901. 滑雪
题目描述
给定一个R行C列的矩阵,表示一个矩形网格滑雪场。
矩阵中第 i 行第 j 列的点表示滑雪场的第 i 行第 j 列区域的高度。
一个人从滑雪场中的某个区域内出发,每次可以向上下左右任意一个方向滑动一个单位距离。
当然,一个人能够滑动到某相邻区域的前提是该区域的高度低于自己目前所在区域的高度。
下面给出一个矩阵作为例子:
1 2 3 4 5
16 17 18 19 6
15 24 25 20 7
14 23 22 21 8
13 12 11 10 9
在给定矩阵中,一条可行的滑行轨迹为24-17-2-1。
在给定矩阵中,最长的滑行轨迹为25-24-23-…-3-2-1,沿途共经过25个区域。
现在给定你一个二维矩阵表示滑雪场各区域的高度,请你找出在该滑雪场中能够完成的最长滑雪轨迹,并输出其长度(可经过最大区域数)。
输入格式
第一行包含两个整数R和C。
接下来R行,每行包含C个整数,表示完整的二维矩阵。
输出格式
输出一个整数,表示可完成的最长滑雪长度。
数据范围
1≤R,C≤300,
0≤矩阵中整数≤10000
输入样例:
1 2 3 4 5
16 17 18 19 6
15 24 25 20 7
14 23 22 21 8
13 12 11 10 9
输出样例:
25
分析
深搜, 每个位置最多可以向4个方向滑,因此可以看做最多有4个分支的树,求某个点开始的递归长度即求以某个点作为根的最大树高度:
假设以某个点(x,y)为起点开始往下滑,它可以走四个方向,判断它的下一个位置是否合法:
- 下一个位置 是否 是墙
- 下一个位置的高度是否 严格低于 当前位置
满足条件就可进行一次递归,每递归走一次就是向一个方向滑一次,滑动长度+1。
递归不再嵌套递归而是往上返回进行的条件就是碰到了叶子结点,当所有可达的点都递归过后,就一次递归结束,取其中最大的树高作为当前的最远滑行距离。
因此每一个起点都可以得到一个最大滑行距离,共有n×m个起点,在n×m次深搜后,取某次的最大滑行距离即可。
时间复杂度较高。
代码实现
#include <iostream>
#include <cstring>
#define read(x) scanf("%d",&x)
using namespace std;
const int N=310;
int h[N][N];
int dx[4]={
0,0,-1,1},dy[4]={
1,-1,0,0};//表示上下左右四个方向
int n,m,res=0;//n行m列
void dfs(int x,int y,int len)
{
if (len>res) res=len;
for (int i=0;i<4;i++) {
int a=x+dx[i],b=y+dy[i];
if (a>=1 && a<=n && b>=1 && b<=m && h[a][b]<h[x][y]) dfs(a,b,len+1);
}
}
int main()
{
