
文章信息

本周阅读的论文是一篇2021年发表在第34届Advances in Neural Information Processing Systems会议上的关于长时时间序列预测的文章,题目为《Autoformer: Decomposition Transformers with Auto-Correlation for Long-Term Series Forecasting》。

摘要

延长预测时间对于实际应用是一个关键需求,例如极端天气预警和长期能源消耗规划。这篇文章研究时间序列的长期预测问题。先前基于Transformer的模型采用各种自注意机制来发现远距离的依赖关系。然而,复杂的长期未来时间序列模式使得模型难以找到可靠的依赖关系。此外,为了提高长序列的效率,Transformers必须采用点对点自注意力的稀疏版本,导致信息利用瓶颈。为此,作者设计了Autoformer作为一种新颖的分解架构,具有自动相关性机制,打破了时间序列分解的预处理传统,将其改造为深度模型的基本内部块。这种设计赋予Autoformer对复杂时间序列的渐进分解能力。此外,受到随机过程理论的启发,作者设计了基于系列周期性的Auto-Correlation机制,它在子系列级别进行依赖关系的发现和表示聚合。Auto-Correlation在效率和准确性方面均优于自注意力。在长期预测方面,Autoformer在六个基准测试上取得了最先进的准确性,涵盖了五个实际应用领域:能源、交通、经济、天气和疾病,相对改进率达到了38%,证明了模型的可靠性。

引言

时间序列预测已广泛应用于能源消耗、交通和经济规划、天气和疾病传播预测。在这些实际应用中,一个迫切的需求是将预测时间延长到遥远的未来,这对长期规划和早期预警具有重要意义。因此,本文研究时间序列的长期预测问题,其特点是预测时间序列的长度较大。
得益于自注意力机制,transformer在为顺序数据建模长期依赖关系方面获得了很大的优势,这使得更强大的大模型成为可能。然而,在长期背景下,预测任务极具挑战性。首先,直接从长期时间序列中发现时间依赖关系是不可靠的,因为这些依赖关系可能被纠缠的时间模式所掩盖。其次,由于序列长度的二次复杂度,具有自关注机制的典型变形器在计算上不适合长期预测。以前基于transformer的预测模型主要侧重于将自关注提高到稀疏版本。虽然性能得到了显著提高,但这些模型仍然使用逐点表示聚合。因此,在提高效率的过程中,会因为稀疏的逐点连接而牺牲信息利用率,造成时间序列长期预测的瓶颈。
