著非零。
- 置信区间:通过计算参数估计值的置信区间,判断区间是否包含零。
六、模型优化
若一个拟合模型通过了检验,说明在一定置信水平下,该模型能够有效拟合观察值序列的波动,但这种有效模型并不一定是唯一的。换句话说,就是可能有比该模型更好的模型。
假如,我们先拟合了一个MA(2)模型并通过了模型检验,我们再回到模型定阶阶段,发现也可以用AR(1)模型,也通过了模型检验,那么哪个模型更好呢?
对于上述问题,可以通过AIC或BIC信息准则进行模型优化,选择最优模型。
模型选择准则
-
信息准则:如AIC和BIC,这些准则在模型拟合优度和复杂度之间进行权衡,通常选择AIC或BIC值最小的模型。
-
交叉验证:通过将数据集分为训练集和验证集,评估模型在验证集上的表现,选择表现最优的模型。
AIC
定义:AIC 是一种统计模型选择准则,用于评估不同模型的拟合优度和复杂度。其公式为:
其中,L 是模型的最大似然函数值,k 是模型参数的数量。
作用 :AIC 在模型选择中惩罚了过高的复杂度(即过多的参数),从而防止模型过拟合。选择具有最低 AIC 值的模型作为最优模型。
特点与性质:
相对比较:AIC本身并不提供模型“绝对”优劣的判断,而是用于在多个候选模型中进行相对比较,选择AIC值最小的模型。
非绝对性:AIC值的大小没有绝对意义,仅用于比较不同模型的相对优劣。
广泛适用:适用于任何可以计算最大似然估计的模型,包括线性回归、逻辑回归、时间序列模型、混合模型等。
BIC
定义:BIC 是另一种统计模型选择准则,类似于 AIC,但对模型复杂度的惩罚更为严格。其公式为:
其中,L 是模型的最大似然函数值,k 是模型参数的数量,n 是样本数量。
作用 :BIC 在模型选择中对复杂度的惩罚力度更大,特别是在较大的样本量下。它倾向于选择更简单的模型以避免过拟合。
特点与性质:
相对比较:与AIC类似,BIC本身并不提供模型“绝对”优劣的判断,而是用于在多个候选模型中进行相对比较,选择BIC值最小的模型作为最优模型。
贝叶斯基础:BIC源自贝叶斯概率理论,旨在近似贝叶斯后验概率,通过惩罚模型复杂度来避免过拟合。
广泛适用:适用于任何可以计算最大似然估计的模型,包括线性回归、逻辑回归、时间序列模型、混合模型等。
AIC与BIC的对比与选择:
准则 核心差异 适用场景 AIC 惩罚项较轻(2k) 侧重预测精度,接受稍复杂的模型 BIC 惩罚项较重(k lnn) 侧重模型简洁性,大样本下更倾向简单模型
经验选择:
若追求样本外预测效果,优先AIC。
若相信真实模型较简单或样本量大,优先BIC。
七、序列预测
前面我们进行了平稳性检验、白噪声检验、模型选择、参数估计、模型检验等工作,最终目的就是要利用这个拟合模型对随机序列的未来取值进行预测。对于这部分内容,我们只要计算出预测值和置信区间即可,在业务场景中用于辅助决策。
注:文章还是停留在理论部分,实操后续再写
# 文章如有错误,欢迎大家指正。我们下册再见叭