read(n),read(m);
for (int i=1;i<=n;i++)
for (int j=1;j<=m;j++) read(h[i][j]); //从下标1开始存储数据,下标0代表墙不可达
for (int i=1;i<=n;i++)
for (int j=1;j<=m;j++) dfs(i,j,1); "初始长度为1"
printf("%d",res);
return 0;
}
根据递归的书写,每次进入的位置都保证是合法的,因此可以先累加长度再进行递归。
从起点开始搜索的时候,起点已经作为长度中的一个点了,所以长度从1开始。
记忆化搜索
仍然是深搜,不过再维护一个记忆化数组dp,记录下每个点开始的最大滑行长度,检测该点四个方向的点,如果可以滑动到其他点的话,
dp[i][j] = max(dp[i][j-1], dp[i][j+1],dp[i-1][j],dp[i+1][j]) 上下左右四个方向
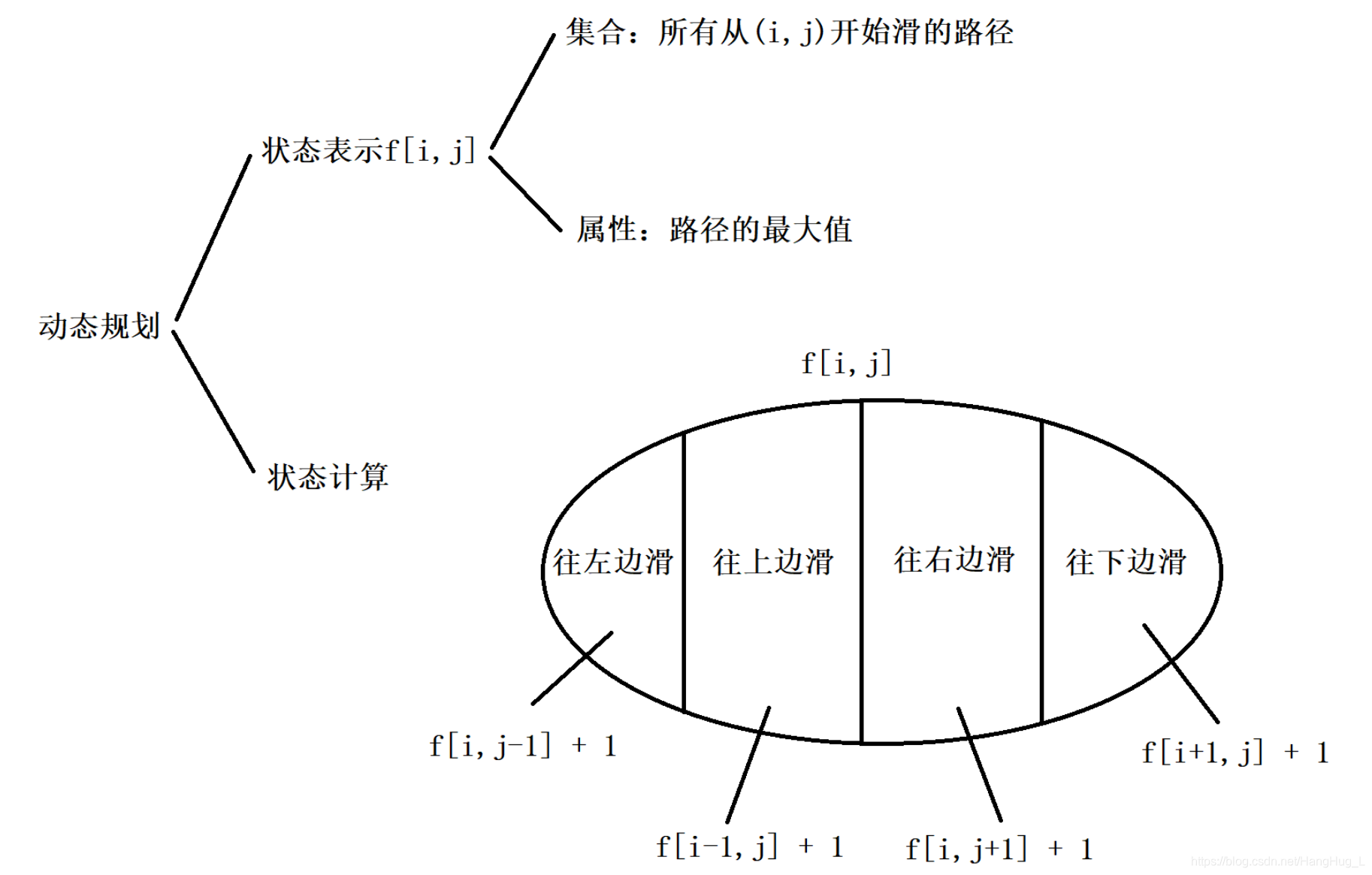
最后处理完后的dp二维数组的值一定是大于等于1的,因此初始化的时候初始化为-1,为-1时代表还没处理过,需要处理,否则就是处理过了,直接使用该值即可。
#include <iostream>
#include <cstring>
#define read(x) scanf("%d",&x)
using namespace std;
const int N=310;
int h[N][N],f[N][N];
int dx[4]={
0,0,-1,1},dy[4]={
1,-1,0,0};//表示上下左右四个方向
int n,m;//n行m列
int dp(int x,int y)
{
"保证进来的坐标(x,y)是合法的"
int &v=f[x][y]; v等价于f[x][y],共用同一块内存
if (v!=-1) return v; "说明v开始往下滑的情况已经计算过了,直接返回就行。"
v=1; 初始化为1, "否则,把当前点当作起点,v的值初始化为1,向四个方向滑"
for (int i=0;i<4;i++) {
int a=x+dx[i],b=y+dy[i];
"判断(a,b)是否合法"
if (a>=1 && a<=n && b>=1 && b<=m && h[a][b]<h[x][y])
v=max(v,dp(a,b)+1); "这里还要给v赋值,时刻更新,保证v的值是最大的"
}
return v;
}
int main()
{
read(n),read(m);
for (int i=1;i<=n;i++)
for (int j=1;j<=m;j++) read(h[i][j]); //从下标1开始存储数据,下标0代表墙不可达
memset(f,-1,sizeof f); "给数组f初始化为-1,f[i][j]==-1时表示该点还未进行处理"
把每个点都作为一次滑雪起点,挨个遍历