为了对复杂的时间模式进行推理,作者尝试采用分解的思想,并提出一个原始的Autoformer来代替Transformer进行长期时间序列预测。Autoformer仍然沿用残差和编解码器结构,但将Transformer改造为分解预测结构。通过嵌入提出的分解块作为内部操作符,Autoformer可以逐步从预测的隐藏变量中分离出长期趋势信息。这种设计允许模型在预测过程中交替分解和改进中间结果。同时,Autoformer引入了一种自相关机制来代替自注意力机制,该机制基于序列的周期性发现子序列的相似性,并从底层周期中聚合相似的子序列。对于长度为L的序列,这种机制取得了O(LlogL)的计算复杂度并打破了信息使用瓶颈。文章的主要贡献如下所示:
(1)为了处理长期未来复杂的时间模式,作者提出了Autoformer作为分解架构,并设计了内部分解块,使深度预测模型具有内在的渐进分解能力。
(2)作者提出了一种具有序列级依赖关系发现和信息聚合的自相关机制,该机制超越了以往的自注意力家族,可以同时提高计算效率和信息利用率。
(3)与其他6个基准模型相比,Autoformer实现了38%的相对改进,涵盖了五个现实世界的应用:能源、交通、经济、天气和疾病。

模型

长时时间序列预测的困难为:处理复杂的时间模式,突破计算效率和信息利用的瓶颈。为了解决这两个挑战,作者将分解作为内置块引入深度预测模型,并提出Autoformer作为分解体系结构。另外,作者设计了Auto-Correlation发掘基于周期的依赖关系,并从底层周期中聚合相似的子序列。
4.1分解架构
文章将Transformer更新为一个深度分解结构(图一所示),包括内在序列分解架构,自相关性机制以及相关的编码器和解码器。
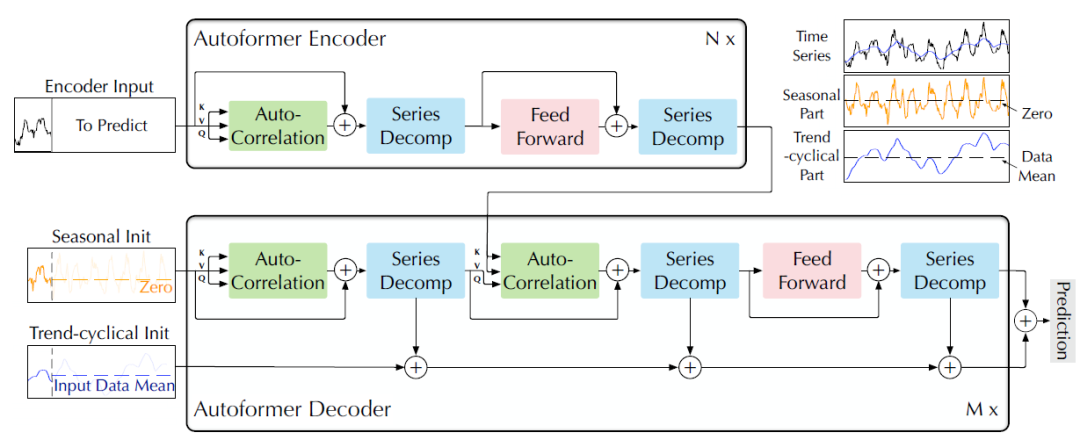
图1 Autoformer架构
(1)序列分解模块
文章采取分解的思想学习长时预测情景下的复杂时间模式,将时间序列分解为趋势循环和季节性部分,分别反映了该序列数据的长期性和季节性。然而,对于未来序列,直接分解是无法实现的,因为未来就是未知的。为此,文章提出一个序列分解块作为Autoformer的内部操作,可以从预测的中间隐藏变量中逐步提取长期平稳趋势。具体地说,通过调整移动平均线来平滑周期性波动,突出长期趋势。对于长度为L的输入序列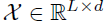 ,分解过程如下:
,分解过程如下:
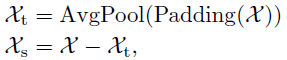
