题面
给出一个N节点,S为根的树,M次询问某两个节点间的LCA
N<=500000,M<=500000
分析
LCA的方法一般有倍增,tarjan,树链剖分,这里主要介绍树链剖分
这个题用vector的树链剖分会超时(常数原因)
vector的其他方法,开O2貌似能过
size[u]:以u为根节点的子树的节点数
dep[u]:u结点的深度,树根为0,往下依层递增
树链剖分是对树上的边按规则进行一些划分:
重边:节点与其重儿子(所有儿子中size最大的)所连边
轻边:节点与其非重儿子连边
重链:重边相连
轻链:轻边
经过规则,发现重链的dep一定是单调的,即不会有这样的重链:(粗边是重链)
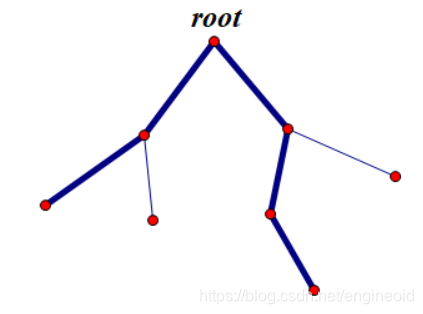
应当是这样的:
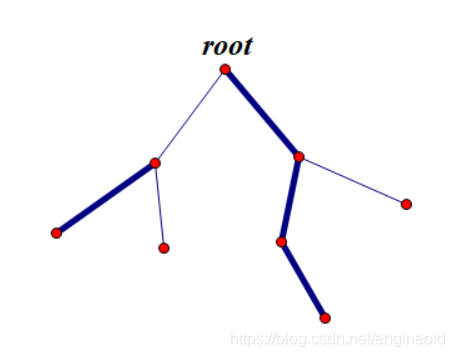
引入一个top[u],如果u在重链上,则top[u]能跳到这条重链上dep最小的那个点,对于轻链,会跳到自己头上。
这些构建完成后,树链剖分满足定理:从根到任意一个点,中间的重链数和轻链数均不会超过log n
在求LCA时,如果一个个节点跑,那么面对M次查询就会很差,甚至一次就需要N次计算。
但是树链剖分中,可以在重链上跳,就大大缩短了计算的次数,意思就是如果当前点处于一个重链上,可以直接跳到重链的top,直到两者的top相同(即处在同一条重链上/处于同一个轻边的同一个端点)
用fa数组进行迭代,fa[top[u]]即可不论轻重边一直跳。
中间过程都让深度更大的一个优先往上跳(浅的优先跳会跳的过多导致非“最近”公共祖先)
终止条件即两个点跳到了同一条重链上/一个轻点上,dep的单调性导致了两个不同重链之间至少有一个轻链,也就不会跳得太多
具体的过程需要两个dfs,第一次先标记出son,第二次连接起来这些son
代码
结构体存边版
#include "cstdlib"
#include "cstdio"
#include "iostream"
#include "vector"
using namespace std;
#define MAXN 500005
int dep[MAXN] , fa[MAXN] , son[ MAXN ] , size [ MAXN ] , top [ MAXN ];
#define cur v[i].t
struct edge
{
int t,nextt;
}v[MAXN<<1];
int last[MAXN];
void dfs1( int x )
{
size[x] = 1;
for(register int i = last[x] ; i ; i = v[i].nextt)
if(cur!=fa[x])
{
fa[cur]=x;dep[cur] = dep[x] + 1;
dfs1(cur);
size[x] += size[cur];
if( size[son[x]] < size[cur] )son[x] = cur;
}
}
void dfs2( int x , int t)
{
top[x] = t;
if(son[x])dfs2( son[x] , t );
for(register int i = last[x] ; i ; i = v[i].nextt)
if(cur!=fa[x]&&cur!=son[x])
dfs2(cur , cur);
}
inline int read()
{
register int x=0,ch=getchar();
while( !isdigit(ch))ch=getchar();
while(isdigit(ch))x = x * 10 + ch -'0' , ch=getchar();
return x;
}
int tot = 0;
inline void insert( int &from , int &to)
{
v[++tot].t = to;
v[tot].nextt = last[from];
last[from] = tot;
v[++tot].t = from;
v[tot].nextt = last[to];
last[to] = tot;
}
int main()
{
int n , m , s;
n=read();m=read();s=read();//结点个数、询问的个数和树根结点的序号
register int f , g;
for(register int i = 1 ; i < n ; i++)
{
f=read();
g=read();
insert( f , g );
}
dfs1(s);
dfs2(s ,s);
for(register int i = 0 ; i < m ; i++)
{
f=read();g=read();
while(top[f]!=top[g])
{
if(dep[top[f]]>dep[top[g]])f=fa[top[f]];
else g=fa[top[g]];
}
printf("%d\n",dep[f]<dep[g]?f:g);
}
return 0;
}
类封装+vector存边(不开O2 T3个点,开O2,T2个点)
#include<iostream>
#include<vector>
#include<algorithm>
using namespace std;
class Tree_Chain {
private:
const static int MAXN = 500005;
int siz[MAXN];//表示其子树的节点数
int fa[MAXN];//当前节点的父节点
int son[MAXN];//节点的重儿子
int top[MAXN];//重链顶
int dep[MAXN];//当前节点深
//int l[MAXN];//dfs序
std::vector<int>linker[MAXN];//存边
public:
int dfs_clock = 0;
void dfs1(int x)//x是当前节点(当前树根)
{
int cur;
siz[x] = 1;
for (int i = 0; i < linker[x].size(); i++)
{
cur = linker[x][i];
if (cur != fa[x]) //不是fa
{
dep[cur] = dep[x] + 1;//更新dep
fa[cur] = x;//更新fa
dfs1(cur);
siz[x] += siz[cur];//更新siz
if (siz[cur] > siz[son[x]])son[x] = cur;//更有可能成为重儿子
}
}
}
void dfs2(int x, int t)//当前节点x,当前重链顶的编号
{
//l[x] = ++dfs_clock;//更新dfs序
//a[dfs_clock] = b[x];//
top[x] = t;
if (son[x])dfs2(son[x], t);//继续连重链
int cur;
for (int i = 0; i < linker[x].size(); i++)
{
cur = linker[x][i];
if (cur != fa[x] && cur != son[x])//非父亲非重儿子
dfs2(cur, cur);//在其他儿子上重链
}
}
void insert(int &u, int &v)
{
linker[u].push_back(v);
linker[v].push_back(u);
}
int Lca(int &u, int &v)
{
while (top[u]!=top[v])
{
if (dep[top[u]] > dep[top[v]])u = fa[top[u]];
else v = fa[top[v]];
}
return dep[u] < dep[v] ? u : v;
}
}TC;
int main()
{
ios::sync_with_stdio(false);
int n, m, s, u, v;
cin >> n >> m >> s;
for (register int i = 1; i < n; i++)
{
cin >> u >> v;
TC.insert(u, v);
}
TC.dfs1(s);
TC.dfs2(s, s);
for (register int i = 0; i < m; i++)
{
cin >> u >> v;
cout << TC.Lca(u, v)<<endl;
}
return 0;
}