当前起点是肯定可以开始的,至于能不能往其它四个方向滑取决于周围的高度是不是比它低
所以起点处的长度肯定要算上,即f数组的最小值就为1,初始化res为0
int res=0;
for (int i=1;i<=n;i++)
for (int j=1;j<=m;j++) res=max(res,dp(i,j));
printf("%d",res);
return 0;
}
类似于并查集的处理套路,在用dp[i][j]的值的时候,如果它没有求解,就进行递归求解再使用,如果已经求解过了,就直接使用即可。
不过,当从点(i,j)作为结点,开始往下搜索时,由于4个方向,会最多更新4次dp[i][j],求出dp[i][j]的最大值,所以在求dp[i][j]的值时,可能会发生变化,需要取最大值,也是由其子树决定的,所以要写成v=max(v,dp(a,b)+1);,还要获得返回结果赋值。 当求出dp[i][j]的值后,他就固定了。
2021.03.13更
最近做题一直执着于记忆化搜索,发现都不对,思考哪里出现了问题。
-
在
d[i][j]的值没有记录前,它不会被任何需要它的点直接使用; -
当有点滑向(i,j)后,
如果d[i][j]的值没有记录,那么就会深搜dfs(i,j)深搜得出从(i,j)开始滑的最大长度d[i][j],在深搜过程中会涉及最多四个方向的更新,得出最大长度,之后d[i][j]的值就不会变了;
如果d[i][j]的值已经有记录了,那么就直接被使用,不再递归。 -
一旦
dfs(i,j)深搜得出从(i,j)开始滑的最大长度d[i][j]后,d[i][j]的值就不会变了,在此之后,d[i][j]的值可以被任何需要它的点直接使用。
该题目中,起点不止一个,在main函数中dfs(1,1) 可以得到以(1,1)起点的最大滑雪长度,同时也会更新所有从(1,1)可达的点的最大滑雪长度,同时这些点的最大滑雪长度也被固定下来了,不可能再被改变。
假如(1,1)为起点,(1,1)->(1,2)可达,计算
d[1,1]势必需要数据d[1,2],那么d[1,2]也被固定下来了,因为如果再计算(1,2)为起点求d[1,2]的话,他的思考方式和计算d[1,1]求d[1,2]的时候一样,而且他不可能经过(1,1),路径非降,所以刚才实际已经计算过了。
因此计算完d[1,1]后,从(1,1)开始所有可达的点(i,j)的d[i,j]都已经计算过了,由于是多起点,n*n个点都可能做起点,所以还要继续推算其它顶点的情况,如果是可达点,之前计算过,直接返回即可,如果没计算过,即还存在不可达点,那么再递归即可。
可见,求一个点的d[i][j]时,有最多4个方向,会更新d[i][j]的值,一点求出最大值后,它的值就不变了,供后人直接使用,此外,在求dp[i][j]时,它的所有子结点的d值都会求出来。
使用记忆化搜索的条件:
递归求出一个点的属性值后,他以后还会被用到,如果有些深搜过程每个点都只遍历一遍,递归求一次就结束了,就不用考虑记忆化搜索了,考虑剪枝优化。