其中,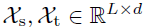 表示为季节性部分和提取的趋势周期部分。作者使用AvgPool实现移动平均,并进行填充操作,以保持序列长度不变。使用
表示为季节性部分和提取的趋势周期部分。作者使用AvgPool实现移动平均,并进行填充操作,以保持序列长度不变。使用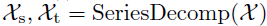 概况上面的过程。
概况上面的过程。
(2)模型输入
编码器的输入是过去I个时间步的序列数据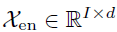 。作为一个分解架构,Autoformer的解码器部分的输入包括季节性部分
。作为一个分解架构,Autoformer的解码器部分的输入包括季节性部分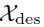 和趋势循环部分
和趋势循环部分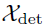 。每个初始化包括两个部分:从编码器的输入分解出的长度为的后半部分用于提供近期信息以及由标量填充的长度为O的占位符,表示如下:
。每个初始化包括两个部分:从编码器的输入分解出的长度为的后半部分用于提供近期信息以及由标量填充的长度为O的占位符,表示如下:
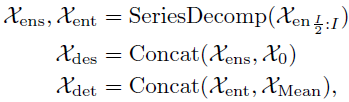
其中,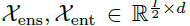 表示
表示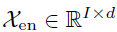 的季节性和趋势循环部分,
的季节性和趋势循环部分,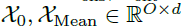 分别表示用0值和输入均值填充的展位符。
分别表示用0值和输入均值填充的展位符。
(3)编码器
如图1所示,编码器主要用于季节性部分的建模。编码器的输出包括历史季节性信息,将作为互信息帮助解码器增强预测结果。假设具有N层编码器,第l层编码层可以总结为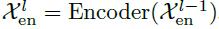 ,具体细节如下所示:
,具体细节如下所示:

其中,“_”表示消除的趋势部分,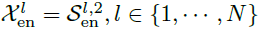 表示第l层编码器的输出,
表示第l层编码器的输出,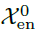 表示经过嵌入的
