第四章 存储器系统 Part 2
4.5 半导体随机存储器
4.5.1 分类
静态RAM(SRAM)
存储单位: 6个MOS管构成一个触发器, 存储1位二进制信息
问题: 存储密度低, 每块芯片的存储容量不会太大
速度优势
动态RAM(DRAM)
存储单位: 1个MOS管+1个电容, 存储1位二进制信息
问题: 电容会漏电, 需要频繁的刷新操作
优点: 存储密度大大提高
高集成度, 低功耗, 低成本
非易失性RAM(NV-RAM)
使用CMOS构成功耗极低的SRAM存储单元
使用智能控制电路, 智能地使用后备电源(锂电池)
4.6 半导体随机存储器芯片
4.6.0 概念
存储器组件: 把存储体及其外围电路(包括地址译码与驱动电路; 读写放大电路; 时序控制电路等)集成在一块硅片上
存储器芯片: 存储器组件经过封装, 通过引脚引出地址线; 数据线; 控制线; 电源; 地线等, 制成存储器芯片
4.6.1 字片式结构

单译码方式(一维译码) 64*8位
每个存储单元电路接出一根字线(e.g. W0)和两根位线(使用同一个读/写放大电路)
6位访存地址经地址译码器选中某一输出端有效时, 与其相联的8个存储单元电路同时进行读写.
所需译码驱动电路较多.
4.6.2 位片式结构
双译码方式(二维译码) 4K*1位
采用行列译码的方式, 位于选中的行和列交叉处的存储单元被唯一选中

行地址选中一行的64个存储单元电路进行读写
列地址用于选择64个多路转接开关, 控制各列是否能与读/写电路接通
此时只需128(26+26)个译码驱动电路, 采用单译码则需4096(212)个译码驱动电路
4.6.3 动态存储器的刷新
因为电容电荷的泄放会引起信息的丢失, 动态MOS存储器需要刷新
设存储电容为 C C C, 其两端电压为 u u u, 电荷 Q = C ⋅ u Q = C \cdot u Q=C⋅u, 则泄露电流为
I = Δ Q Δ t = C Δ u Δ t I = \frac{\Delta Q}{\Delta t}=C\frac{\Delta u}{\Delta t} I=ΔtΔQ=CΔtΔu
泄漏时间 Δ t = C Δ u I \Delta t = C \frac{\Delta u}{I} Δt=CIΔu, 也称作刷新最大周期(间隔)
动态存储器芯片的刷新均是按行刷新
刷新方式
当主存需要刷新时, CPU不能访存, 所以要尽可能让刷新时间少占用CPU时间
(1) 集中式刷新

按照存储器芯片容量的大小集中安排刷新操作的时间段,在此时间段内对芯片内所有的存储单元电路执行刷新操作(一次刷新一行)。
刷新一行的时间 = 存取周期
CPU的“死区”
在刷新操作期间,禁止CPU对存储器进行正常读/写的访问操作,称这段时间为CPU的“死区”。
优点: 控制简单, 存取周期不受刷新工作的影响
缺点: CPU利用率低
(2) 分散式刷新

一个存取周期用于对存储器的正常访问, 一个存取周期紧跟着就刷新
优点: 没有"死区", 每一系统周期都可进行读写操作
缺点: 没有充分利用刷新最大周期(间隔), 刷新过于频繁, 人为降低存储器速度
(3) 异步式刷新

充分利用刷新最大周期(间隔) – 常用
(4) 透明式刷新(隐含式刷新)
利用CPU不妨存操作时, 主存的空闲时间进行刷新
优点: 完全消除了"死区"
缺点: 较难控制何时进行刷新, 刷新控制电路复杂
4.7 半导体(随机)存储器的组成
一个存储器总是由一定数量的存储器芯片构成
所需芯片数量计算公式:
芯 片 总 片 数 = 存 储 器 总 单 元 数 × 位 数 / 单 元 每 片 芯 片 单 元 数 × 位 数 / 单 元 芯片总片数 = \frac{存储器总单元数\times位数/单元}{每片芯片单元数\times位数/单元} 芯片总片数=每片芯片单元数×位数/单元存储器总单元数×位数/单元
把芯片连接起来, 需要考虑地址, 数据, 控制信号线(CS RW…)
4.7.1 位拓展

