题目描述
如题,给定一棵有根多叉树,请求出指定两个点直接最近的公共祖先。
输入输出格式
输入格式:
第一行包含三个正整数N、M、S,分别表示树的结点个数、询问的个数和树根结点的序号。
接下来N-1行每行包含两个正整数x、y,表示x结点和y结点之间有一条直接连接的边(数据保证可以构成树)。
接下来M行每行包含两个正整数a、b,表示询问a结点和b结点的最近公共祖先。
输出格式:
输出包含M行,每行包含一个正整数,依次为每一个询问的结果。
输入输出样例
说明
时空限制:1000ms,128M
数据规模:
对于30%的数据:N<=10,M<=10
对于70%的数据:N<=10000,M<=10000
对于100%的数据:N<=500000,M<=500000
样例说明:
该树结构如下:
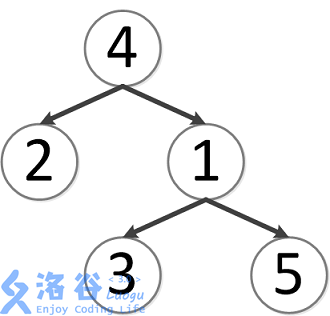
第一次询问:2、4的最近公共祖先,故为4。
第二次询问:3、2的最近公共祖先,故为4。
第三次询问:3、5的最近公共祖先,故为1。
第四次询问:1、2的最近公共祖先,故为4。
第五次询问:4、5的最近公共祖先,故为4。
故输出依次为4、4、1、4、4。


/* 倍增写法 常数略大 我觉得不太好理解 所以我不用倍增了 */ #include <bits/stdc++.h> using namespace std; const int MAXN = 500010; int deep[MAXN],f[MAXN][25],lg[MAXN],head[MAXN],cnt; int n,m,s; struct node{ int to,pre; }G[MAXN*2]; void add(int from,int to){ G[++cnt].to = to; G[cnt].pre = head[from]; head[from] = cnt; } inline int read() { int x = 0,m = 1; char ch; while(ch < '0' || ch > '9') {if(ch == '-') m = -1;ch = getchar();} while(ch >= '0' && ch <= '9'){x = x*10+ch-'0';ch=getchar();} return m * x; } inline void dfs(int u) { for(int i = head[u];i;i = G[i].pre) { int v = G[i].to; if(v != f[u][0]) { f[v][0] = u; deep[v] = deep[u] + 1; dfs(v); } } } inline int lca(int u,int v) { if(deep[u] < deep[v]) swap(u,v); int dis = deep[u] - deep[v]; for(register int i = 0;i <= lg[n];i++) { if((1 << i) & dis) u = f[u][i]; } if(u == v) return u; for(register int i = lg[deep[u]];i >= 0;i--) { if(f[u][i] != f[v][i]) { u = f[u][i];v = f[v][i]; } } return f[u][0]; } inline void init() { for(register int j = 1;j <= lg[n];j++) { for(register int i = 1;i <= n;i++) { if(f[i][j-1] != -1) f[i][j] = f[f[i][j-1]][j-1]; } } } int main() { int x,y,a,b; n = read();m = read();s = read(); for(register int i = 1;i <= n;i++) { lg[i] = lg[i-1] + (1 << lg[i-1] + 1 == i); } for(register int i = 1;i <= n-1;i++) { x = read();y = read(); add(x,y);add(y,x); } dfs(s); init(); while(m--) { a = read();b = read(); printf("%d\n",lca(a,b)); } return 0; }
/* 这种树剖写法好理解(好背) 虽然代码比倍增略长 但是也比倍增快 简直完美2333333 所以以后就用这种方法辣 */ #include <bits/stdc++.h> using namespace std; const int maxn = 500005; int fa[maxn],top[maxn],id[maxn],son[maxn],depth[maxn],size[maxn];//树剖要用的所有数组 int n,m,s,head[maxn],cnt; struct node{ int to,pre; }G[maxn*2]; void addedge(int from,int to){ G[++cnt].to = to; G[cnt].pre = head[from]; head[from] = cnt; } void dfs1(int x){ size[x] = 1; for(int i = head[x];i;i = G[i].pre){ int cur = G[i].to; if(cur == fa[x]) continue; depth[cur] = depth[x] + 1; fa[cur] = x; dfs1(cur); size[x] += size[cur]; if(size[cur] > size[son[x]]) son[x] = cur; } } void dfs2(int x,int t){ top[x] = t; if(son[x]) dfs2(son[x],t); for(int i = head[x];i;i = G[i].pre){ int cur = G[i].to; if(cur != fa[x] && cur != son[x]) dfs2(cur,cur); } } int lca(int x,int y){ while(top[x] != top[y]){ if(depth[top[x]] < depth[top[y]]) swap(x,y); x = fa[top[x]]; } if(depth[x] > depth[y]) swap(x,y); return x; } int main(){ int x,y,a,b; scanf("%d%d%d",&n,&m,&s); for(int i = 1;i < n;i++){ scanf("%d%d",&x,&y); addedge(x,y);addedge(y,x); } dfs1(s); dfs2(s,s); while(m--){ scanf("%d%d",&a,&b); printf("%d\n",lca(a,b)); } return 0; }