表示经过嵌入的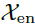 。
。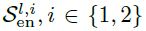 分别表示第l层中经过i个序列分解模块后获得的季节性部分。Auto-Correlation表示自相关性机制,下文对其展开具体介绍。
分别表示第l层中经过i个序列分解模块后获得的季节性部分。Auto-Correlation表示自相关性机制,下文对其展开具体介绍。
(4)解码器
解码器包含两个部分,趋势周期分量的累积结构和季节性分量的叠加自相关机制。每个解码层包含内在的自相关性和编码-解码自相关性,分别用于增强预测结果和充分使用过去的季节性信息。需要注意的是,该模型在解码器期间从中间隐藏变量中提取潜在趋势,允许Autoformer逐步改进趋势预测并消除干扰信息,以便在自相关中发现基于周期的依赖关系。假设M层解码层,第l层解码层计算过程如下所示。

其中,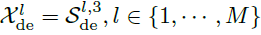 表示第l层解码层的输出。
表示第l层解码层的输出。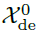 由
由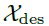 进行嵌入操作获得,
进行嵌入操作获得,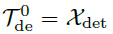 用于加速。
用于加速。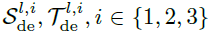 表示分别经过第l层解码层中第i个序列分解模块处理后的季节性部分和趋势循环部分。
表示分别经过第l层解码层中第i个序列分解模块处理后的季节性部分和趋势循环部分。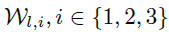 表示第i个提取趋势
表示第i个提取趋势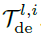 的权重。最终的预测是两个增强党的分解成分的求和,表示为
的权重。最终的预测是两个增强党的分解成分的求和,表示为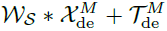 ,其中
,其中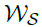 用于将深度转换的季节性成分
用于将深度转换的季节性成分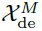 转换至目标维度。