4.7.2 字拓展

4.7.3 字位拓展
 先字拓展, 再位拓展
先字拓展, 再位拓展
4.7.4 地址分配与片选
线选法
将高位地址直接接到CS端

无需逻辑电路, 仅适用于芯片少的场合
全译码
将高位地址全部译码

范围确定, 连续, 无重叠存储区, 但对译码电路要求较高
部分译码
只将高位的一部分译码

选片只看A12~A0, 高位可以任意取,
存在重复地址, 但译码电路要求相对较低
4.7.5 整数边界存储
当计算机具有多种信息长度(8, 16, 32, 64)时, 为了保证数据都能在一个存储周期内存取完毕, 应当按存储周期的最大信息传输量为界传输信息.
若地址分配不合理, 会出现两个周期才将数据传送完毕的现象.
若下图, 使用空间换取时间的思想
8位(1字节): 地址最低为任意值, 16位: 地址最低位为0, 32位: 地址低两位为0, 64位: 地址低三位为0

熟练书P136例题, 能举一反三
4.8 半导体只读存储器
特点: 系统断电之后, 所存储内容不会丢失
用途:(1) 作为主存的一部分, 存放一些固定的程序(监控程序, 启动程序, 磁盘引导程序)(接通电源后就能自动运行)
(2) 控制存储器, 函数发生器, 代码转换器
(3) 输入/输出设备中, 用于存放字符, 汉字等点阵信息
分类
(1) 掩膜ROM
便宜, 用户不可编程(有错误就得全部扔掉)
(2) 可编程ROM(One Time Programmable ROM)(PROM)(OTPROM)
使用"ROM编程器"可将写入的信息烧入ROM
(3) 紫外线擦除ROM(Erasable Programmable ROM)(EPROM)(UV-EPROM) Ultraviolet
可用紫外线设备, 擦除整个芯片的内容, 耗时分钟级
(4) 电擦除PROM(Electrically Erasable Programmable ROM)(EEPROM)
可以瞬间, 有选择地电擦除具体字节单元内容
可直接在电路板上进行擦除, 要求设计擦除和编程电路
(5) 闪速存储器(Flash Memory)(‘U盘’)
闪烁电擦除可编程ROM
a. 成本高 b. 可擦写次数有限
4.9 闪速存储器
基本原理
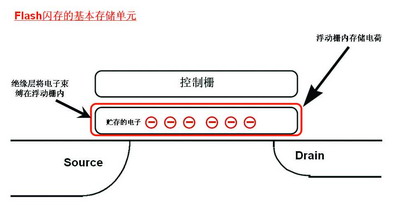
负电子在控制栅作用下注入浮动栅, 0状态
负电子从浮动栅中移走, 1状态
先全部移走(1状态), 然后碰到数据0才执行写入动作
特点
固有地非易失性, 廉价高密度, 可直接执行程序, 固态性能好
分类
NOR, 优势: 读取速度, 适合频繁随机读写
NAND, 优势: 写入速度, 寿命, (结构简单成本低容量大)
4.10 并行存储器
解决CPU速度和存储器速度匹配的四种方法
(1) 采用更高速的主存储器, 或加长存储器的字长
(2) 采用并行操作的双端口存储器
(3) 在每个存储器周期中存取几个字, 采用并行存储器
(4) 在CPU和主存储器中插入Cache
4.10.1 并行主存系统
单体多字并行主存系统
 适用于向量运算
适用于向量运算
多体交叉存取方式的并行主存系统

以n为模, 交叉存取, 采取分时访问的时序, 一个存储周期访存四次
需要一套存储器控制逻辑, 简称存控部件. 由操作系统或控制台开关设置, 确定主存的模式组合, 如: 所取模为多大, 读写时序, 校验处理等…
适合于支持流水线的处理方式, 多体交叉存储结构是高速大型计算机的典型主存结构
4.11 相联存储器
又称联想存储器(Associative Memory), 是根据所存信息的全部特征或部分特征进行存取的, 即一种按内容寻址的存储器