转换至目标维度。
4.2自相关机制
如图2所示,本文提出自相关性机制以扩大信息利用率。自相关机制通过计算序列自相关来发现基于周期的依赖关系,并通过时间延迟聚合来聚合相似的子序列。
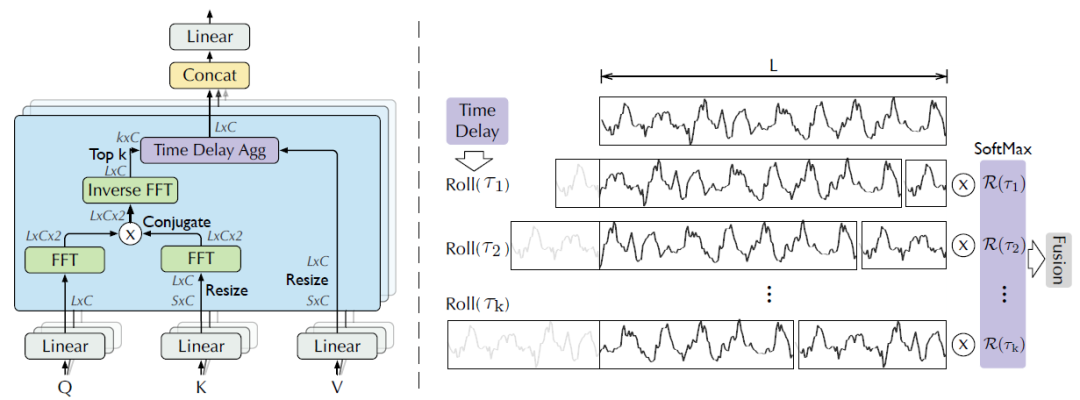
图2 自相关性与时间延迟聚合
(1)周期依赖性
周期之间相同的相位位置自然会产生相似的子过程。对于一个实际的离散时间序列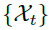 ,可以通过一下公式获得自相关性
,可以通过一下公式获得自相关性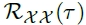 。
。
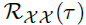 表示了离散时间序列
表示了离散时间序列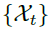 和其滞后序列
和其滞后序列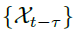 的时间延时相似性。如图2所示,使用自相关性
的时间延时相似性。如图2所示,使用自相关性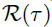 作为为估计周期长度为的非归一化置信度。接着,作者选择最可能的k个周期长度
作为为估计周期长度为的非归一化置信度。接着,作者选择最可能的k个周期长度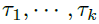 。基于周期的依赖关系由上述估计的周期导出,并可以通过相应的自相关来加权。
。基于周期的依赖关系由上述估计的周期导出,并可以通过相应的自相关来加权。
(2)时间延迟聚合
基于周期的依赖关系将估计周期之间的子序列连接起来。因此,作者提出时间延迟聚合模块,它可以根据选择的时间延迟滚动序列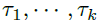 。该操作不同于自注意力机制中逐点的点积聚合,可以对处于估计周期同一相位位置的相似子序列进行对齐。最后,通过Softmax归一化置信度对子序列进行聚合。对于单头情况和时间序列长度为l的时间序列X,在经过映射后,获得查询向量Q、键值向量K以及值向量V。因此,可以有效取代自注意力机制。自相关性机制表示如下:
。该操作不同于自注意力机制中逐点的点积聚合,可以对处于估计周期同一相位位置的相似子序列进行对齐。最后,通过Softmax归一化置信度对子序列进行聚合。对于单头情况和时间序列长度为l的时间序列X,在经过映射后,获得查询向量Q、键值向量K以及值向量V。因此,可以有效取代自注意力机制。自相关性机制表示如下:
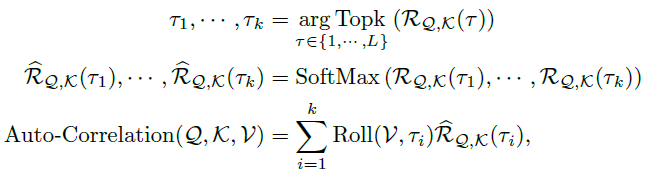
其中,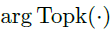 用于获取TopK个自相关性的参数,且
用于获取TopK个自相关性的参数,且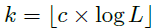 ,c是一个超参数。
,c是一个超参数。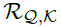 表示序列Q和K间的自相关性。
表示序列Q和K间的自相关性。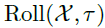 表示对序列X进行滚动操作,时间步为,在此期间,移到第一个位置以外的元素将在最后一个位置重新引入。对于编码-解码自相关性,K和V来自编码器的
表示对序列X进行滚动操作,时间步为,在此期间,移到第一个位置以外的元素将在最后一个位置重新引入。对于编码-解码自相关性,K和V来自编码器的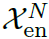 ,Q来自解码器先前的模块。对于多头版本的Autoformer,假设具有
,Q来自解码器先前的模块。对于多头版本的Autoformer,假设具有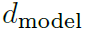 通道的隐藏变量和h个多头,第i个多头的查询、键值和值向量分别是
通道的隐藏变量和h个多头,第i个多头的查询、键值和值向量分别是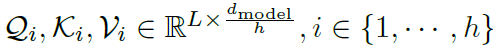 。具体过程如下:
。具体过程如下:
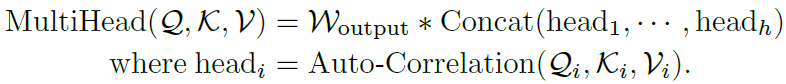
(3)自相关性和自注意力机制
不同于驻点自注意力机制,自相关性关注序列级的关联性(图3)。具体地说,对于时间依赖性,作者基于周期性找到子序列之间的相关性。相反,自注意力机制只关注散点之间的关系。尽管部分自注意力机制考虑到局部信息,但他们只利用这些注意力机制挖掘逐点间的依赖性。在信息聚合方面,作者采用延时聚合块对底层周期的相似子序列进行聚合。相反,自关注通过点积将选择的点聚集起来。得益于其固有的稀疏性和子序列级表示聚合,自相关可以同时提高计算效率和信息利用率。
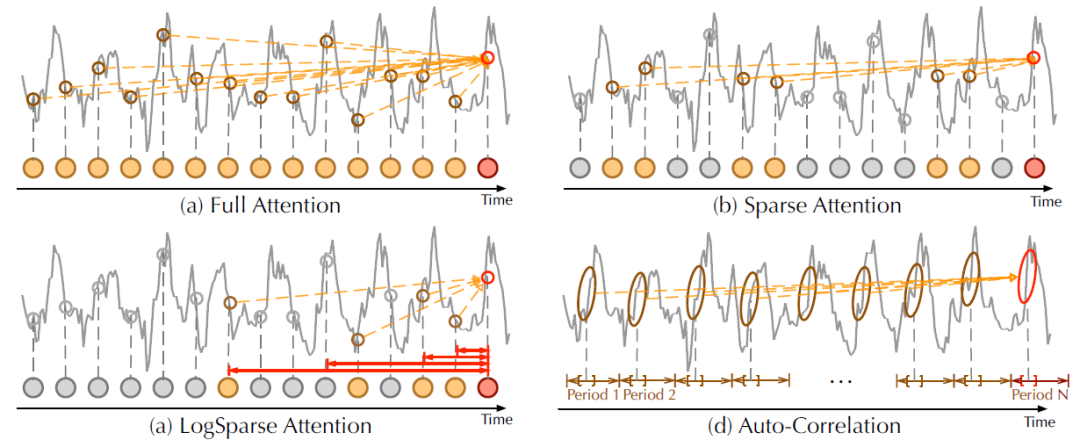