屏蔽寄存器: 目的是只选取为’1’位对应检索寄存器的位
符合寄存器: 若检索项和存储单元相应部分符合, 则将对应位置置1
存储体的每个单元都有一套比较电路, 最终产生使符合寄存器相应位置置1的信号
主要用途: (1) 虚拟存储器中存放分段表, 页表和快表 (2) 高速缓冲存储器中存放Cache的行地址
4.12 高速缓冲存储器Cache
4.12.1 简介
程序的局部性原理(Cache的设计理念): CPU所访问的存储器空间局限于某个区域
Cache对程序员是透明的
主存中的数据块称为"块block", Cache中的数据块称为"行line", “槽slot”
内容Cache = 数据Cache + 指令Cache
标识Cache: 块表, 一般由相联存储器组成, 用以记录主存内容存入Cache时两者地址的对应关系
4.12.2 性能指标
cache命中率
访问Cache的总命中次数为 N c N_c Nc, 访问主存次数为 N m N_m Nm, 命中率 H H H
H = N c N c + N m H = \frac{N_c}{N_c+N_m} H=Nc+NmNc
主存系统访问时间
T c T_c Tc为Cache的存取时间, T m T_m Tm为主存的存储周期, H H H为Cache命中率, T a T_a Ta为Cache-主存系统的平均访问时间
T a = H T c + ( 1 − H ) T m T_a = HT_c+(1-H)T_m Ta=HTc+(1−H)Tm
带Cache存储系统的加速比
S p = T m T a S_p = \frac{T_m}{T_a} Sp=TaTm
Cache-主存系统的访问效率e
e = T c T a e = \frac{T_c}{T_a} e=TaTc
4.12.3 Cache芯片
一级(L1)Cache: CPU芯片内部的高速缓冲寄存器
二级(L2)Cache: CPU外部由SRAM构成的高速缓冲存储器
4.13 Cache的地址映像方式
4.13.1 直接映像方式

主存地址 = 区号(n-m) + 区内块号(m) + 块内偏移量/块内地址
Cache地址 = Cache块号(m) + 块内偏移量/块内地址

特点: (1) 硬件线路简单 (2) 地址变换速度快 (3) 主存块在Cache块中位置固定, 没有替换策略问题 (4) 块的冲突率可能会高 (5) Cache利用率低
4.13.2 全相联映像

主存地址 : 主存块号(n) + 块内偏移量/块内地址
Cache地址: Cache块号(m) + 块内偏移量/块内地址

特点: (1) 块冲突概率小, Cache命中率高 (2) Cache利用率高 (3) 需要相联存储器实现相联访问, 需要替换策略 (4) 相联访问影响访问速度 (5) 成本高, Cache容量可能不够大
4.13.3 组相联映像
是直接映像和全相联映像的一种折中

主存地址 = 主存标识(n-g) + 组号(g) + 块内偏移量/块内地址
Cache地址 = Cache组号(g) + Cache组内块号(m-g) + 块内偏移量/块内地址

为了提高查块表的速度, 可将一Cache组中所有标识项同时读出
如果有对应标识且有效位为"1"----Cache命中
如果无对应标识或有效位为"0"----Cache不命中
4.14 Cache的替换算法与写策略
Cache容量比主存小得多, 替换的过程也称为Cache刷新
4.14.1 替换算法
FIFO(先进先出)
LRU(最近最久未使用 Least Recently Used)
方便, 一般使用LFU(最近最少使用 Least Frequently Used)
4.14.2 写策略
写直达法
数据被同时写入主存和Cache中
保证了内存中的内容总是最新的
增加了CPU占用系统总线的时间
写回法
CPU只将最新的数据写入Cache中, 但不写入内存
仅当Cache要替换数据时, 才由Cache控制器将Cache中被替换的数据写入内存
修改位(dirty bit), 为1表示数据被修改过, 在Cache中被替换时要写内存; 为0表示数据未被修改, 直接丢弃
在多处理器共享内存中的同一组数据时, 必须采取策略确保所有处理器用到的都是最新的数据