图3 自相关性与自注意力机制

实验

实验部分,作者在六个现实世界的基准上广泛评估了提出的自耦器,涵盖了五个主流时间序列预测应用:能源,交通,经济,天气和疾病。具体数据集介绍以及模型实现细节读者可以翻阅原文查看,此处不展开叙述。作者选择了10个基线模型。对于多变量设置,作者选择了三个最新的基于Transformer模型:Informer,Reformer以及LogTrans,两个基于RNN的模型:LSTNet,LSTM以及TCN。对于单变量设置,作者选择了以下几个基准模型:N-BEATS,DeepAR,Prophet以及ARIMA。
5.1主要结果
为了比较不同未来时间步下的表现,作者固定了输入长度,并评估模型在广泛预测长度范围的模型:96、192、336、720。以下是多变量和单变量设置结果。
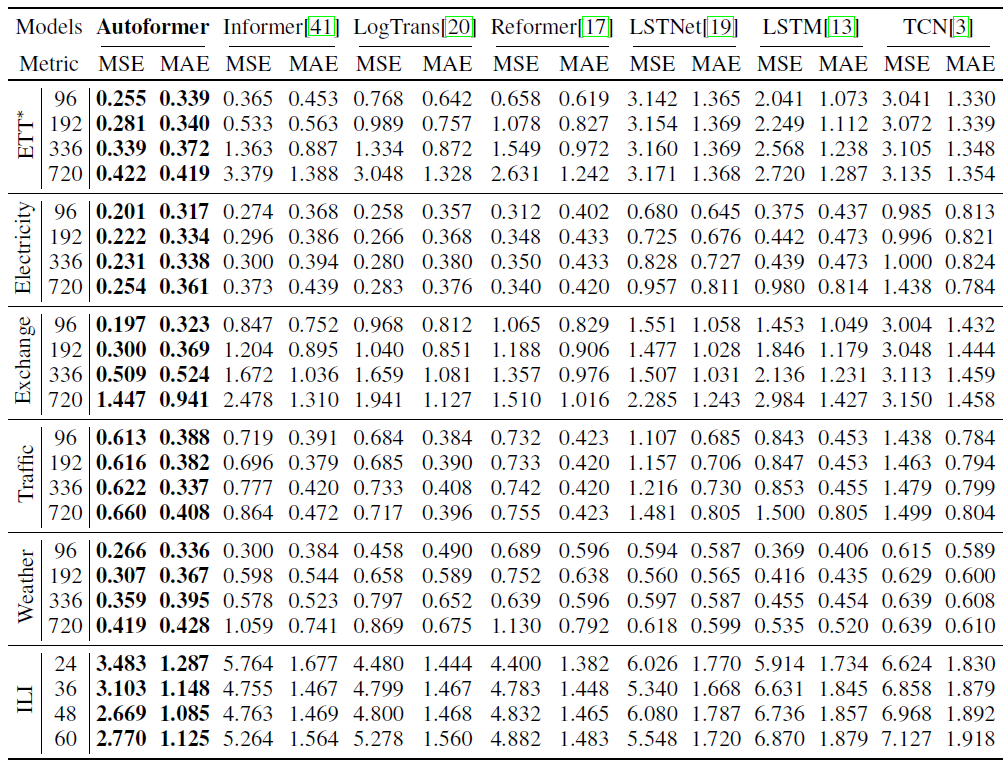
(1)多变量结果
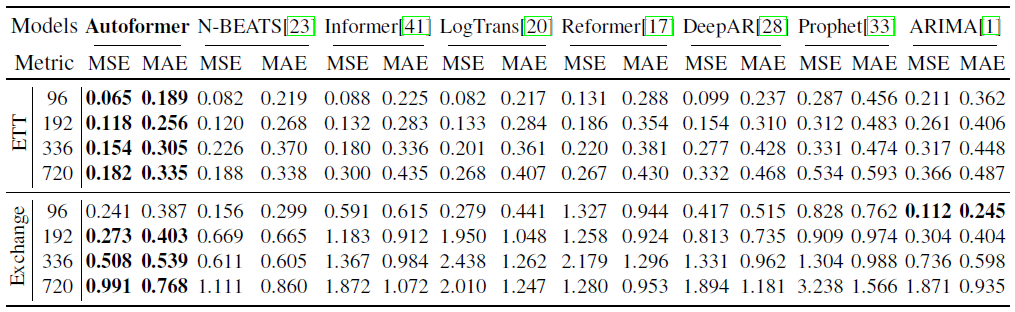
如表一所示,对于多变量设置,Autoformer在所有基准测试和所有预测长度设置中实现了一致的最先进性能。Autoformer在所有数据集上的平均MSE相比其他基线模型取得了38%的降低。另外,随着预测长度O的增加,Autoformer预测性能的变化十分稳定,意味着Autoformer保持了更好的长期鲁棒性,这对于现实世界的实际应用,如天气预警和长期能源消耗规划是有意义的。
表1 不同预测长度的多元结果
(2)单变量结果
表2中列出了两个典型数据集中单变量模型的预测结果。与广泛的基线相比,Autoformer在长期预测任务中仍然具有最先进的性能。
表2 不同预测长度下的单变量结果
5.2消融实验
(1)分解架构
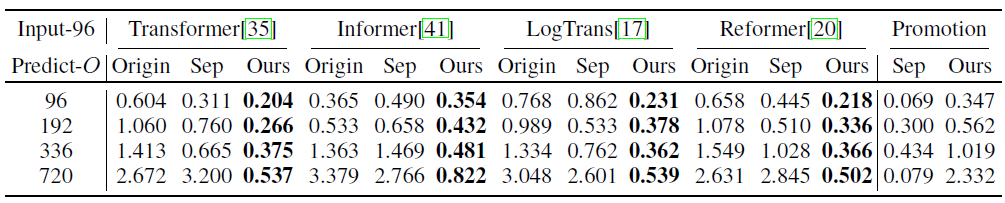
如表3所示,使用文章提出的渐进式分解体系结构,其他模型可以获得一致的提升,特别是当预测长度O增加时,实验结果证明文章提出的架构可以推广到其他模型,释放其他依赖学习机制的能力,减轻复杂模式带来的分心。此外,本文的架构优于预处理,尽管后者使用更大的模型和更多的参数。
表3 多元ETT的分解消融实验(MSE度量)
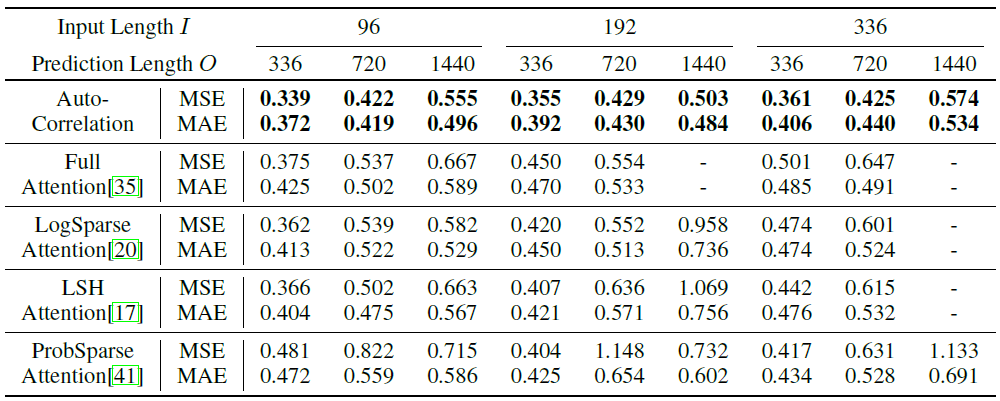
(2)自相关性与自注意力机制
如表4所示,自相关性取得了最优的预测结果,证明了序列级连接相较于逐点自注意力的有效性。另外,从表4的最后一列观察到自相关性具有高效的内存计算,可以用于长序列预测。
表4 自相关性与自注意力机制比较
5.3模型分析
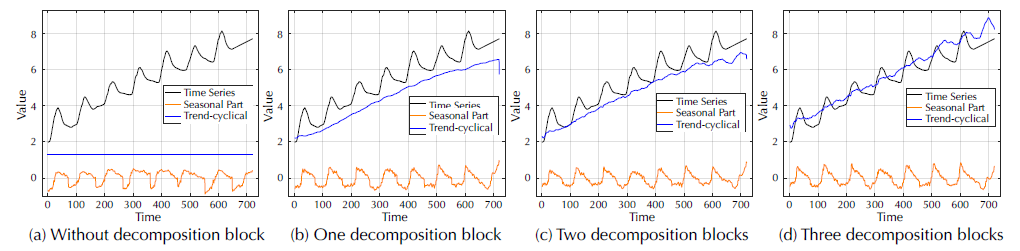
(1)时间序列分解
如图4所示,如果没有序列分解块,预测模型无法捕捉到季节部分的增长趋势和峰值。通过添加序列分解块,Autoformer可以从序列中逐步汇总和细化趋势周期部分。这样的设计也有利于季节性部分的学习,尤其是高峰和低谷。这验证了作者提出的渐进式分解体系结构的必要性。
图4 可视化解码器中学习到的季节性与趋势循环部分
(2)依赖性学习
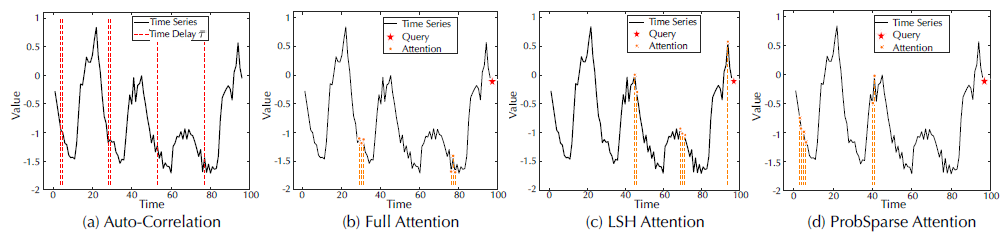
图5(a)中标记的时间延迟大小表示最可能出现的时间段。学习到的周期性可以指导模型聚合相同或邻域相位的子序列。对于最后一个时间步(下降阶段),自相关性充分利用了所有相似的子序列,与自注意力机制相比没有遗漏和误差。这证明Autoformer可以更有效率和精度的挖掘相关信息。
图5 可视化学习到的依赖性
(3)复杂季节性建模
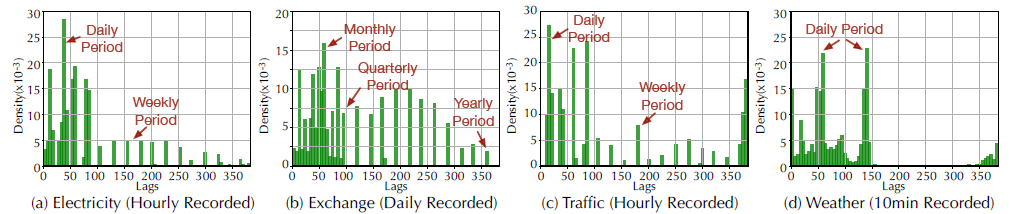
如图6所示,Autoformer从深度表征中学习到的滞后可以表明原始序列的真实季节性。例如,对于每小时记录的交通数据集(图6 (c)),学习滞后显示间隔为24小时和168小时,这与现实世界场景的每日和每周周期相匹配。这些结果表明,Autoformer可以从深度表征中捕获现实世界序列的复杂季节性,并进一步提供可解释的预测。
图6 学习滞后的统计
(4)有效性分析
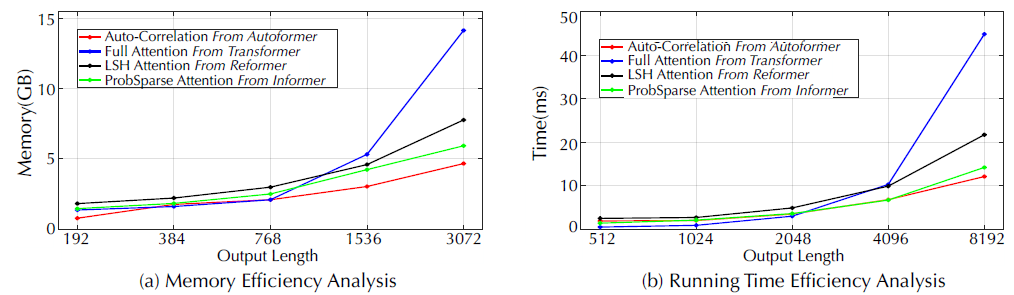
作者在训练阶段比较了基于Auto - Correlation和基于self-attention的模型的运行内存和时间(图7)。提出的模型Autoformer模型在记忆和时间上取得了O(LlogL)的复杂度,并且取得了更好的长时训练效率。
图7 效率分析

结论

本文研究了时间序列的长期预测问题,这是现实应用中迫切需要的问题。然而,复杂的时间模式阻止了模型学习可靠的依赖关系。通过将序列分解块嵌入到内部算子中,作者提出了一种分解体系结构Autoformer,它可以从中间预测中逐步聚合长期趋势部分。此外,作者设计了一种高效的自相关机制,在序列层面上进行依赖项发现和信息聚合,这与之前的自注意力机制形成了明显的对比。Autoformer可以取得O(LlogL)的计算复杂度,且在广泛的现实世界数据集中取得最先进的性能。